
A Gentle Introduction to MCP Servers and ClientsKDnuggets Get a gentle introduction to the standard that defines how artificial intelligence systems connect with the outside world.
Get a gentle introduction to the standard that defines how artificial intelligence systems connect with the outside world. Read More

What Makes a Language Look Like Itself?Towards Data Science How simple statistics reveal the visual fingerprints of 20 languages
The post What Makes a Language Look Like Itself? appeared first on Towards Data Science.
How simple statistics reveal the visual fingerprints of 20 languages
The post What Makes a Language Look Like Itself? appeared first on Towards Data Science. Read More
Uncovering Vulnerabilities of LLM-Assisted Cyber Threat Intelligencecs.AI updates on arXiv.org arXiv:2509.23573v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research.
arXiv:2509.23573v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research. Read More
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generationcs.AI updates on arXiv.org arXiv:2510.00485v1 Announce Type: cross
Abstract: Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models’ understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on “Content” and “Format”. 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
arXiv:2510.00485v1 Announce Type: cross
Abstract: Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models’ understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on “Content” and “Format”. 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval. Read More
Privacy-Preserving Learning-Augmented Data Structurescs.AI updates on arXiv.org arXiv:2510.00165v1 Announce Type: cross
Abstract: Learning-augmented data structures use predicted frequency estimates to retrieve frequently occurring database elements faster than standard data structures. Recent work has developed data structures that optimally exploit these frequency estimates while maintaining robustness to adversarial prediction errors. However, the privacy and security implications of this setting remain largely unexplored.
In the event of a security breach, data structures should reveal minimal information beyond their current contents. This is even more crucial for learning-augmented data structures, whose layout adapts to the data. A data structure is history independent if its memory representation reveals no information about past operations except what is inferred from its current contents. In this work, we take the first step towards privacy and security guarantees in this setting by proposing the first learning-augmented data structure that is strongly history independent, robust, and supports dynamic updates.
To achieve this, we introduce two techniques: thresholding, which automatically makes any learning-augmented data structure robust, and pairing, a simple technique that provides strong history independence in the dynamic setting. Our experimental results demonstrate a tradeoff between security and efficiency but are still competitive with the state of the art.
arXiv:2510.00165v1 Announce Type: cross
Abstract: Learning-augmented data structures use predicted frequency estimates to retrieve frequently occurring database elements faster than standard data structures. Recent work has developed data structures that optimally exploit these frequency estimates while maintaining robustness to adversarial prediction errors. However, the privacy and security implications of this setting remain largely unexplored.
In the event of a security breach, data structures should reveal minimal information beyond their current contents. This is even more crucial for learning-augmented data structures, whose layout adapts to the data. A data structure is history independent if its memory representation reveals no information about past operations except what is inferred from its current contents. In this work, we take the first step towards privacy and security guarantees in this setting by proposing the first learning-augmented data structure that is strongly history independent, robust, and supports dynamic updates.
To achieve this, we introduce two techniques: thresholding, which automatically makes any learning-augmented data structure robust, and pairing, a simple technique that provides strong history independence in the dynamic setting. Our experimental results demonstrate a tradeoff between security and efficiency but are still competitive with the state of the art. Read More
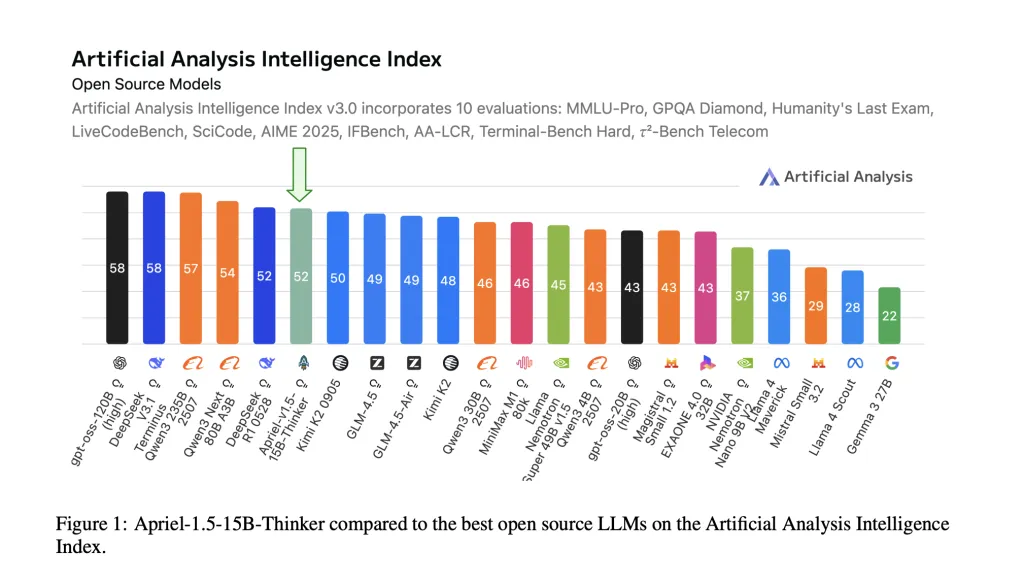
ServiceNow AI Releases Apriel-1.5-15B-Thinker: An Open-Weights Multimodal Reasoning Model that Hits Frontier-Level Performance on a Single-GPU BudgetMarkTechPost ServiceNow AI Research Lab has released Apriel-1.5-15B-Thinker, a 15-billion-parameter open-weights multimodal reasoning model trained with a data-centric mid-training recipe—continual pretraining followed by supervised fine-tuning—without reinforcement learning or preference optimization. The model attains an Artificial Analysis Intelligence Index score of 52 with 8x cost savings compared to SOTA. The checkpoint ships under an MIT license on
The post ServiceNow AI Releases Apriel-1.5-15B-Thinker: An Open-Weights Multimodal Reasoning Model that Hits Frontier-Level Performance on a Single-GPU Budget appeared first on MarkTechPost.
ServiceNow AI Research Lab has released Apriel-1.5-15B-Thinker, a 15-billion-parameter open-weights multimodal reasoning model trained with a data-centric mid-training recipe—continual pretraining followed by supervised fine-tuning—without reinforcement learning or preference optimization. The model attains an Artificial Analysis Intelligence Index score of 52 with 8x cost savings compared to SOTA. The checkpoint ships under an MIT license on
The post ServiceNow AI Releases Apriel-1.5-15B-Thinker: An Open-Weights Multimodal Reasoning Model that Hits Frontier-Level Performance on a Single-GPU Budget appeared first on MarkTechPost. Read More
TASER: Translation Assessment via Systematic Evaluation and Reasoningcs.AI updates on arXiv.org arXiv:2510.00255v1 Announce Type: cross
Abstract: We introduce TASER (Translation Assessment via Systematic Evaluation and Reasoning), a metric that uses Large Reasoning Models (LRMs) for automated translation quality assessment. TASER harnesses the explicit reasoning capabilities of LRMs to conduct systematic, step-by-step evaluation of translation quality. We evaluate TASER on the WMT24 Metrics Shared Task across both reference-based and reference-free scenarios, demonstrating state-of-the-art performance. In system-level evaluation, TASER achieves the highest soft pairwise accuracy in both reference-based and reference-free settings, outperforming all existing metrics. At the segment level, TASER maintains competitive performance with our reference-free variant ranking as the top-performing metric among all reference-free approaches. Our experiments reveal that structured prompting templates yield superior results with LRMs compared to the open-ended approaches that proved optimal for traditional LLMs. We evaluate o3, a large reasoning model from OpenAI, with varying reasoning efforts, providing insights into the relationship between reasoning depth and evaluation quality. The explicit reasoning process in LRMs offers interpretability and visibility, addressing a key limitation of existing automated metrics. Our results demonstrate that Large Reasoning Models show a measurable advancement in translation quality assessment, combining improved accuracy with transparent evaluation across diverse language pairs.
arXiv:2510.00255v1 Announce Type: cross
Abstract: We introduce TASER (Translation Assessment via Systematic Evaluation and Reasoning), a metric that uses Large Reasoning Models (LRMs) for automated translation quality assessment. TASER harnesses the explicit reasoning capabilities of LRMs to conduct systematic, step-by-step evaluation of translation quality. We evaluate TASER on the WMT24 Metrics Shared Task across both reference-based and reference-free scenarios, demonstrating state-of-the-art performance. In system-level evaluation, TASER achieves the highest soft pairwise accuracy in both reference-based and reference-free settings, outperforming all existing metrics. At the segment level, TASER maintains competitive performance with our reference-free variant ranking as the top-performing metric among all reference-free approaches. Our experiments reveal that structured prompting templates yield superior results with LRMs compared to the open-ended approaches that proved optimal for traditional LLMs. We evaluate o3, a large reasoning model from OpenAI, with varying reasoning efforts, providing insights into the relationship between reasoning depth and evaluation quality. The explicit reasoning process in LRMs offers interpretability and visibility, addressing a key limitation of existing automated metrics. Our results demonstrate that Large Reasoning Models show a measurable advancement in translation quality assessment, combining improved accuracy with transparent evaluation across diverse language pairs. Read More
Smarter, Not Harder: How AI’s Self-Doubt Unlocks Peak PerformanceTowards Data Science “Deep Think with Confidence,” a smarter way to scale reasoning tasks without wasting a massive amount of computation
The post Smarter, Not Harder: How AI’s Self-Doubt Unlocks Peak Performance appeared first on Towards Data Science.
“Deep Think with Confidence,” a smarter way to scale reasoning tasks without wasting a massive amount of computation
The post Smarter, Not Harder: How AI’s Self-Doubt Unlocks Peak Performance appeared first on Towards Data Science. Read More
How to Build an Advanced Agentic Retrieval-Augmented Generation (RAG) System with Dynamic Strategy and Smart Retrieval?MarkTechPoston October 1, 2025 at 4:11 am In this tutorial, we walk through the implementation of an Agentic Retrieval-Augmented Generation (RAG) system. We design it so that the agent does more than just retrieve documents; it actively decides when retrieval is needed, selects the best retrieval strategy, and synthesizes responses with contextual awareness. By combining embeddings, FAISS indexing, and a mock LLM,
The post How to Build an Advanced Agentic Retrieval-Augmented Generation (RAG) System with Dynamic Strategy and Smart Retrieval? appeared first on MarkTechPost.
In this tutorial, we walk through the implementation of an Agentic Retrieval-Augmented Generation (RAG) system. We design it so that the agent does more than just retrieve documents; it actively decides when retrieval is needed, selects the best retrieval strategy, and synthesizes responses with contextual awareness. By combining embeddings, FAISS indexing, and a mock LLM,
The post How to Build an Advanced Agentic Retrieval-Augmented Generation (RAG) System with Dynamic Strategy and Smart Retrieval? appeared first on MarkTechPost. Read More
Beyond ROC-AUC and KS: The Gini Coefficient, Explained SimplyTowards Data Scienceon September 30, 2025 at 3:30 pm Understanding Gini and Lorenz curves for smarter model evaluation
The post Beyond ROC-AUC and KS: The Gini Coefficient, Explained Simply appeared first on Towards Data Science.
Understanding Gini and Lorenz curves for smarter model evaluation
The post Beyond ROC-AUC and KS: The Gini Coefficient, Explained Simply appeared first on Towards Data Science. Read More