

Baker University has disclosed a data breach after attackers gained access to its network one year ago and stole the personal, health, and financial information of over 53,000 individuals. […] Read More
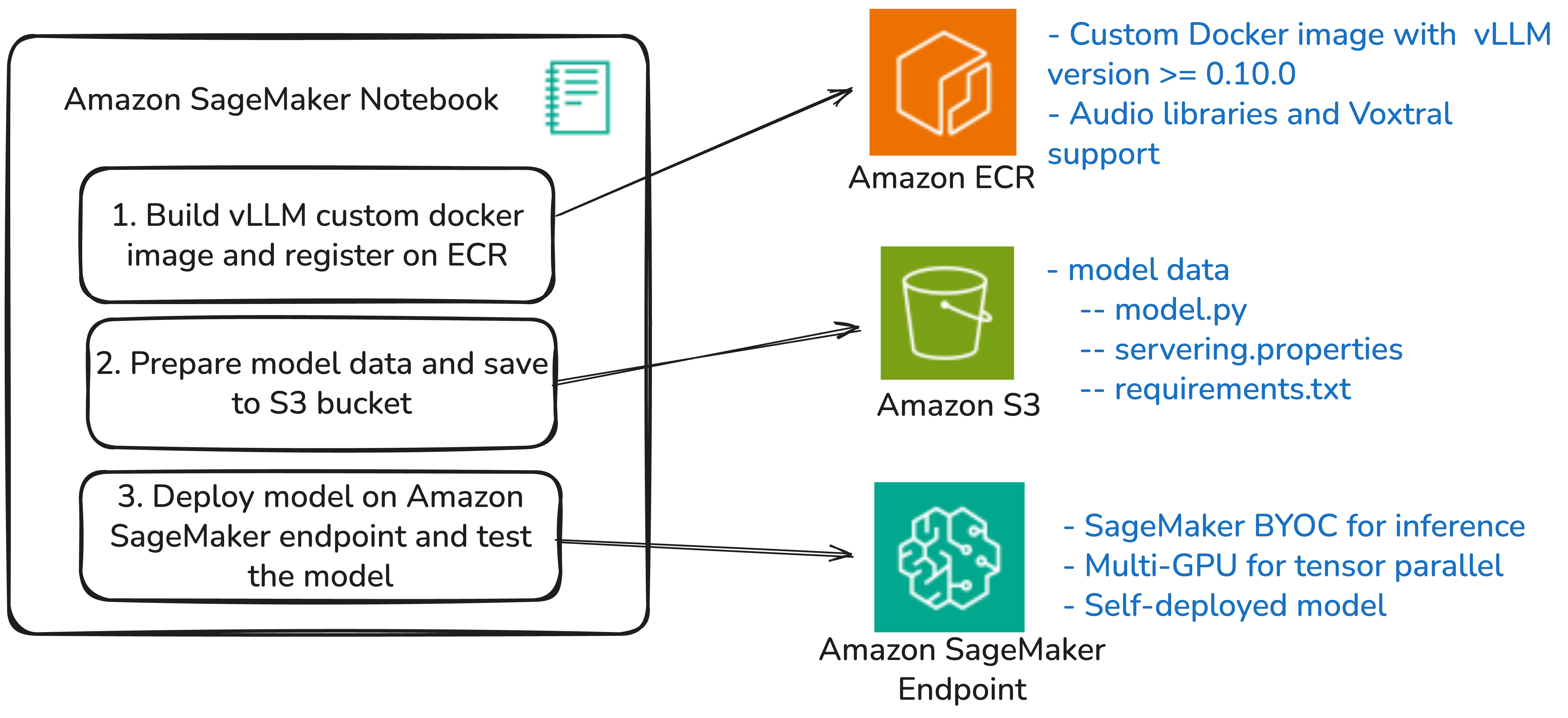
Deploy Mistral AI’s Voxtral on Amazon SageMaker AIArtificial Intelligence In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs.
In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs. Read More

A critical security vulnerability has been disclosed in the n8n workflow automation platform that, if successfully exploited, could result in arbitrary code execution under certain circumstances. The vulnerability, tracked as CVE-2025-68613, carries a CVSS score of 9.9 out of a maximum of 10.0. The package has about 57,000 weekly downloads, according to statistics on npm. […]
Passwd is designed specifically for organizations operating within Google Workspace. Rather than competing as a general consumer password manager, its purpose is narrow, and business-focused: secure credential storage, controlled sharing, and seamless Workspace integration. The platform emphasizes practicality over feature overload, aiming to provide a reliable system for teams that already rely Read More

Arm and the future of AI at the edgeAI News Arm Holdings has positioned itself at the centre of AI transformation. In a wide-ranging podcast interview, Vince Jesaitis, head of global government affairs at Arm, offered enterprise decision-makers look into the company’s international strategy, the evolution of AI as the company sees it, and what lies ahead for the industry. From cloud to edge Arm
The post Arm and the future of AI at the edge appeared first on AI News.
Arm Holdings has positioned itself at the centre of AI transformation. In a wide-ranging podcast interview, Vince Jesaitis, head of global government affairs at Arm, offered enterprise decision-makers look into the company’s international strategy, the evolution of AI as the company sees it, and what lies ahead for the industry. From cloud to edge Arm
The post Arm and the future of AI at the edge appeared first on AI News. Read More

An Agentic AI Framework for Training General Practitioner Student Skillscs.AI updates on arXiv.org arXiv:2512.18440v1 Announce Type: cross
Abstract: Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools.
arXiv:2512.18440v1 Announce Type: cross
Abstract: Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools. Read More

The French national postal service’s online services were knocked offline by “a major network incident” on Monday, disrupting digital banking and other services for millions. […] Read More

The U.S. Justice Department (DoJ) on Monday announced the seizure of a web domain and database that it said was used to further a criminal scheme designed to target and defraud Americans by means of bank account takeover fraud. The domain in question, web3adspanels[.]org, was used as a backend web panel to host and manipulate […]

Italy’s competition authority (AGCM) has fined Apple €98.6 million ($116 million) for using the App Tracking Transparency (ATT) privacy framework to abuse its dominant market position in mobile app advertising. […] Read More
The Erasure Illusion: Stress-Testing the Generalization of LLM Forgetting Evaluationcs.AI updates on arXiv.org arXiv:2512.19025v1 Announce Type: cross
Abstract: Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model’s performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning–motivated by copyright or safety–implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have “forgotten” the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose name, an automated stress-testing framework that generates a surrogate dataset, $tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$beta$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets.
arXiv:2512.19025v1 Announce Type: cross
Abstract: Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model’s performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning–motivated by copyright or safety–implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have “forgotten” the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose name, an automated stress-testing framework that generates a surrogate dataset, $tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$beta$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets. Read More
