
PreFlect: From Retrospective to Prospective Reflection in Large Language Model Agentscs.AI updates on arXiv.org arXiv:2602.07187v1 Announce Type: new
Abstract: Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect.
arXiv:2602.07187v1 Announce Type: new
Abstract: Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect. Read More
How to Personalize Claude CodeTowards Data Science Learn how to get more out of Claude code by giving it access to more information.
The post How to Personalize Claude Code appeared first on Towards Data Science.
Learn how to get more out of Claude code by giving it access to more information.
The post How to Personalize Claude Code appeared first on Towards Data Science. Read More

Chinese hyperscalers and industry-specific agentic AIAI News Major Chinese technology companies Alibaba, Tencent, and Huawei are pursuing agentic AI (systems that can execute multi-step tasks autonomously and interact with software, data, and services without human instruction), and orienting the technology toward discrete industries and workflows. Alibaba’s open-source strategy for agentic AI Alibaba’s strategy centres on its Qwen AI model family, a set
The post Chinese hyperscalers and industry-specific agentic AI appeared first on AI News.
Major Chinese technology companies Alibaba, Tencent, and Huawei are pursuing agentic AI (systems that can execute multi-step tasks autonomously and interact with software, data, and services without human instruction), and orienting the technology toward discrete industries and workflows. Alibaba’s open-source strategy for agentic AI Alibaba’s strategy centres on its Qwen AI model family, a set
The post Chinese hyperscalers and industry-specific agentic AI appeared first on AI News. Read More

Agentic AI in healthcare: How Life Sciences marketing could achieve US$450bn in value by 2028AI News Agentic AI in healthcare is graduating from answering prompts to autonomously executing complex marketing tasks—and life sciences companies are betting their commercial strategies on it. According to a recent report cited by Capgemini Invent, AI agents could generate up to US$450 billion in economic value through revenue uplift and cost savings globally by 2028, with 69% of
The post Agentic AI in healthcare: How Life Sciences marketing could achieve US$450bn in value by 2028 appeared first on AI News.
Agentic AI in healthcare is graduating from answering prompts to autonomously executing complex marketing tasks—and life sciences companies are betting their commercial strategies on it. According to a recent report cited by Capgemini Invent, AI agents could generate up to US$450 billion in economic value through revenue uplift and cost savings globally by 2028, with 69% of
The post Agentic AI in healthcare: How Life Sciences marketing could achieve US$450bn in value by 2028 appeared first on AI News. Read More
Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Samplingcs.AI updates on arXiv.org arXiv:2601.22636v2 Announce Type: replace
Abstract: Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research.
arXiv:2601.22636v2 Announce Type: replace
Abstract: Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research. Read More
Aster: Autonomous Scientific Discovery over 20x Faster Than Existing Methods AI updates on arXiv.org
Aster: Autonomous Scientific Discovery over 20x Faster Than Existing Methodscs.AI updates on arXiv.org arXiv:2602.07040v1 Announce Type: new
Abstract: We introduce Aster, an AI agent for autonomous scientific discovery capable of operating over 20 times faster than existing frameworks. Given a task, an initial program, and a script to evaluate the performance of the program, Aster iteratively improves the program, often leading to new state-of-the-art performances. Aster’s significant reduction in the number of iterations required for novel discovery expands the domain of tractable problems to include tasks with long evaluation durations, such as multi-hour machine learning training runs.
We applied Aster to problems in mathematics, GPU kernel engineering, biology, neuroscience, and language model training. More specifically: the Erdos minimum overlap problem, optimizing the TriMul kernel, a single-cell analysis denoising problem, training a neural activity prediction model to perform well on ZAPBench, and the NanoGPT Speedrun Competition. Aster attains SOTA results in every task, except for ZAPBench, where it matches the performance of the best human solution with less than 1/190th of the compute.
Aster is accessible via a web interface and API at asterlab.ai.
arXiv:2602.07040v1 Announce Type: new
Abstract: We introduce Aster, an AI agent for autonomous scientific discovery capable of operating over 20 times faster than existing frameworks. Given a task, an initial program, and a script to evaluate the performance of the program, Aster iteratively improves the program, often leading to new state-of-the-art performances. Aster’s significant reduction in the number of iterations required for novel discovery expands the domain of tractable problems to include tasks with long evaluation durations, such as multi-hour machine learning training runs.
We applied Aster to problems in mathematics, GPU kernel engineering, biology, neuroscience, and language model training. More specifically: the Erdos minimum overlap problem, optimizing the TriMul kernel, a single-cell analysis denoising problem, training a neural activity prediction model to perform well on ZAPBench, and the NanoGPT Speedrun Competition. Aster attains SOTA results in every task, except for ZAPBench, where it matches the performance of the best human solution with less than 1/190th of the compute.
Aster is accessible via a web interface and API at asterlab.ai. Read More
Testing ads in ChatGPTOpenAI News OpenAI begins testing ads in ChatGPT to support free access, with clear labeling, answer independence, strong privacy protections, and user control.
OpenAI begins testing ads in ChatGPT to support free access, with clear labeling, answer independence, strong privacy protections, and user control. Read More
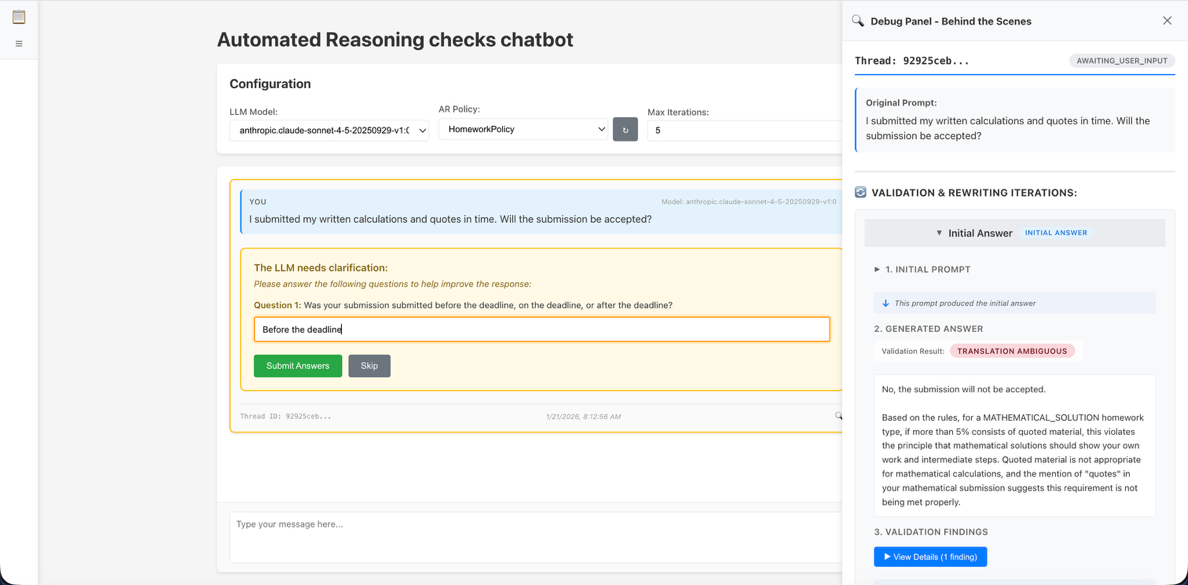
Automated Reasoning checks rewriting chatbot reference implementationArtificial Intelligence This blog post dives deeper into the implementation architecture for the Automated Reasoning checks rewriting chatbot.
This blog post dives deeper into the implementation architecture for the Automated Reasoning checks rewriting chatbot. Read More

Claude Code Power TipsKDnuggets Use Claude Code to speed up data science. Master data cleaning, visualization, and model prototyping with Python, pandas, and scikit-learn. Get actionable power tips.
Use Claude Code to speed up data science. Master data cleaning, visualization, and model prototyping with Python, pandas, and scikit-learn. Get actionable power tips. Read More
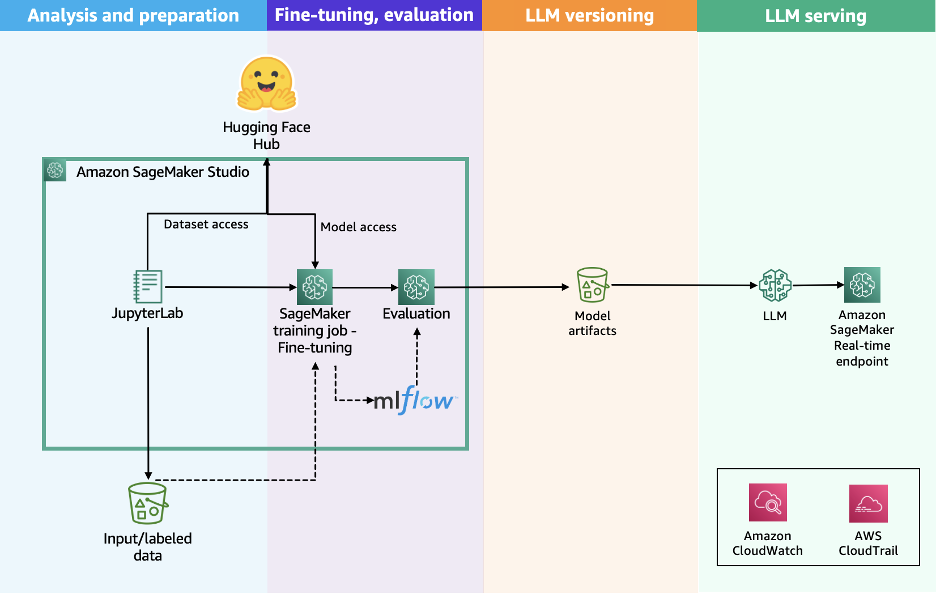
Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AIArtificial Intelligence In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications. Read More