
CAMIA privacy attack reveals what AI models memoriseAI Newson September 26, 2025 at 5:17 pm Researchers have developed a new attack that reveals privacy vulnerabilities by determining whether your data was used to train AI models. The method, named CAMIA (Context-Aware Membership Inference Attack), was developed by researchers from Brave and the National University of Singapore and is far more effective than previous attempts at probing the ‘memory’ of AI
The post CAMIA privacy attack reveals what AI models memorise appeared first on AI News.
Researchers have developed a new attack that reveals privacy vulnerabilities by determining whether your data was used to train AI models. The method, named CAMIA (Context-Aware Membership Inference Attack), was developed by researchers from Brave and the National University of Singapore and is far more effective than previous attempts at probing the ‘memory’ of AI
The post CAMIA privacy attack reveals what AI models memorise appeared first on AI News. Read More
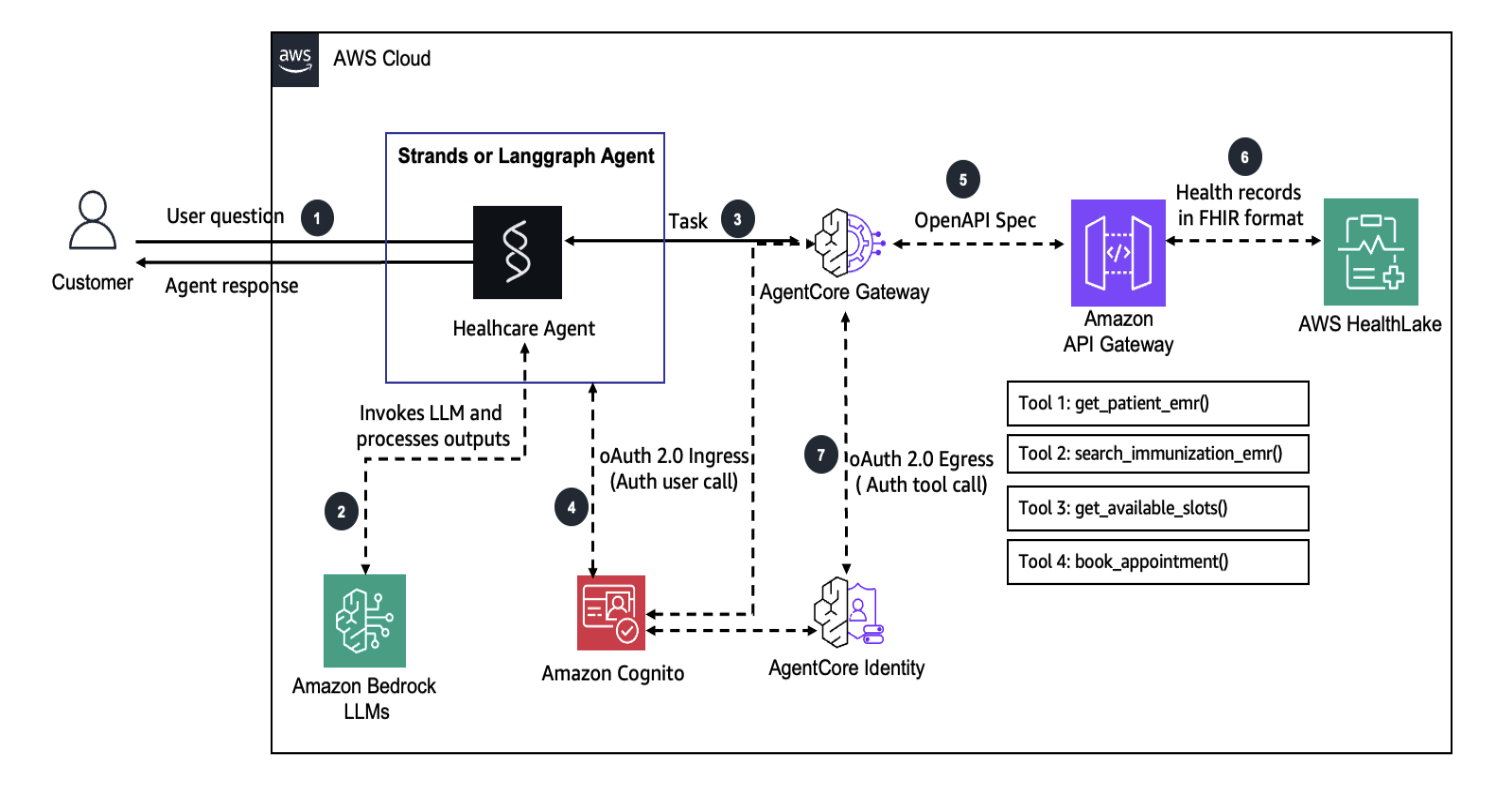
Building health care agents using Amazon Bedrock AgentCoreArtificial Intelligenceon September 26, 2025 at 4:03 pm In this solution, we demonstrate how the user (a parent) can interact with a Strands or LangGraph agent in conversational style and get information about the immunization history and schedule of their child, inquire about the available slots, and book appointments. With some changes, AI agents can be made event-driven so that they can automatically send reminders, book appointments, and so on.
In this solution, we demonstrate how the user (a parent) can interact with a Strands or LangGraph agent in conversational style and get information about the immunization history and schedule of their child, inquire about the available slots, and book appointments. With some changes, AI agents can be made event-driven so that they can automatically send reminders, book appointments, and so on. Read More

Why MissForest Fails in Prediction Tasks: A Key Limitation You Need to Keep in MindTowards Data Scienceon September 26, 2025 at 2:00 pm Why the original MissForest algorithm cannot be directly applied for predictive modeling, and how MissForestPredict solves this problem
The post Why MissForest Fails in Prediction Tasks: A Key Limitation You Need to Keep in Mind appeared first on Towards Data Science.
Why the original MissForest algorithm cannot be directly applied for predictive modeling, and how MissForestPredict solves this problem
The post Why MissForest Fails in Prediction Tasks: A Key Limitation You Need to Keep in Mind appeared first on Towards Data Science. Read More
US investigators are using AI to detect child abuse images made by AIMIT Technology Reviewon September 26, 2025 at 7:03 pm Generative AI has enabled the production of child sexual abuse images to skyrocket. Now the leading investigator of child exploitation in the US is experimenting with using AI to distinguish AI-generated images from material depicting real victims, according to a new government filing. The Department of Homeland Security’s Cyber Crimes Center, which investigates child exploitation…
Generative AI has enabled the production of child sexual abuse images to skyrocket. Now the leading investigator of child exploitation in the US is experimenting with using AI to distinguish AI-generated images from material depicting real victims, according to a new government filing. The Department of Homeland Security’s Cyber Crimes Center, which investigates child exploitation… Read More
Hugging Face Releases Smol2Operator: A Fully Open-Source Pipeline to Train a 2.2B VLM into an Agentic GUI CoderMarkTechPoston September 26, 2025 at 8:51 pm Hugging Face (HF) has released Smol2Operator, a reproducible, end-to-end recipe that turns a small vision-language model (VLM) with no prior UI grounding into a GUI-operating, tool-using agent. The release covers data transformation utilities, training scripts, transformed datasets, and the resulting 2.2B-parameter model checkpoint—positioned as a complete blueprint for building GUI agents from scratch rather than
The post Hugging Face Releases Smol2Operator: A Fully Open-Source Pipeline to Train a 2.2B VLM into an Agentic GUI Coder appeared first on MarkTechPost.
Hugging Face (HF) has released Smol2Operator, a reproducible, end-to-end recipe that turns a small vision-language model (VLM) with no prior UI grounding into a GUI-operating, tool-using agent. The release covers data transformation utilities, training scripts, transformed datasets, and the resulting 2.2B-parameter model checkpoint—positioned as a complete blueprint for building GUI agents from scratch rather than
The post Hugging Face Releases Smol2Operator: A Fully Open-Source Pipeline to Train a 2.2B VLM into an Agentic GUI Coder appeared first on MarkTechPost. Read More

AI News September 26 2025: Robots, AI Videos & $30M Funding Executive Summary AI News Roundup: Robots Get Smarter, Meta Pushes AI Videos, and Recruiting Goes LLM The AI world took a breather yesterday. No mega-rounds. No AGI announcements. Just three developments worth your attention. Google’s Robots Can Now Think Ahead (And Google Things) Yesterday […]

How to Build and Publish a Docker Image to Docker HubKDnuggetson September 25, 2025 at 2:00 pm Build once, run anywhere — deploy your app with Docker and Docker Hub.
Build once, run anywhere — deploy your app with Docker and Docker Hub. Read More

Salesforce Confident in India’s Growth Amid Push for Local SolutionsAnalytics India Magazineon September 25, 2025 at 10:31 am “It’s important to experiment and learn. Every failure teaches us how to do things better,” Salesforce CEO said.
The post Salesforce Confident in India’s Growth Amid Push for Local Solutions appeared first on Analytics India Magazine.
“It’s important to experiment and learn. Every failure teaches us how to do things better,” Salesforce CEO said.
The post Salesforce Confident in India’s Growth Amid Push for Local Solutions appeared first on Analytics India Magazine. Read More
Fusion power plants don’t exist yet, but they’re making money anyway MIT Technology Review (paywall)
Fusion power plants don’t exist yet, but they’re making money anywayMIT Technology Reviewon September 25, 2025 at 10:00 am This week, Commonwealth Fusion Systems announced it has another customer for its first commercial fusion power plant, in Virginia. Eni, one of the world’s largest oil and gas companies, signed a billion-dollar deal to buy electricity from the facility. One small detail? That reactor doesn’t exist yet. Neither does the smaller reactor Commonwealth is building…
This week, Commonwealth Fusion Systems announced it has another customer for its first commercial fusion power plant, in Virginia. Eni, one of the world’s largest oil and gas companies, signed a billion-dollar deal to buy electricity from the facility. One small detail? That reactor doesn’t exist yet. Neither does the smaller reactor Commonwealth is building… Read More

Inside Huawei’s plan to make thousands of AI chips think like one computerAI Newson September 25, 2025 at 9:23 am Imagine connecting thousands of powerful AI chips scattered in dozens of server cabinets and making them work together as if they were a single, massive computer. That is exactly what Huawei demonstrated at HUAWEI CONNECT 2025, where the company unveiled a breakthrough in AI infrastructure architecture that could reshape how the world builds and scales
The post Inside Huawei’s plan to make thousands of AI chips think like one computer appeared first on AI News.
Imagine connecting thousands of powerful AI chips scattered in dozens of server cabinets and making them work together as if they were a single, massive computer. That is exactly what Huawei demonstrated at HUAWEI CONNECT 2025, where the company unveiled a breakthrough in AI infrastructure architecture that could reshape how the world builds and scales
The post Inside Huawei’s plan to make thousands of AI chips think like one computer appeared first on AI News. Read More