
Timepoint-Specific Benchmarking of Deep Learning Models for Glioblastoma Follow-Up MRIcs.AI updates on arXiv.org arXiv:2511.18595v2 Announce Type: replace-cross
Abstract: Differentiating true tumor progression (TP) from treatment-related pseudoprogression (PsP) in glioblastoma remains challenging, especially at early follow-up. We present the first stage-specific, cross-sectional benchmarking of deep learning models for follow-up MRI using the Burdenko GBM Progression cohort (n = 180). We analyze different post-RT scans independently to test whether architecture performance depends on time-point. Eleven representative DL families (CNNs, LSTMs, hybrids, transformers, and selective state-space models) were trained under a unified, QC-driven pipeline with patient-level cross-validation. Across both stages, accuracies were comparable (~0.70-0.74), but discrimination improved at the second follow-up, with F1 and AUC increasing for several models, indicating richer separability later in the care pathway. A Mamba+CNN hybrid consistently offered the best accuracy-efficiency trade-off, while transformer variants delivered competitive AUCs at substantially higher computational cost and lightweight CNNs were efficient but less reliable. Performance also showed sensitivity to batch size, underscoring the need for standardized training protocols. Notably, absolute discrimination remained modest overall, reflecting the intrinsic difficulty of TP vs. PsP and the dataset’s size imbalance. These results establish a stage-aware benchmark and motivate future work incorporating longitudinal modeling, multi-sequence MRI, and larger multi-center cohorts.
arXiv:2511.18595v2 Announce Type: replace-cross
Abstract: Differentiating true tumor progression (TP) from treatment-related pseudoprogression (PsP) in glioblastoma remains challenging, especially at early follow-up. We present the first stage-specific, cross-sectional benchmarking of deep learning models for follow-up MRI using the Burdenko GBM Progression cohort (n = 180). We analyze different post-RT scans independently to test whether architecture performance depends on time-point. Eleven representative DL families (CNNs, LSTMs, hybrids, transformers, and selective state-space models) were trained under a unified, QC-driven pipeline with patient-level cross-validation. Across both stages, accuracies were comparable (~0.70-0.74), but discrimination improved at the second follow-up, with F1 and AUC increasing for several models, indicating richer separability later in the care pathway. A Mamba+CNN hybrid consistently offered the best accuracy-efficiency trade-off, while transformer variants delivered competitive AUCs at substantially higher computational cost and lightweight CNNs were efficient but less reliable. Performance also showed sensitivity to batch size, underscoring the need for standardized training protocols. Notably, absolute discrimination remained modest overall, reflecting the intrinsic difficulty of TP vs. PsP and the dataset’s size imbalance. These results establish a stage-aware benchmark and motivate future work incorporating longitudinal modeling, multi-sequence MRI, and larger multi-center cohorts. Read More
What Advent of Code Has Taught Me About Data ScienceTowards Data Science Five key learnings that I discovered during a programming challenge and how they apply to data science
The post What Advent of Code Has Taught Me About Data Science appeared first on Towards Data Science.
Five key learnings that I discovered during a programming challenge and how they apply to data science
The post What Advent of Code Has Taught Me About Data Science appeared first on Towards Data Science. Read More

10 Lesser-Known Python Libraries Every Data Scientist Should Be Using in 2026KDnuggets Want to level up your data science toolkit? Here are some Python libraries that’ll make your work easier.
Want to level up your data science toolkit? Here are some Python libraries that’ll make your work easier. Read More
Chunk Size as an Experimental Variable in RAG SystemsTowards Data Science Understanding retrieval in RAG systems by experimenting with different chunk sizes
The post Chunk Size as an Experimental Variable in RAG Systems appeared first on Towards Data Science.
Understanding retrieval in RAG systems by experimenting with different chunk sizes
The post Chunk Size as an Experimental Variable in RAG Systems appeared first on Towards Data Science. Read More
The Machine Learning “Advent Calendar” Bonus 2: Gradient Descent Variants in ExcelTowards Data Science Gradient Descent, Momentum, RMSProp, and Adam all aim for the same minimum. They do not change the destination, only the path. Each method adds a mechanism that fixes a limitation of the previous one, making the movement faster, more stable, or more adaptive. The goal stays the same. The update becomes smarter.
The post The Machine Learning “Advent Calendar” Bonus 2: Gradient Descent Variants in Excel appeared first on Towards Data Science.
Gradient Descent, Momentum, RMSProp, and Adam all aim for the same minimum. They do not change the destination, only the path. Each method adds a mechanism that fixes a limitation of the previous one, making the movement faster, more stable, or more adaptive. The goal stays the same. The update becomes smarter.
The post The Machine Learning “Advent Calendar” Bonus 2: Gradient Descent Variants in Excel appeared first on Towards Data Science. Read More
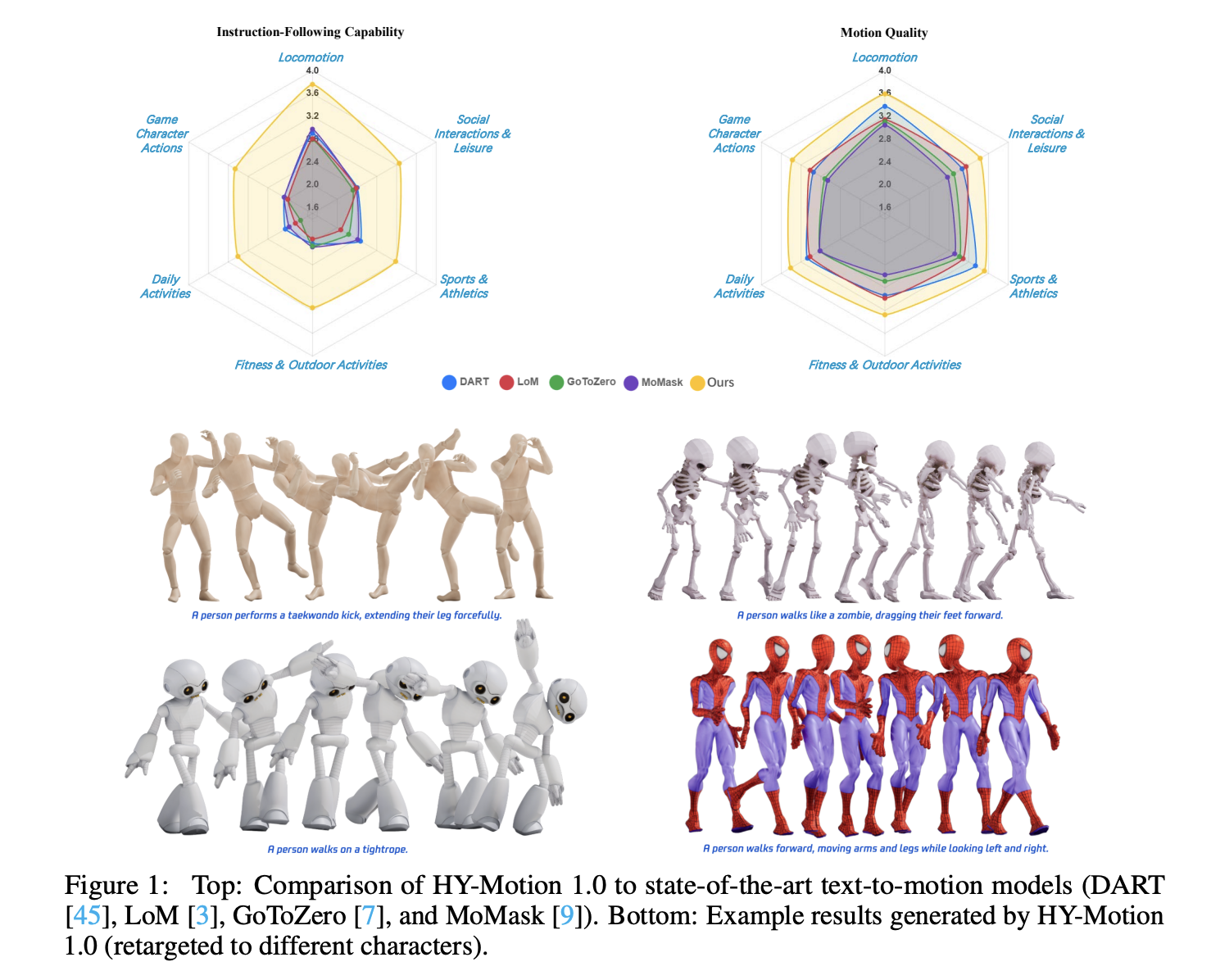
Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow MatchingMarkTechPost Tencent Hunyuan’s 3D Digital Human team has released HY-Motion 1.0, an open weight text-to-3D human motion generation family that scales Diffusion Transformer based Flow Matching to 1B parameters in the motion domain. The models turn natural language prompts plus an expected duration into 3D human motion clips on a unified SMPL-H skeleton and are available
The post Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching appeared first on MarkTechPost.
Tencent Hunyuan’s 3D Digital Human team has released HY-Motion 1.0, an open weight text-to-3D human motion generation family that scales Diffusion Transformer based Flow Matching to 1B parameters in the motion domain. The models turn natural language prompts plus an expected duration into 3D human motion clips on a unified SMPL-H skeleton and are available
The post Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching appeared first on MarkTechPost. Read More
The Law of Multi-Model Collaboration: Scaling Limits of Model Ensembling for Large Language Modelscs.AI updates on arXiv.org arXiv:2512.23340v1 Announce Type: cross
Abstract: Recent advances in large language models (LLMs) have been largely driven by scaling laws for individual models, which predict performance improvements as model parameters and data volume increase. However, the capabilities of any single LLM are inherently bounded. One solution originates from intricate interactions among multiple LLMs, rendering their collective performance surpasses that of any constituent model. Despite the rapid proliferation of multi-model integration techniques such as model routing and post-hoc ensembling, a unifying theoretical framework of performance scaling for multi-model collaboration remains absent. In this work, we propose the Law of Multi-model Collaboration, a scaling law that predicts the performance limits of LLM ensembles based on their aggregated parameter budget. To quantify the intrinsic upper bound of multi-model collaboration, we adopt a method-agnostic formulation and assume an idealized integration oracle where the total cross-entropy loss of each sample is determined by the minimum loss of any model in the model pool. Experimental results reveal that multi-model systems follow a power-law scaling with respect to the total parameter count, exhibiting a more significant improvement trend and a lower theoretical loss floor compared to single model scaling. Moreover, ensembles of heterogeneous model families achieve better performance scaling than those formed within a single model family, indicating that model diversity is a primary driver of collaboration gains. These findings suggest that model collaboration represents a critical axis for extending the intelligence frontier of LLMs.
arXiv:2512.23340v1 Announce Type: cross
Abstract: Recent advances in large language models (LLMs) have been largely driven by scaling laws for individual models, which predict performance improvements as model parameters and data volume increase. However, the capabilities of any single LLM are inherently bounded. One solution originates from intricate interactions among multiple LLMs, rendering their collective performance surpasses that of any constituent model. Despite the rapid proliferation of multi-model integration techniques such as model routing and post-hoc ensembling, a unifying theoretical framework of performance scaling for multi-model collaboration remains absent. In this work, we propose the Law of Multi-model Collaboration, a scaling law that predicts the performance limits of LLM ensembles based on their aggregated parameter budget. To quantify the intrinsic upper bound of multi-model collaboration, we adopt a method-agnostic formulation and assume an idealized integration oracle where the total cross-entropy loss of each sample is determined by the minimum loss of any model in the model pool. Experimental results reveal that multi-model systems follow a power-law scaling with respect to the total parameter count, exhibiting a more significant improvement trend and a lower theoretical loss floor compared to single model scaling. Moreover, ensembles of heterogeneous model families achieve better performance scaling than those formed within a single model family, indicating that model diversity is a primary driver of collaboration gains. These findings suggest that model collaboration represents a critical axis for extending the intelligence frontier of LLMs. Read More
QLLM: Do We Really Need a Mixing Network for Credit Assignment in Multi-Agent Reinforcement Learning?cs.AI updates on arXiv.org arXiv:2504.12961v4 Announce Type: replace-cross
Abstract: Credit assignment has remained a fundamental challenge in multi-agent reinforcement learning (MARL). Previous studies have primarily addressed this issue through value decomposition methods under the centralized training with decentralized execution paradigm, where neural networks are utilized to approximate the nonlinear relationship between individual Q-values and the global Q-value. Although these approaches have achieved considerable success in various benchmark tasks, they still suffer from several limitations, including imprecise attribution of contributions, limited interpretability, and poor scalability in high-dimensional state spaces. To address these challenges, we propose a novel algorithm, QLLM, which facilitates the automatic construction of credit assignment functions using large language models (LLMs). Specifically, the concept of TFCAF is introduced, wherein the credit allocation process is represented as a direct and expressive nonlinear functional formulation. A custom-designed coder-evaluator framework is further employed to guide the generation and verification of executable code by LLMs, significantly mitigating issues such as hallucination and shallow reasoning during inference. Furthermore, an IGM-Gating Mechanism enables QLLM to flexibly enforce or relax the monotonicity constraint depending on task demands, covering both IGM-compliant and non-monotonic scenarios. Extensive experiments conducted on several standard MARL benchmarks demonstrate that the proposed method consistently outperforms existing state-of-the-art baselines. Moreover, QLLM exhibits strong generalization capability and maintains compatibility with a wide range of MARL algorithms that utilize mixing networks, positioning it as a promising and versatile solution for complex multi-agent scenarios. The code is available at https://github.com/zhouyangjiang71-sys/QLLM.
arXiv:2504.12961v4 Announce Type: replace-cross
Abstract: Credit assignment has remained a fundamental challenge in multi-agent reinforcement learning (MARL). Previous studies have primarily addressed this issue through value decomposition methods under the centralized training with decentralized execution paradigm, where neural networks are utilized to approximate the nonlinear relationship between individual Q-values and the global Q-value. Although these approaches have achieved considerable success in various benchmark tasks, they still suffer from several limitations, including imprecise attribution of contributions, limited interpretability, and poor scalability in high-dimensional state spaces. To address these challenges, we propose a novel algorithm, QLLM, which facilitates the automatic construction of credit assignment functions using large language models (LLMs). Specifically, the concept of TFCAF is introduced, wherein the credit allocation process is represented as a direct and expressive nonlinear functional formulation. A custom-designed coder-evaluator framework is further employed to guide the generation and verification of executable code by LLMs, significantly mitigating issues such as hallucination and shallow reasoning during inference. Furthermore, an IGM-Gating Mechanism enables QLLM to flexibly enforce or relax the monotonicity constraint depending on task demands, covering both IGM-compliant and non-monotonic scenarios. Extensive experiments conducted on several standard MARL benchmarks demonstrate that the proposed method consistently outperforms existing state-of-the-art baselines. Moreover, QLLM exhibits strong generalization capability and maintains compatibility with a wide range of MARL algorithms that utilize mixing networks, positioning it as a promising and versatile solution for complex multi-agent scenarios. The code is available at https://github.com/zhouyangjiang71-sys/QLLM. Read More
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformationcs.AI updates on arXiv.org arXiv:2509.15965v2 Announce Type: replace-cross
Abstract: Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker’s adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving $1.07times-2.43times$ speedup in end-to-end training throughput.
arXiv:2509.15965v2 Announce Type: replace-cross
Abstract: Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker’s adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving $1.07times-2.43times$ speedup in end-to-end training throughput. Read More
Atom of Thoughts for Markov LLM Test-Time Scalingcs.AI updates on arXiv.org arXiv:2502.12018v4 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) have achieved significant performance gains through test-time scaling methods. However, existing approaches often incur redundant computations due to the accumulation of historical dependency information during inference. To address this challenge, we leverage the memoryless property of Markov processes to minimize reliance on historical context and propose a Markovian reasoning process. This foundational Markov chain structure enables seamless integration with various test-time scaling methods, thereby improving their scaling efficiency. By further scaling up the Markovian reasoning chain through integration with techniques such as tree search and reflective refinement, we uncover an emergent atomic reasoning structure, where reasoning trajectories are decomposed into a series of self-contained, low-complexity atomic units. We name this design Atom of Thoughts (our). Extensive experiments demonstrate that our consistently outperforms existing baselines as computational budgets increase. Importantly, our integrates seamlessly with existing reasoning frameworks and different LLMs (both reasoning and non-reasoning), facilitating scalable, high-performance inference.We submit our code alongside this paper and will make it publicly available to facilitate reproducibility and future research.
arXiv:2502.12018v4 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) have achieved significant performance gains through test-time scaling methods. However, existing approaches often incur redundant computations due to the accumulation of historical dependency information during inference. To address this challenge, we leverage the memoryless property of Markov processes to minimize reliance on historical context and propose a Markovian reasoning process. This foundational Markov chain structure enables seamless integration with various test-time scaling methods, thereby improving their scaling efficiency. By further scaling up the Markovian reasoning chain through integration with techniques such as tree search and reflective refinement, we uncover an emergent atomic reasoning structure, where reasoning trajectories are decomposed into a series of self-contained, low-complexity atomic units. We name this design Atom of Thoughts (our). Extensive experiments demonstrate that our consistently outperforms existing baselines as computational budgets increase. Importantly, our integrates seamlessly with existing reasoning frameworks and different LLMs (both reasoning and non-reasoning), facilitating scalable, high-performance inference.We submit our code alongside this paper and will make it publicly available to facilitate reproducibility and future research. Read More