
How to Run Coding Agents in ParallelTowards Data Science Get the most out of Claude Code
The post How to Run Coding Agents in Parallel appeared first on Towards Data Science.
Get the most out of Claude Code
The post How to Run Coding Agents in Parallel appeared first on Towards Data Science. Read More
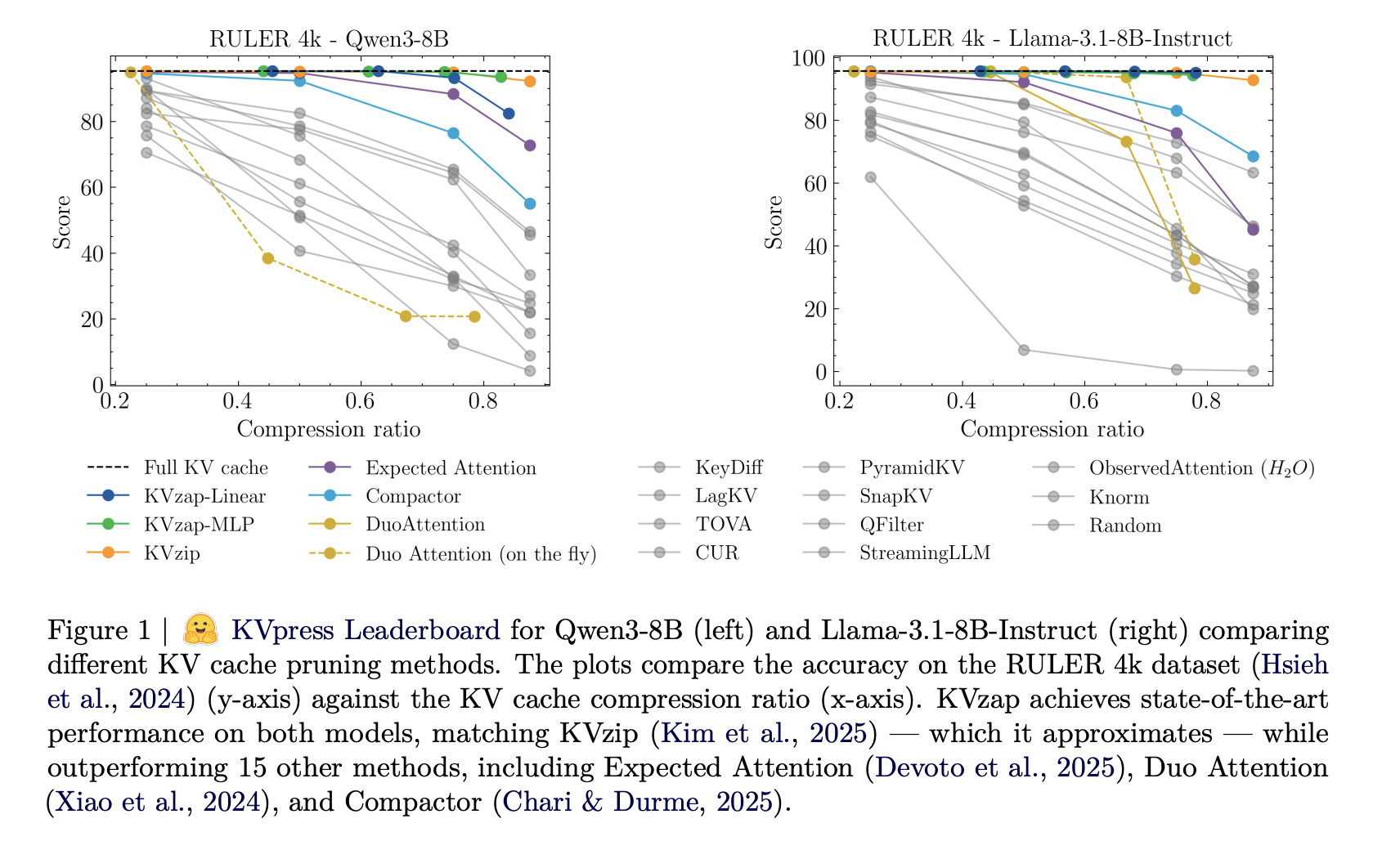
NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x CompressionMarkTechPost As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck. The cache stores keys and values for every layer and head with shape (2, L, H, T, D). For a vanilla transformer such as Llama1-65B, the cache reaches about 335 GB
The post NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression appeared first on MarkTechPost.
As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck. The cache stores keys and values for every layer and head with shape (2, L, H, T, D). For a vanilla transformer such as Llama1-65B, the cache reaches about 335 GB
The post NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression appeared first on MarkTechPost. Read More

AI dominated the conversation in 2025, CIOs shift gears in 2026AI News Author: Richard Farrell, CIO at Netcall After a year of rapid adoption and high expectations surrounding artificial intelligence, 2026 is shaping up to be the year CIOs apply a more strategic lens. Not to slow progress, but to steer it in a smarter direction. In 2025, we saw the rise of AI copilots across almost
The post AI dominated the conversation in 2025, CIOs shift gears in 2026 appeared first on AI News.
Author: Richard Farrell, CIO at Netcall After a year of rapid adoption and high expectations surrounding artificial intelligence, 2026 is shaping up to be the year CIOs apply a more strategic lens. Not to slow progress, but to steer it in a smarter direction. In 2025, we saw the rise of AI copilots across almost
The post AI dominated the conversation in 2025, CIOs shift gears in 2026 appeared first on AI News. Read More
When Shapley Values Break: A Guide to Robust Model ExplainabilityTowards Data Science Shapley Values are one of the most common methods for explainability, yet they can be misleading. Discover how to overcome these limitations to achieve better insights.
The post When Shapley Values Break: A Guide to Robust Model Explainability appeared first on Towards Data Science.
Shapley Values are one of the most common methods for explainability, yet they can be misleading. Discover how to overcome these limitations to achieve better insights.
The post When Shapley Values Break: A Guide to Robust Model Explainability appeared first on Towards Data Science. Read More

How the Amazon AMET Payments team accelerates test case generation with Strands AgentsArtificial Intelligence In this post, we explain how we overcame the limitations of single-agent AI systems through a human-centric approach, implemented structured outputs to significantly reduce hallucinations and built a scalable solution now positioned for expansion across the AMET QA team and later across other QA teams in International Emerging Stores and Payments (IESP) Org.
In this post, we explain how we overcame the limitations of single-agent AI systems through a human-centric approach, implemented structured outputs to significantly reduce hallucinations and built a scalable solution now positioned for expansion across the AMET QA team and later across other QA teams in International Emerging Stores and Payments (IESP) Org. Read More
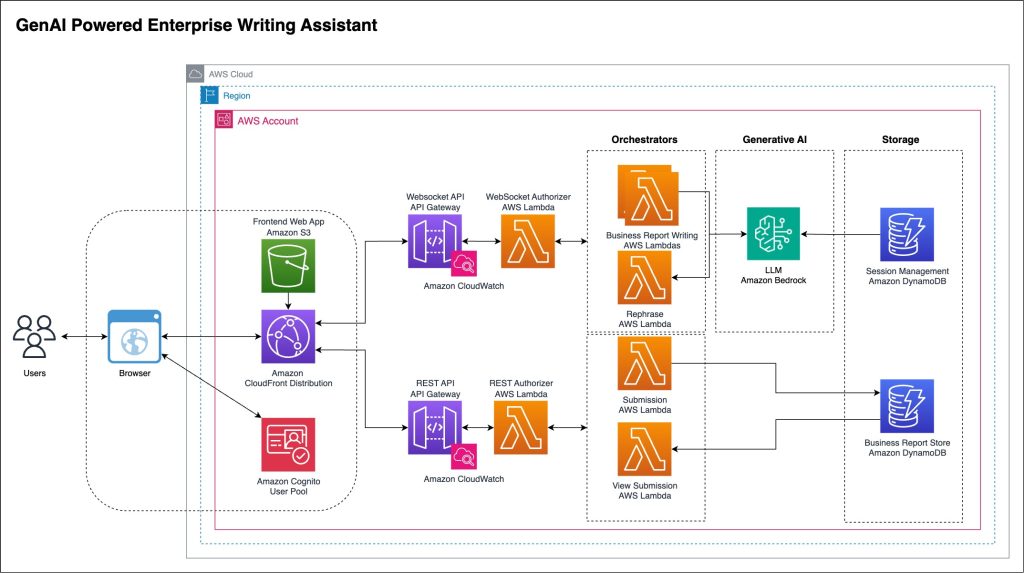
Build a generative AI-powered business reporting solution with Amazon BedrockArtificial Intelligence This post introduces generative AI guided business reporting—with a focus on writing achievements & challenges about your business—providing a smart, practical solution that helps simplify and accelerate internal communication and reporting.
This post introduces generative AI guided business reporting—with a focus on writing achievements & challenges about your business—providing a smart, practical solution that helps simplify and accelerate internal communication and reporting. Read More
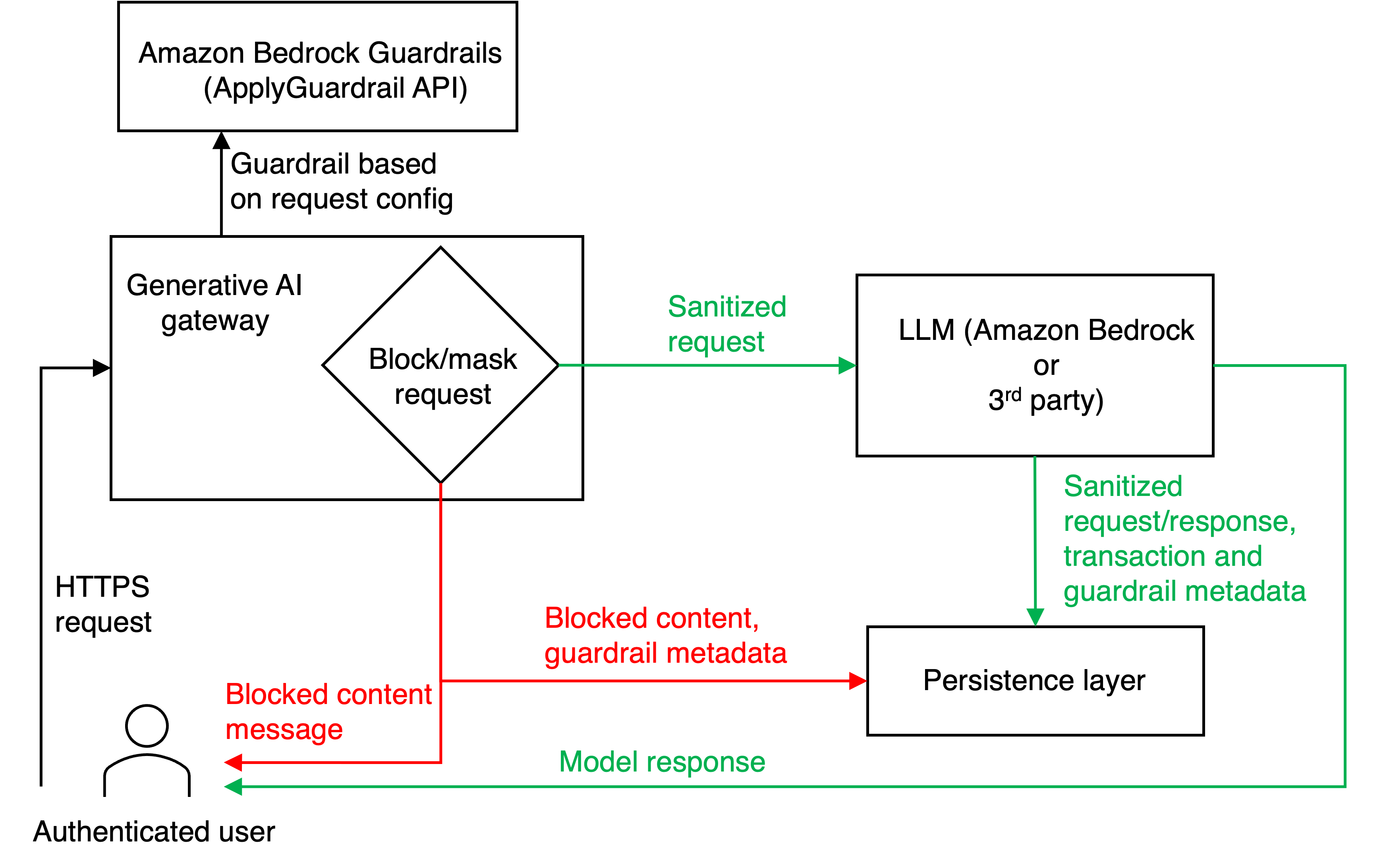
Safeguard generative AI applications with Amazon Bedrock GuardrailsArtificial Intelligence In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails.
In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails. Read More
PRISMA: Reinforcement Learning Guided Two-Stage Policy Optimization in Multi-Agent Architecture for Open-Domain Multi-Hop Question Answeringcs.AI updates on arXiv.org arXiv:2601.05465v1 Announce Type: new
Abstract: Answering real-world open-domain multi-hop questions over massive corpora is a critical challenge in Retrieval-Augmented Generation (RAG) systems. Recent research employs reinforcement learning (RL) to end-to-end optimize the retrieval-augmented reasoning process, directly enhancing its capacity to resolve complex queries. However, reliable deployment is hindered by two obstacles. 1) Retrieval Collapse: iterative retrieval over large corpora fails to locate intermediate evidence containing bridge answers without reasoning-guided planning, causing downstream reasoning to collapse. 2) Learning Instability: end-to-end trajectory training suffers from weak credit assignment across reasoning chains and poor error localization across modules, causing overfitting to benchmark-specific heuristics that limit transferability and stability. To address these problems, we propose PRISMA, a decoupled RL-guided framework featuring a Plan-Retrieve-Inspect-Solve-Memoize architecture. PRISMA’s strength lies in reasoning-guided collaboration: the Inspector provides reasoning-based feedback to refine the Planner’s decomposition and fine-grained retrieval, while enforcing evidence-grounded reasoning in the Solver. We optimize individual agent capabilities via Two-Stage Group Relative Policy Optimization (GRPO). Stage I calibrates the Planner and Solver as specialized experts in planning and reasoning, while Stage II utilizes Observation-Aware Residual Policy Optimization (OARPO) to enhance the Inspector’s ability to verify context and trigger targeted recovery. Experiments show that PRISMA achieves state-of-the-art performance on ten benchmarks and can be deployed efficiently in real-world scenarios.
arXiv:2601.05465v1 Announce Type: new
Abstract: Answering real-world open-domain multi-hop questions over massive corpora is a critical challenge in Retrieval-Augmented Generation (RAG) systems. Recent research employs reinforcement learning (RL) to end-to-end optimize the retrieval-augmented reasoning process, directly enhancing its capacity to resolve complex queries. However, reliable deployment is hindered by two obstacles. 1) Retrieval Collapse: iterative retrieval over large corpora fails to locate intermediate evidence containing bridge answers without reasoning-guided planning, causing downstream reasoning to collapse. 2) Learning Instability: end-to-end trajectory training suffers from weak credit assignment across reasoning chains and poor error localization across modules, causing overfitting to benchmark-specific heuristics that limit transferability and stability. To address these problems, we propose PRISMA, a decoupled RL-guided framework featuring a Plan-Retrieve-Inspect-Solve-Memoize architecture. PRISMA’s strength lies in reasoning-guided collaboration: the Inspector provides reasoning-based feedback to refine the Planner’s decomposition and fine-grained retrieval, while enforcing evidence-grounded reasoning in the Solver. We optimize individual agent capabilities via Two-Stage Group Relative Policy Optimization (GRPO). Stage I calibrates the Planner and Solver as specialized experts in planning and reasoning, while Stage II utilizes Observation-Aware Residual Policy Optimization (OARPO) to enhance the Inspector’s ability to verify context and trigger targeted recovery. Experiments show that PRISMA achieves state-of-the-art performance on ten benchmarks and can be deployed efficiently in real-world scenarios. Read More
Reasoning Models Will Blatantly Lie About Their Reasoningcs.AI updates on arXiv.org arXiv:2601.07663v2 Announce Type: replace
Abstract: It has been shown that Large Reasoning Models (LRMs) may not *say what they think*: they do not always volunteer information about how certain parts of the input influence their reasoning. But it is one thing for a model to *omit* such information and another, worse thing to *lie* about it. Here, we extend the work of Chen et al. (2025) to show that LRMs will do just this: they will flatly deny relying on hints provided in the prompt in answering multiple choice questions — even when directly asked to reflect on unusual (i.e. hinted) prompt content, even when allowed to use hints, and even though experiments *show* them to be using the hints. Our results thus have discouraging implications for CoT monitoring and interpretability.
arXiv:2601.07663v2 Announce Type: replace
Abstract: It has been shown that Large Reasoning Models (LRMs) may not *say what they think*: they do not always volunteer information about how certain parts of the input influence their reasoning. But it is one thing for a model to *omit* such information and another, worse thing to *lie* about it. Here, we extend the work of Chen et al. (2025) to show that LRMs will do just this: they will flatly deny relying on hints provided in the prompt in answering multiple choice questions — even when directly asked to reflect on unusual (i.e. hinted) prompt content, even when allowed to use hints, and even though experiments *show* them to be using the hints. Our results thus have discouraging implications for CoT monitoring and interpretability. Read More
7 AI Automation Tools for Streamlined WorkflowsKDnuggets This list focuses on tools that streamline real workflows across data, operations, and content, not flashy demos or brittle bots. Each one earns its place by reducing manual effort while keeping humans in the loop where it actually matters.
This list focuses on tools that streamline real workflows across data, operations, and content, not flashy demos or brittle bots. Each one earns its place by reducing manual effort while keeping humans in the loop where it actually matters. Read More