
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domainscs.AI updates on arXiv.org arXiv:2511.10984v1 Announce Type: cross
Abstract: The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
arXiv:2511.10984v1 Announce Type: cross
Abstract: The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation. Read More
Potential Outcome Rankings for Counterfactual Decision Makingcs.AI updates on arXiv.org arXiv:2511.10776v1 Announce Type: new
Abstract: Counterfactual decision-making in the face of uncertainty involves selecting the optimal action from several alternatives using causal reasoning. Decision-makers often rank expected potential outcomes (or their corresponding utility and desirability) to compare the preferences of candidate actions. In this paper, we study new counterfactual decision-making rules by introducing two new metrics: the probabilities of potential outcome ranking (PoR) and the probability of achieving the best potential outcome (PoB). PoR reveals the most probable ranking of potential outcomes for an individual, and PoB indicates the action most likely to yield the top-ranked outcome for an individual. We then establish identification theorems and derive bounds for these metrics, and present estimation methods. Finally, we perform numerical experiments to illustrate the finite-sample properties of the estimators and demonstrate their application to a real-world dataset.
arXiv:2511.10776v1 Announce Type: new
Abstract: Counterfactual decision-making in the face of uncertainty involves selecting the optimal action from several alternatives using causal reasoning. Decision-makers often rank expected potential outcomes (or their corresponding utility and desirability) to compare the preferences of candidate actions. In this paper, we study new counterfactual decision-making rules by introducing two new metrics: the probabilities of potential outcome ranking (PoR) and the probability of achieving the best potential outcome (PoB). PoR reveals the most probable ranking of potential outcomes for an individual, and PoB indicates the action most likely to yield the top-ranked outcome for an individual. We then establish identification theorems and derive bounds for these metrics, and present estimation methods. Finally, we perform numerical experiments to illustrate the finite-sample properties of the estimators and demonstrate their application to a real-world dataset. Read More
Short-Window Sliding Learning for Real-Time Violence Detection via LLM-based Auto-Labelingcs.AI updates on arXiv.org arXiv:2511.10866v1 Announce Type: cross
Abstract: This paper proposes a Short-Window Sliding Learning framework for real-time violence detection in CCTV footages. Unlike conventional long-video training approaches, the proposed method divides videos into 1-2 second clips and applies Large Language Model (LLM)-based auto-caption labeling to construct fine-grained datasets. Each short clip fully utilizes all frames to preserve temporal continuity, enabling precise recognition of rapid violent events. Experiments demonstrate that the proposed method achieves 95.25% accuracy on RWF-2000 and significantly improves performance on long videos (UCF-Crime: 83.25%), confirming its strong generalization and real-time applicability in intelligent surveillance systems.
arXiv:2511.10866v1 Announce Type: cross
Abstract: This paper proposes a Short-Window Sliding Learning framework for real-time violence detection in CCTV footages. Unlike conventional long-video training approaches, the proposed method divides videos into 1-2 second clips and applies Large Language Model (LLM)-based auto-caption labeling to construct fine-grained datasets. Each short clip fully utilizes all frames to preserve temporal continuity, enabling precise recognition of rapid violent events. Experiments demonstrate that the proposed method achieves 95.25% accuracy on RWF-2000 and significantly improves performance on long videos (UCF-Crime: 83.25%), confirming its strong generalization and real-time applicability in intelligent surveillance systems. Read More
From Efficiency to Adaptivity: A Deeper Look at Adaptive Reasoning in Large Language Modelscs.AI updates on arXiv.org arXiv:2511.10788v1 Announce Type: new
Abstract: Recent advances in large language models (LLMs) have made reasoning a central benchmark for evaluating intelligence. While prior surveys focus on efficiency by examining how to shorten reasoning chains or reduce computation, this view overlooks a fundamental challenge: current LLMs apply uniform reasoning strategies regardless of task complexity, generating long traces for trivial problems while failing to extend reasoning for difficult tasks. This survey reframes reasoning through the lens of {adaptivity}: the capability to allocate reasoning effort based on input characteristics such as difficulty and uncertainty. We make three contributions. First, we formalize deductive, inductive, and abductive reasoning within the LLM context, connecting these classical cognitive paradigms with their algorithmic realizations. Second, we formalize adaptive reasoning as a control-augmented policy optimization problem balancing task performance with computational cost, distinguishing learned policies from inference-time control mechanisms. Third, we propose a systematic taxonomy organizing existing methods into training-based approaches that internalize adaptivity through reinforcement learning, supervised fine-tuning, and learned controllers, and training-free approaches that achieve adaptivity through prompt conditioning, feedback-driven halting, and modular composition. This framework clarifies how different mechanisms realize adaptive reasoning in practice and enables systematic comparison across diverse strategies. We conclude by identifying open challenges in self-evaluation, meta-reasoning, and human-aligned reasoning control.
arXiv:2511.10788v1 Announce Type: new
Abstract: Recent advances in large language models (LLMs) have made reasoning a central benchmark for evaluating intelligence. While prior surveys focus on efficiency by examining how to shorten reasoning chains or reduce computation, this view overlooks a fundamental challenge: current LLMs apply uniform reasoning strategies regardless of task complexity, generating long traces for trivial problems while failing to extend reasoning for difficult tasks. This survey reframes reasoning through the lens of {adaptivity}: the capability to allocate reasoning effort based on input characteristics such as difficulty and uncertainty. We make three contributions. First, we formalize deductive, inductive, and abductive reasoning within the LLM context, connecting these classical cognitive paradigms with their algorithmic realizations. Second, we formalize adaptive reasoning as a control-augmented policy optimization problem balancing task performance with computational cost, distinguishing learned policies from inference-time control mechanisms. Third, we propose a systematic taxonomy organizing existing methods into training-based approaches that internalize adaptivity through reinforcement learning, supervised fine-tuning, and learned controllers, and training-free approaches that achieve adaptivity through prompt conditioning, feedback-driven halting, and modular composition. This framework clarifies how different mechanisms realize adaptive reasoning in practice and enables systematic comparison across diverse strategies. We conclude by identifying open challenges in self-evaluation, meta-reasoning, and human-aligned reasoning control. Read More
HARNESS: Human-Agent Risk Navigation and Event Safety System for Proactive Hazard Forecasting in High-Risk DOE Environmentscs.AI updates on arXiv.org arXiv:2511.10810v1 Announce Type: new
Abstract: Operational safety at mission-critical work sites is a top priority given the complex and hazardous nature of daily tasks. This paper presents the Human-Agent Risk Navigation and Event Safety System (HARNESS), a modular AI framework designed to forecast hazardous events and analyze operational risks in U.S. Department of Energy (DOE) environments. HARNESS integrates Large Language Models (LLMs) with structured work data, historical event retrieval, and risk analysis to proactively identify potential hazards. A human-in-the-loop mechanism allows subject matter experts (SMEs) to refine predictions, creating an adaptive learning loop that enhances performance over time. By combining SME collaboration with iterative agentic reasoning, HARNESS improves the reliability and efficiency of predictive safety systems. Preliminary deployment shows promising results, with future work focusing on quantitative evaluation of accuracy, SME agreement, and decision latency reduction.
arXiv:2511.10810v1 Announce Type: new
Abstract: Operational safety at mission-critical work sites is a top priority given the complex and hazardous nature of daily tasks. This paper presents the Human-Agent Risk Navigation and Event Safety System (HARNESS), a modular AI framework designed to forecast hazardous events and analyze operational risks in U.S. Department of Energy (DOE) environments. HARNESS integrates Large Language Models (LLMs) with structured work data, historical event retrieval, and risk analysis to proactively identify potential hazards. A human-in-the-loop mechanism allows subject matter experts (SMEs) to refine predictions, creating an adaptive learning loop that enhances performance over time. By combining SME collaboration with iterative agentic reasoning, HARNESS improves the reliability and efficiency of predictive safety systems. Preliminary deployment shows promising results, with future work focusing on quantitative evaluation of accuracy, SME agreement, and decision latency reduction. Read More
Stop Worrying about AGI: The Immediate Danger is Reduced General Intelligence (RGI)Towards Data Science Let’s make conscious and deliberate choices when we use AI.
The post Stop Worrying about AGI: The Immediate Danger is Reduced General Intelligence (RGI) appeared first on Towards Data Science.
Let’s make conscious and deliberate choices when we use AI.
The post Stop Worrying about AGI: The Immediate Danger is Reduced General Intelligence (RGI) appeared first on Towards Data Science. Read More
Comparing the Top 4 Agentic AI Browsers in 2025: Atlas vs Copilot Mode vs Dia vs CometMarkTechPost Agentic AI browsers are moving the model from ‘answering about the web’ to operating on the web. In 2025, four AI browsers define this space: OpenAI’s ChatGPT Atlas, Microsoft Edge with Copilot Mode, The Browser Company’s Dia, and Perplexity’s Comet. Each makes different design choices around autonomy, memory, and privacy. This article compares their architectures,
The post Comparing the Top 4 Agentic AI Browsers in 2025: Atlas vs Copilot Mode vs Dia vs Comet appeared first on MarkTechPost.
Agentic AI browsers are moving the model from ‘answering about the web’ to operating on the web. In 2025, four AI browsers define this space: OpenAI’s ChatGPT Atlas, Microsoft Edge with Copilot Mode, The Browser Company’s Dia, and Perplexity’s Comet. Each makes different design choices around autonomy, memory, and privacy. This article compares their architectures,
The post Comparing the Top 4 Agentic AI Browsers in 2025: Atlas vs Copilot Mode vs Dia vs Comet appeared first on MarkTechPost. Read More
How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term AutonomyMarkTechPost In this tutorial, we explore how to build agentic systems that think beyond a single interaction by utilizing memory as a core capability. We walk through how we design episodic memory to store experiences and semantic memory to capture long-term patterns, allowing the agent to evolve its behaviour over multiple sessions. As we implement planning,
The post How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term Autonomy appeared first on MarkTechPost.
In this tutorial, we explore how to build agentic systems that think beyond a single interaction by utilizing memory as a core capability. We walk through how we design episodic memory to store experiences and semantic memory to capture long-term patterns, allowing the agent to evolve its behaviour over multiple sessions. As we implement planning,
The post How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term Autonomy appeared first on MarkTechPost. Read More

Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding AgentsMarkTechPost Cerebras has released MiniMax-M2-REAP-162B-A10B, a compressed Sparse Mixture-of-Experts (SMoE) Causal Language Model derived from MiniMax-M2, using the new Router weighted Expert Activation Pruning (REAP) method. The model keeps the behavior of the original 230B total, 10B active MiniMax M2, while pruning experts and reducing memory for deployment focused workloads such as coding agents and tool
The post Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding Agents appeared first on MarkTechPost.
Cerebras has released MiniMax-M2-REAP-162B-A10B, a compressed Sparse Mixture-of-Experts (SMoE) Causal Language Model derived from MiniMax-M2, using the new Router weighted Expert Activation Pruning (REAP) method. The model keeps the behavior of the original 230B total, 10B active MiniMax M2, while pruning experts and reducing memory for deployment focused workloads such as coding agents and tool
The post Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding Agents appeared first on MarkTechPost. Read More
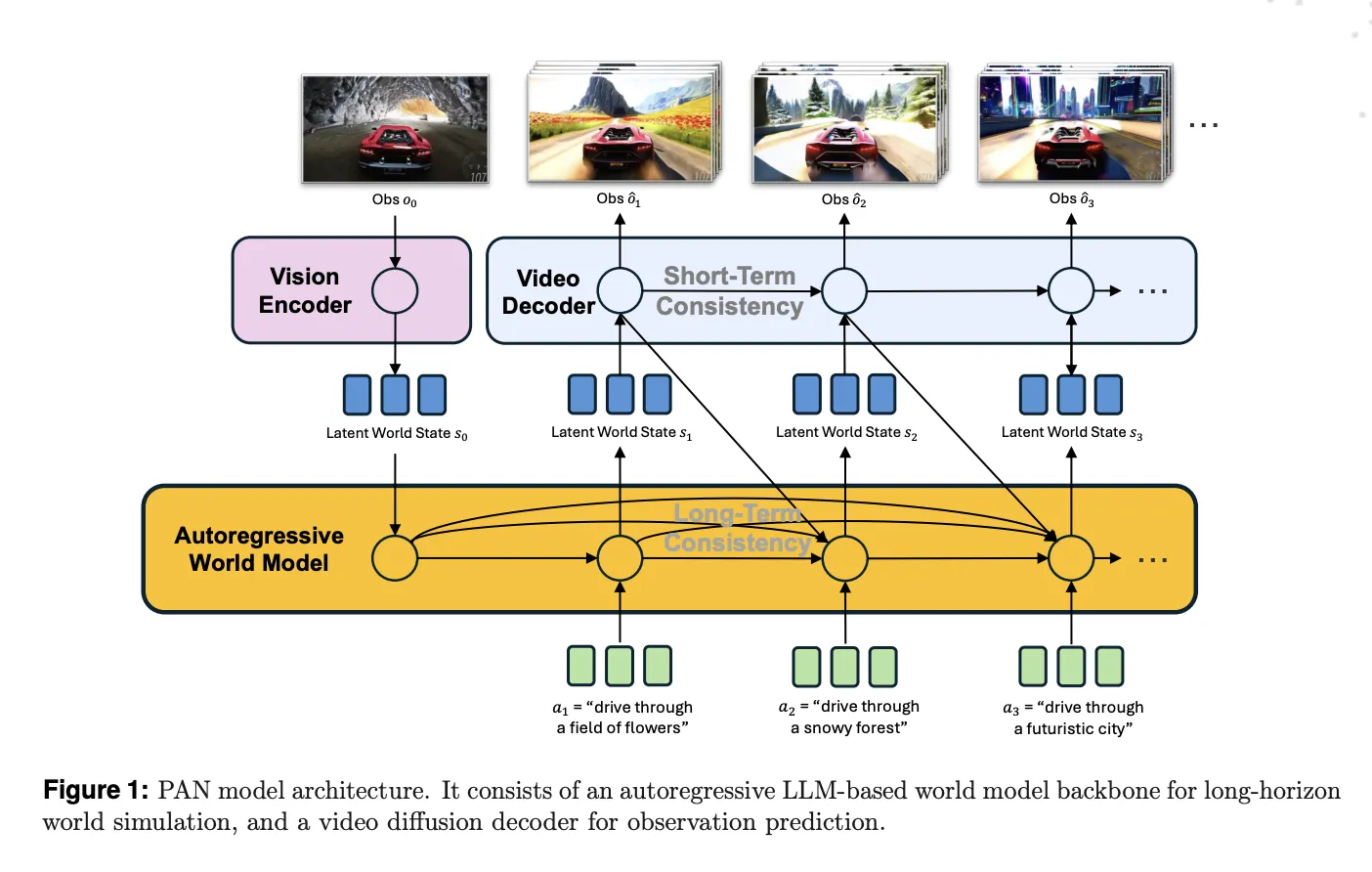
MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon SimulationMarkTechPost Most text to video models generate a single clip from a prompt and then stop. They do not keep an internal world state that persists as actions arrive over time. PAN, a new model from MBZUAI’s Institute of Foundation Models, is designed to fill that gap by acting as a general world model that predicts
The post MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon Simulation appeared first on MarkTechPost.
Most text to video models generate a single clip from a prompt and then stop. They do not keep an internal world state that persists as actions arrive over time. PAN, a new model from MBZUAI’s Institute of Foundation Models, is designed to fill that gap by acting as a general world model that predicts
The post MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon Simulation appeared first on MarkTechPost. Read More