
InqEduAgent: Adaptive AI Learning Partners with Gaussian Process Augmentationcs.AI updates on arXiv.orgon September 29, 2025 at 4:00 am arXiv:2508.03174v3 Announce Type: replace
Abstract: Collaborative partnership matters in inquiry-oriented education. However, most study partners are selected either rely on experience-based assignments with little scientific planning or build on rule-based machine assistants, encountering difficulties in knowledge expansion and inadequate flexibility. This paper proposes an LLM-empowered agent model for simulating and selecting learning partners tailored to inquiry-oriented learning, named InqEduAgent. Generative agents are designed to capture cognitive and evaluative features of learners in real-world scenarios. Then, an adaptive matching algorithm with Gaussian process augmentation is formulated to identify patterns within prior knowledge. Optimal learning-partner matches are provided for learners facing different exercises. The experimental results show the optimal performance of InqEduAgent in most knowledge-learning scenarios and LLM environment with different levels of capabilities. This study promotes the intelligent allocation of human-based learning partners and the formulation of AI-based learning partners. The code, data, and appendix are publicly available at https://github.com/InqEduAgent/InqEduAgent.
arXiv:2508.03174v3 Announce Type: replace
Abstract: Collaborative partnership matters in inquiry-oriented education. However, most study partners are selected either rely on experience-based assignments with little scientific planning or build on rule-based machine assistants, encountering difficulties in knowledge expansion and inadequate flexibility. This paper proposes an LLM-empowered agent model for simulating and selecting learning partners tailored to inquiry-oriented learning, named InqEduAgent. Generative agents are designed to capture cognitive and evaluative features of learners in real-world scenarios. Then, an adaptive matching algorithm with Gaussian process augmentation is formulated to identify patterns within prior knowledge. Optimal learning-partner matches are provided for learners facing different exercises. The experimental results show the optimal performance of InqEduAgent in most knowledge-learning scenarios and LLM environment with different levels of capabilities. This study promotes the intelligent allocation of human-based learning partners and the formulation of AI-based learning partners. The code, data, and appendix are publicly available at https://github.com/InqEduAgent/InqEduAgent. Read More

Python for Data Science (Free 7-Day Mini-Course)KDnuggetson September 29, 2025 at 12:00 pm Want to learn Python for data science? Start today with this beginner-friendly mini-course packed with bite-sized lessons and hands-on examples.
Want to learn Python for data science? Start today with this beginner-friendly mini-course packed with bite-sized lessons and hands-on examples. Read More
Can AI Perceive Physical Danger and Intervene?cs.AI updates on arXiv.orgon September 29, 2025 at 4:00 am arXiv:2509.21651v1 Announce Type: new
Abstract: When AI interacts with the physical world — as a robot or an assistive agent — new safety challenges emerge beyond those of purely “digital AI”. In such interactions, the potential for physical harm is direct and immediate. How well do state-of-the-art foundation models understand common-sense facts about physical safety, e.g. that a box may be too heavy to lift, or that a hot cup of coffee should not be handed to a child? In this paper, our contributions are three-fold: first, we develop a highly scalable approach to continuous physical safety benchmarking of Embodied AI systems, grounded in real-world injury narratives and operational safety constraints. To probe multi-modal safety understanding, we turn these narratives and constraints into photorealistic images and videos capturing transitions from safe to unsafe states, using advanced generative models. Secondly, we comprehensively analyze the ability of major foundation models to perceive risks, reason about safety, and trigger interventions; this yields multi-faceted insights into their deployment readiness for safety-critical agentic applications. Finally, we develop a post-training paradigm to teach models to explicitly reason about embodiment-specific safety constraints provided through system instructions. The resulting models generate thinking traces that make safety reasoning interpretable and transparent, achieving state of the art performance in constraint satisfaction evaluations. The benchmark will be released at https://asimov-benchmark.github.io/v2
arXiv:2509.21651v1 Announce Type: new
Abstract: When AI interacts with the physical world — as a robot or an assistive agent — new safety challenges emerge beyond those of purely “digital AI”. In such interactions, the potential for physical harm is direct and immediate. How well do state-of-the-art foundation models understand common-sense facts about physical safety, e.g. that a box may be too heavy to lift, or that a hot cup of coffee should not be handed to a child? In this paper, our contributions are three-fold: first, we develop a highly scalable approach to continuous physical safety benchmarking of Embodied AI systems, grounded in real-world injury narratives and operational safety constraints. To probe multi-modal safety understanding, we turn these narratives and constraints into photorealistic images and videos capturing transitions from safe to unsafe states, using advanced generative models. Secondly, we comprehensively analyze the ability of major foundation models to perceive risks, reason about safety, and trigger interventions; this yields multi-faceted insights into their deployment readiness for safety-critical agentic applications. Finally, we develop a post-training paradigm to teach models to explicitly reason about embodiment-specific safety constraints provided through system instructions. The resulting models generate thinking traces that make safety reasoning interpretable and transparent, achieving state of the art performance in constraint satisfaction evaluations. The benchmark will be released at https://asimov-benchmark.github.io/v2 Read More
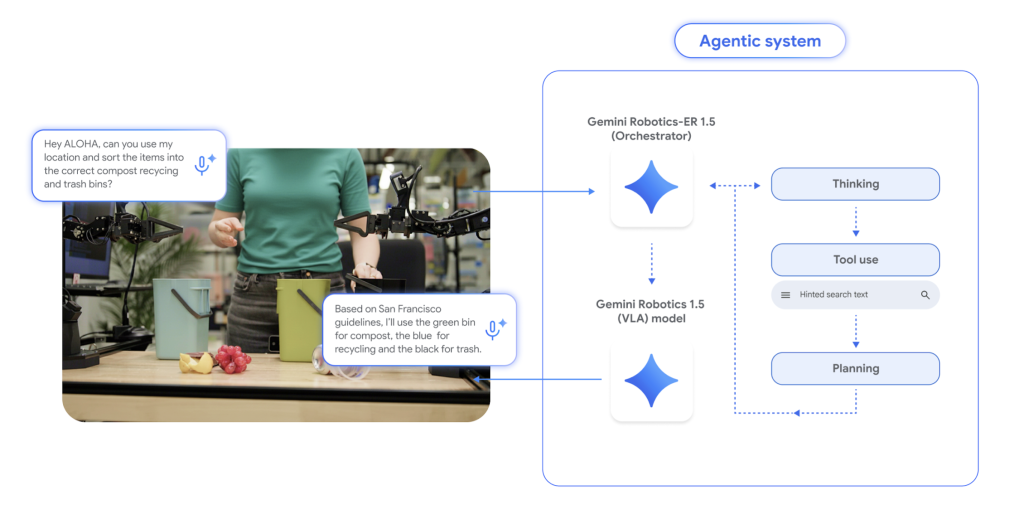
Gemini Robotics 1.5: DeepMind’s ER↔VLA Stack Brings Agentic Robots to the Real WorldMarkTechPoston September 28, 2025 at 8:29 am Can a single AI stack plan like a researcher, reason over scenes, and transfer motions across different robots—without retraining from scratch? Google DeepMind’s Gemini Robotics 1.5 says yes, by splitting embodied intelligence into two models: Gemini Robotics-ER 1.5 for high-level embodied reasoning (spatial understanding, planning, progress/success estimation, tool-use) and Gemini Robotics 1.5 for low-level visuomotor
The post Gemini Robotics 1.5: DeepMind’s ER↔VLA Stack Brings Agentic Robots to the Real World appeared first on MarkTechPost.
Can a single AI stack plan like a researcher, reason over scenes, and transfer motions across different robots—without retraining from scratch? Google DeepMind’s Gemini Robotics 1.5 says yes, by splitting embodied intelligence into two models: Gemini Robotics-ER 1.5 for high-level embodied reasoning (spatial understanding, planning, progress/success estimation, tool-use) and Gemini Robotics 1.5 for low-level visuomotor
The post Gemini Robotics 1.5: DeepMind’s ER↔VLA Stack Brings Agentic Robots to the Real World appeared first on MarkTechPost. Read More
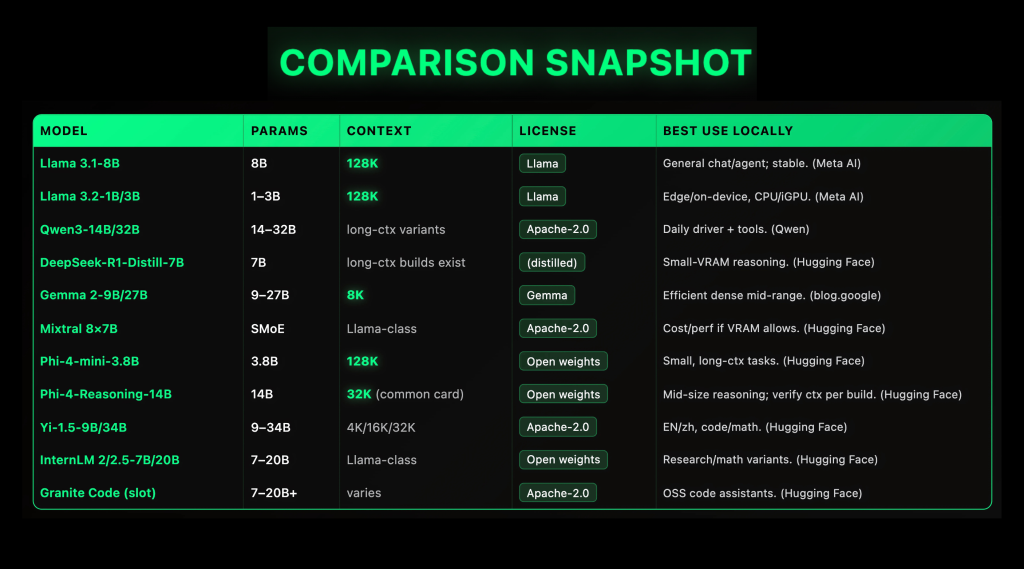
Top 10 Local LLMs (2025): Context Windows, VRAM Targets, and Licenses ComparedMarkTechPoston September 28, 2025 at 6:21 am Local LLMs matured fast in 2025: open-weight families like Llama 3.1 (128K context length (ctx)), Qwen3 (Apache-2.0, dense + MoE), Gemma 2 (9B/27B, 8K ctx), Mixtral 8×7B (Apache-2.0 SMoE), and Phi-4-mini (3.8B, 128K ctx) now ship reliable specs and first-class local runners (GGUF/llama.cpp, LM Studio, Ollama), making on-prem and even laptop inference practical if you
The post Top 10 Local LLMs (2025): Context Windows, VRAM Targets, and Licenses Compared appeared first on MarkTechPost.
Local LLMs matured fast in 2025: open-weight families like Llama 3.1 (128K context length (ctx)), Qwen3 (Apache-2.0, dense + MoE), Gemma 2 (9B/27B, 8K ctx), Mixtral 8×7B (Apache-2.0 SMoE), and Phi-4-mini (3.8B, 128K ctx) now ship reliable specs and first-class local runners (GGUF/llama.cpp, LM Studio, Ollama), making on-prem and even laptop inference practical if you
The post Top 10 Local LLMs (2025): Context Windows, VRAM Targets, and Licenses Compared appeared first on MarkTechPost. Read More
Quantum chips just proved they’re ready for the real worldArtificial Intelligence News — ScienceDailyon September 28, 2025 at 11:00 am Diraq has shown that its silicon-based quantum chips can maintain world-class accuracy even when mass-produced in semiconductor foundries. Achieving over 99% fidelity in two-qubit operations, the breakthrough clears a major hurdle toward utility-scale quantum computing. Silicon’s compatibility with existing chipmaking processes means building powerful quantum processors could become both cost-effective and scalable.
Diraq has shown that its silicon-based quantum chips can maintain world-class accuracy even when mass-produced in semiconductor foundries. Achieving over 99% fidelity in two-qubit operations, the breakthrough clears a major hurdle toward utility-scale quantum computing. Silicon’s compatibility with existing chipmaking processes means building powerful quantum processors could become both cost-effective and scalable. Read More
What Clients Really Ask for in AI ProjectsTowards Data Scienceon September 27, 2025 at 2:30 pm Managing AI projects is no walk in the park, but you have the power to make it easier for everyone
The post What Clients Really Ask for in AI Projects appeared first on Towards Data Science.
Managing AI projects is no walk in the park, but you have the power to make it easier for everyone
The post What Clients Really Ask for in AI Projects appeared first on Towards Data Science. Read More
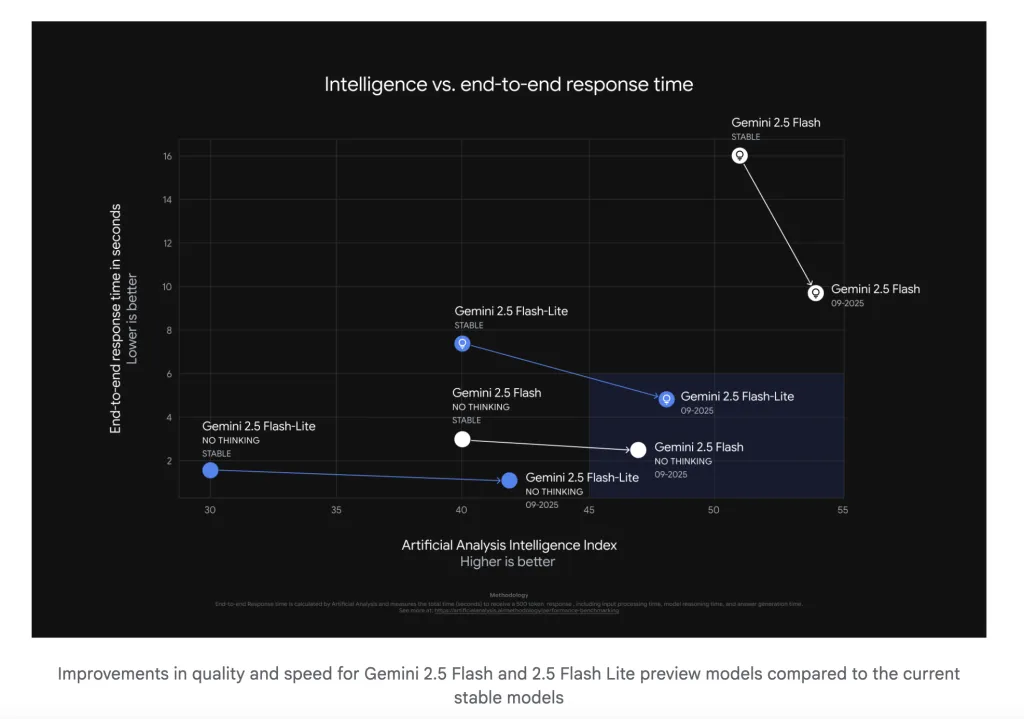
The Latest Gemini 2.5 Flash-Lite Preview is Now the Fastest Proprietary Model (External Tests) and 50% Fewer Output TokensMarkTechPoston September 27, 2025 at 11:08 pm Google released an updated version of Gemini 2.5 Flash and Gemini 2.5 Flash-Lite preview models across AI Studio and Vertex AI, plus rolling aliases—gemini-flash-latest and gemini-flash-lite-latest—that always point to the newest preview in each family. For production stability, Google advises pinning fixed strings (gemini-2.5-flash, gemini-2.5-flash-lite). Google will give a two-week email notice before retargeting a
The post The Latest Gemini 2.5 Flash-Lite Preview is Now the Fastest Proprietary Model (External Tests) and 50% Fewer Output Tokens appeared first on MarkTechPost.
Google released an updated version of Gemini 2.5 Flash and Gemini 2.5 Flash-Lite preview models across AI Studio and Vertex AI, plus rolling aliases—gemini-flash-latest and gemini-flash-lite-latest—that always point to the newest preview in each family. For production stability, Google advises pinning fixed strings (gemini-2.5-flash, gemini-2.5-flash-lite). Google will give a two-week email notice before retargeting a
The post The Latest Gemini 2.5 Flash-Lite Preview is Now the Fastest Proprietary Model (External Tests) and 50% Fewer Output Tokens appeared first on MarkTechPost. Read More
Learning Triton One Kernel At a Time: Vector AdditionTowards Data Scienceon September 27, 2025 at 4:00 pm The basics of GPU programming, optimisation, and your first Triton kernel
The post Learning Triton One Kernel At a Time: Vector Addition appeared first on Towards Data Science.
The basics of GPU programming, optimisation, and your first Triton kernel
The post Learning Triton One Kernel At a Time: Vector Addition appeared first on Towards Data Science. Read More
How to Build an Intelligent AI Desktop Automation Agent with Natural Language Commands and Interactive Simulation?MarkTechPoston September 27, 2025 at 6:40 am In this tutorial, we walk through the process of building an advanced AI desktop automation agent that runs seamlessly in Google Colab. We design it to interpret natural language commands, simulate desktop tasks such as file operations, browser actions, and workflows, and provide interactive feedback through a virtual environment. By combining NLP, task execution, and
The post How to Build an Intelligent AI Desktop Automation Agent with Natural Language Commands and Interactive Simulation? appeared first on MarkTechPost.
In this tutorial, we walk through the process of building an advanced AI desktop automation agent that runs seamlessly in Google Colab. We design it to interpret natural language commands, simulate desktop tasks such as file operations, browser actions, and workflows, and provide interactive feedback through a virtual environment. By combining NLP, task execution, and
The post How to Build an Intelligent AI Desktop Automation Agent with Natural Language Commands and Interactive Simulation? appeared first on MarkTechPost. Read More