
Amazon Bedrock AgentCore and Claude: Transforming business with agentic AIArtificial Intelligence In this post, we explore how Amazon Bedrock AgentCore and Claude are enabling enterprises like Cox Automotive and Druva to deploy production-ready agentic AI systems that deliver measurable business value, with results including up to 63% autonomous issue resolution and 58% faster response times. We examine the technical foundation combining Claude’s frontier AI capabilities with AgentCore’s enterprise-grade infrastructure that allows organizations to focus on agent logic rather than building complex operational systems from scratch.
In this post, we explore how Amazon Bedrock AgentCore and Claude are enabling enterprises like Cox Automotive and Druva to deploy production-ready agentic AI systems that deliver measurable business value, with results including up to 63% autonomous issue resolution and 58% faster response times. We examine the technical foundation combining Claude’s frontier AI capabilities with AgentCore’s enterprise-grade infrastructure that allows organizations to focus on agent logic rather than building complex operational systems from scratch. Read More

Introducing ShaTS: A Shapley-Based Method for Time-Series ModelsTowards Data Science Why you should not explain your time-series data with tabular Shapley methods
The post Introducing ShaTS: A Shapley-Based Method for Time-Series Models appeared first on Towards Data Science.
Why you should not explain your time-series data with tabular Shapley methods
The post Introducing ShaTS: A Shapley-Based Method for Time-Series Models appeared first on Towards Data Science. Read More
Local AI models: How to keep control of the bidstream without losing your dataAI News Author: Olga Zharuk, CPO, Teqblaze When it comes to applying AI in programmatic, two things matter most: performance and data security. I’ve seen too many internal security audits flag third-party AI services as exposure points. Granting third-party AI agents access to proprietary bidstream data introduces unnecessary exposure that many organisations are no longer willing to
The post Local AI models: How to keep control of the bidstream without losing your data appeared first on AI News.
Author: Olga Zharuk, CPO, Teqblaze When it comes to applying AI in programmatic, two things matter most: performance and data security. I’ve seen too many internal security audits flag third-party AI services as exposure points. Granting third-party AI agents access to proprietary bidstream data introduces unnecessary exposure that many organisations are no longer willing to
The post Local AI models: How to keep control of the bidstream without losing your data appeared first on AI News. Read More

Quantitative finance experts believe graduates ill-equipped for AI futureAI News New insight from the CQF Institute, a worldwide network for quantitative finance professionals (quants), reveals that fewer than one in ten specialists believe new graduates possess the AI and machine learning skills necessary to succeed in the industry. This highlights a growing issue in quantitative finance: a lack of human understanding and fluency in the
The post Quantitative finance experts believe graduates ill-equipped for AI future appeared first on AI News.
New insight from the CQF Institute, a worldwide network for quantitative finance professionals (quants), reveals that fewer than one in ten specialists believe new graduates possess the AI and machine learning skills necessary to succeed in the industry. This highlights a growing issue in quantitative finance: a lack of human understanding and fluency in the
The post Quantitative finance experts believe graduates ill-equipped for AI future appeared first on AI News. Read More

7 Steps to Build a Simple RAG System from ScratchKDnuggets This step-by-step tutorial walks you through building your own RAG system.
This step-by-step tutorial walks you through building your own RAG system. Read More
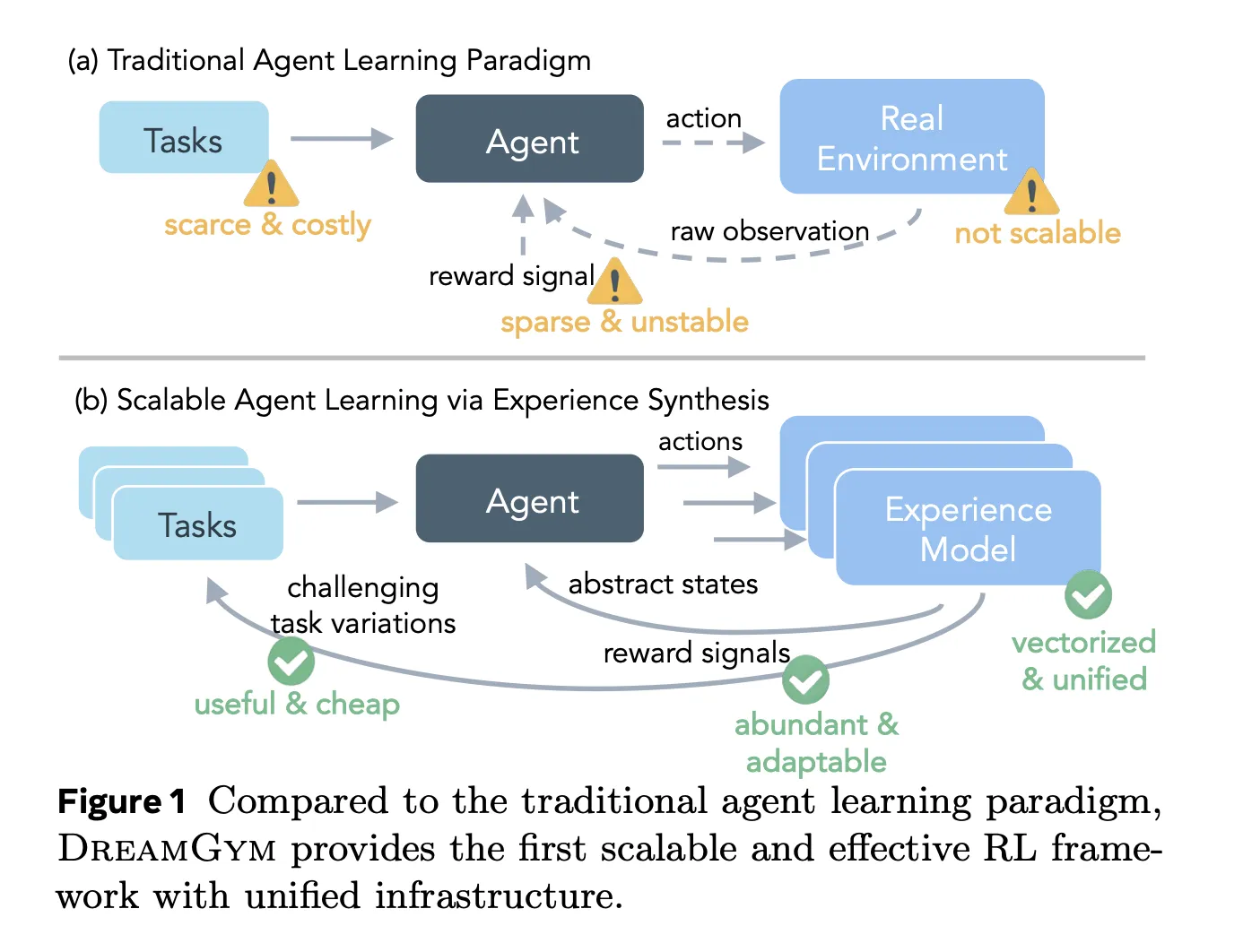
Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL AgentsMarkTechPost Reinforcement learning RL for large language model LLM agents looks attractive on paper, but in practice it breaks on cost, infrastructure and reward noise. Training an agent that clicks through web pages or completes multi step tool use can easily need tens of thousands of real interactions, each slow, brittle and hard to reset. Meta’s
The post Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL Agents appeared first on MarkTechPost.
Reinforcement learning RL for large language model LLM agents looks attractive on paper, but in practice it breaks on cost, infrastructure and reward noise. Training an agent that clicks through web pages or completes multi step tool use can easily need tens of thousands of real interactions, each slow, brittle and hard to reset. Meta’s
The post Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL Agents appeared first on MarkTechPost. Read More
S2D-ALIGN: Shallow-to-Deep Auxiliary Learning for Anatomically-Grounded Radiology Report Generationcs.AI updates on arXiv.org arXiv:2511.11066v1 Announce Type: cross
Abstract: Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public textsc{MIMIC-CXR} and textsc{IU X-Ray} benchmarks, where textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks.
arXiv:2511.11066v1 Announce Type: cross
Abstract: Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public textsc{MIMIC-CXR} and textsc{IU X-Ray} benchmarks, where textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks. Read More
Building the Web for Agents: A Declarative Framework for Agent-Web Interactioncs.AI updates on arXiv.org arXiv:2511.11287v1 Announce Type: cross
Abstract: The increasing deployment of autonomous AI agents on the web is hampered by a fundamental misalignment: agents must infer affordances from human-oriented user interfaces, leading to brittle, inefficient, and insecure interactions. To address this, we introduce VOIX, a web-native framework that enables websites to expose reliable, auditable, and privacy-preserving capabilities for AI agents through simple, declarative HTML elements. VOIX introduces and tags, allowing developers to explicitly define available actions and relevant state, thereby creating a clear, machine-readable contract for agent behavior. This approach shifts control to the website developer while preserving user privacy by disconnecting the conversational interactions from the website. We evaluated the framework’s practicality, learnability, and expressiveness in a three-day hackathon study with 16 developers. The results demonstrate that participants, regardless of prior experience, were able to rapidly build diverse and functional agent-enabled web applications. Ultimately, this work provides a foundational mechanism for realizing the Agentic Web, enabling a future of seamless and secure human-AI collaboration on the web.
arXiv:2511.11287v1 Announce Type: cross
Abstract: The increasing deployment of autonomous AI agents on the web is hampered by a fundamental misalignment: agents must infer affordances from human-oriented user interfaces, leading to brittle, inefficient, and insecure interactions. To address this, we introduce VOIX, a web-native framework that enables websites to expose reliable, auditable, and privacy-preserving capabilities for AI agents through simple, declarative HTML elements. VOIX introduces and tags, allowing developers to explicitly define available actions and relevant state, thereby creating a clear, machine-readable contract for agent behavior. This approach shifts control to the website developer while preserving user privacy by disconnecting the conversational interactions from the website. We evaluated the framework’s practicality, learnability, and expressiveness in a three-day hackathon study with 16 developers. The results demonstrate that participants, regardless of prior experience, were able to rapidly build diverse and functional agent-enabled web applications. Ultimately, this work provides a foundational mechanism for realizing the Agentic Web, enabling a future of seamless and secure human-AI collaboration on the web. Read More
Algorithms Trained on Normal Chest X-rays Can Predict Health Insurance Types AI updates on arXiv.org
Algorithms Trained on Normal Chest X-rays Can Predict Health Insurance Typescs.AI updates on arXiv.org arXiv:2511.11030v1 Announce Type: cross
Abstract: Artificial intelligence is revealing what medicine never intended to encode. Deep vision models, trained on chest X-rays, can now detect not only disease but also invisible traces of social inequality. In this study, we show that state-of-the-art architectures (DenseNet121, SwinV2-B, MedMamba) can predict a patient’s health insurance type, a strong proxy for socioeconomic status, from normal chest X-rays with significant accuracy (AUC around 0.67 on MIMIC-CXR-JPG, 0.68 on CheXpert). The signal persists even when age, race, and sex are controlled for, and remains detectable when the model is trained exclusively on a single racial group. Patch-based occlusion reveals that the signal is diffuse rather than localized, embedded in the upper and mid-thoracic regions. This suggests that deep networks may be internalizing subtle traces of clinical environments, equipment differences, or care pathways; learning socioeconomic segregation itself. These findings challenge the assumption that medical images are neutral biological data. By uncovering how models perceive and exploit these hidden social signatures, this work reframes fairness in medical AI: the goal is no longer only to balance datasets or adjust thresholds, but to interrogate and disentangle the social fingerprints embedded in clinical data itself.
arXiv:2511.11030v1 Announce Type: cross
Abstract: Artificial intelligence is revealing what medicine never intended to encode. Deep vision models, trained on chest X-rays, can now detect not only disease but also invisible traces of social inequality. In this study, we show that state-of-the-art architectures (DenseNet121, SwinV2-B, MedMamba) can predict a patient’s health insurance type, a strong proxy for socioeconomic status, from normal chest X-rays with significant accuracy (AUC around 0.67 on MIMIC-CXR-JPG, 0.68 on CheXpert). The signal persists even when age, race, and sex are controlled for, and remains detectable when the model is trained exclusively on a single racial group. Patch-based occlusion reveals that the signal is diffuse rather than localized, embedded in the upper and mid-thoracic regions. This suggests that deep networks may be internalizing subtle traces of clinical environments, equipment differences, or care pathways; learning socioeconomic segregation itself. These findings challenge the assumption that medical images are neutral biological data. By uncovering how models perceive and exploit these hidden social signatures, this work reframes fairness in medical AI: the goal is no longer only to balance datasets or adjust thresholds, but to interrogate and disentangle the social fingerprints embedded in clinical data itself. Read More
Evaluating Large Language Models on Rare Disease Diagnosis: A Case Study using House M.Dcs.AI updates on arXiv.org arXiv:2511.10912v1 Announce Type: cross
Abstract: Large language models (LLMs) have demonstrated capabilities across diverse domains, yet their performance on rare disease diagnosis from narrative medical cases remains underexplored. We introduce a novel dataset of 176 symptom-diagnosis pairs extracted from House M.D., a medical television series validated for teaching rare disease recognition in medical education. We evaluate four state-of-the-art LLMs such as GPT 4o mini, GPT 5 mini, Gemini 2.5 Flash, and Gemini 2.5 Pro on narrative-based diagnostic reasoning tasks. Results show significant variation in performance, ranging from 16.48% to 38.64% accuracy, with newer model generations demonstrating a 2.3 times improvement. While all models face substantial challenges with rare disease diagnosis, the observed improvement across architectures suggests promising directions for future development. Our educationally validated benchmark establishes baseline performance metrics for narrative medical reasoning and provides a publicly accessible evaluation framework for advancing AI-assisted diagnosis research.
arXiv:2511.10912v1 Announce Type: cross
Abstract: Large language models (LLMs) have demonstrated capabilities across diverse domains, yet their performance on rare disease diagnosis from narrative medical cases remains underexplored. We introduce a novel dataset of 176 symptom-diagnosis pairs extracted from House M.D., a medical television series validated for teaching rare disease recognition in medical education. We evaluate four state-of-the-art LLMs such as GPT 4o mini, GPT 5 mini, Gemini 2.5 Flash, and Gemini 2.5 Pro on narrative-based diagnostic reasoning tasks. Results show significant variation in performance, ranging from 16.48% to 38.64% accuracy, with newer model generations demonstrating a 2.3 times improvement. While all models face substantial challenges with rare disease diagnosis, the observed improvement across architectures suggests promising directions for future development. Our educationally validated benchmark establishes baseline performance metrics for narrative medical reasoning and provides a publicly accessible evaluation framework for advancing AI-assisted diagnosis research. Read More