
From Benchmarks to Business Impact: Deploying IBM Generalist Agent in Enterprise Productioncs.AI updates on arXiv.org arXiv:2510.23856v2 Announce Type: replace
Abstract: Agents are rapidly advancing in automating digital work, but enterprises face a harder challenge: moving beyond prototypes to deployed systems that deliver measurable business value. This path is complicated by fragmented frameworks, slow development, and the absence of standardized evaluation practices. Generalist agents have emerged as a promising direction, excelling on academic benchmarks and offering flexibility across task types, applications, and modalities. Yet, evidence of their use in production enterprise settings remains limited. This paper reports IBM’s experience developing and piloting the Computer Using Generalist Agent (CUGA), which has been open-sourced for the community (https://github.com/cuga-project/cuga-agent). CUGA adopts a hierarchical planner–executor architecture with strong analytical foundations, achieving state-of-the-art performance on AppWorld and WebArena. Beyond benchmarks, it was evaluated in a pilot within the Business-Process-Outsourcing talent acquisition domain, addressing enterprise requirements for scalability, auditability, safety, and governance. To support assessment, we introduce BPO-TA, a 26-task benchmark spanning 13 analytics endpoints. In preliminary evaluations, CUGA approached the accuracy of specialized agents while indicating potential for reducing development time and cost. Our contribution is twofold: presenting early evidence of generalist agents operating at enterprise scale, and distilling technical and organizational lessons from this initial pilot. We outline requirements and next steps for advancing research-grade architectures like CUGA into robust, enterprise-ready systems.
arXiv:2510.23856v2 Announce Type: replace
Abstract: Agents are rapidly advancing in automating digital work, but enterprises face a harder challenge: moving beyond prototypes to deployed systems that deliver measurable business value. This path is complicated by fragmented frameworks, slow development, and the absence of standardized evaluation practices. Generalist agents have emerged as a promising direction, excelling on academic benchmarks and offering flexibility across task types, applications, and modalities. Yet, evidence of their use in production enterprise settings remains limited. This paper reports IBM’s experience developing and piloting the Computer Using Generalist Agent (CUGA), which has been open-sourced for the community (https://github.com/cuga-project/cuga-agent). CUGA adopts a hierarchical planner–executor architecture with strong analytical foundations, achieving state-of-the-art performance on AppWorld and WebArena. Beyond benchmarks, it was evaluated in a pilot within the Business-Process-Outsourcing talent acquisition domain, addressing enterprise requirements for scalability, auditability, safety, and governance. To support assessment, we introduce BPO-TA, a 26-task benchmark spanning 13 analytics endpoints. In preliminary evaluations, CUGA approached the accuracy of specialized agents while indicating potential for reducing development time and cost. Our contribution is twofold: presenting early evidence of generalist agents operating at enterprise scale, and distilling technical and organizational lessons from this initial pilot. We outline requirements and next steps for advancing research-grade architectures like CUGA into robust, enterprise-ready systems. Read More
Empowerment Gain and Causal Model Construction: Children and adults are sensitive to controllability and variability in their causal interventionscs.AI updates on arXiv.org arXiv:2512.08230v1 Announce Type: new
Abstract: Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called “empowerment” which maximizes mutual information between actions and their outcomes. “Empowerment” may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions.
arXiv:2512.08230v1 Announce Type: new
Abstract: Learning about the causal structure of the world is a fundamental problem for human cognition. Causal models and especially causal learning have proved to be difficult for large pretrained models using standard techniques of deep learning. In contrast, cognitive scientists have applied advances in our formal understanding of causation in computer science, particularly within the Causal Bayes Net formalism, to understand human causal learning. In the very different tradition of reinforcement learning, researchers have described an intrinsic reward signal called “empowerment” which maximizes mutual information between actions and their outcomes. “Empowerment” may be an important bridge between classical Bayesian causal learning and reinforcement learning and may help to characterize causal learning in humans and enable it in machines. If an agent learns an accurate causal world model, they will necessarily increase their empowerment, and increasing empowerment will lead to a more accurate causal world model. Empowerment may also explain distinctive features of childrens causal learning, as well as providing a more tractable computational account of how that learning is possible. In an empirical study, we systematically test how children and adults use cues to empowerment to infer causal relations, and design effective causal interventions. Read More
Large Language Models for Education and Research: An Empirical and User Survey-based Analysiscs.AI updates on arXiv.org arXiv:2512.08057v1 Announce Type: new
Abstract: Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency- focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research.
arXiv:2512.08057v1 Announce Type: new
Abstract: Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency- focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research. Read More

Inside the playbook of companies winning with AIAI News Many companies are still working out how to use AI in a steady and practical way, but a small group is already pulling ahead. New research from NTT DATA outlines a playbook that shows how these “AI leaders” set themselves apart through strong plans, firm decisions, and a disciplined approach to building and using AI
The post Inside the playbook of companies winning with AI appeared first on AI News.
Many companies are still working out how to use AI in a steady and practical way, but a small group is already pulling ahead. New research from NTT DATA outlines a playbook that shows how these “AI leaders” set themselves apart through strong plans, firm decisions, and a disciplined approach to building and using AI
The post Inside the playbook of companies winning with AI appeared first on AI News. Read More
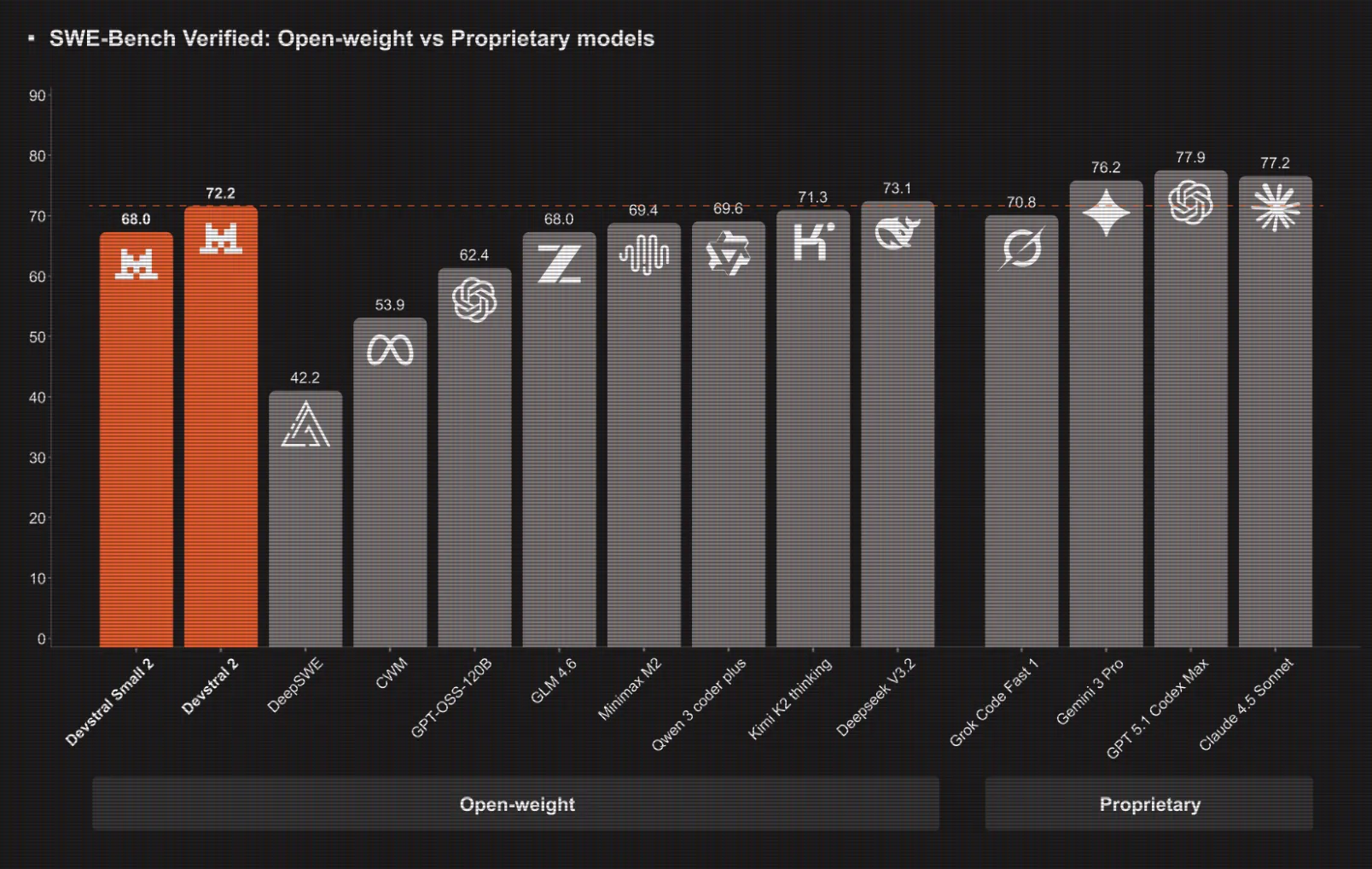
Mistral AI Ships Devstral 2 Coding Models And Mistral Vibe CLI For Agentic, Terminal Native DevelopmentMarkTechPost Mistral AI has introduced Devstral 2, a next generation coding model family for software engineering agents, together with Mistral Vibe CLI, an open source command line coding assistant that runs inside the terminal or IDEs that support the Agent Communication Protocol. Devstral 2 and Devstral Small 2, model sizes, context and benchmarks Devstral 2 is
The post Mistral AI Ships Devstral 2 Coding Models And Mistral Vibe CLI For Agentic, Terminal Native Development appeared first on MarkTechPost.
Mistral AI has introduced Devstral 2, a next generation coding model family for software engineering agents, together with Mistral Vibe CLI, an open source command line coding assistant that runs inside the terminal or IDEs that support the Agent Communication Protocol. Devstral 2 and Devstral Small 2, model sizes, context and benchmarks Devstral 2 is
The post Mistral AI Ships Devstral 2 Coding Models And Mistral Vibe CLI For Agentic, Terminal Native Development appeared first on MarkTechPost. Read More
Arbitrage: Efficient Reasoning via Advantage-Aware Speculationcs.AI updates on arXiv.org arXiv:2512.05033v2 Announce Type: replace-cross
Abstract: Modern Large Language Models achieve impressive reasoning capabilities with long Chain of Thoughts, but they incur substantial computational cost during inference, and this motivates techniques to improve the performance-cost ratio. Among these techniques, Speculative Decoding accelerates inference by employing a fast but inaccurate draft model to autoregressively propose tokens, which are then verified in parallel by a more capable target model. However, due to unnecessary rejections caused by token mismatches in semantically equivalent steps, traditional token-level Speculative Decoding struggles in reasoning tasks. Although recent works have shifted to step-level semantic verification, which improve efficiency by accepting or rejecting entire reasoning steps, existing step-level methods still regenerate many rejected steps with little improvement, wasting valuable target compute. To address this challenge, we propose Arbitrage, a novel step-level speculative generation framework that routes generation dynamically based on the relative advantage between draft and target models. Instead of applying a fixed acceptance threshold, Arbitrage uses a lightweight router trained to predict when the target model is likely to produce a meaningfully better step. This routing approximates an ideal Arbitrage Oracle that always chooses the higher-quality step, achieving near-optimal efficiency-accuracy trade-offs. Across multiple mathematical reasoning benchmarks, Arbitrage consistently surpasses prior step-level Speculative Decoding baselines, reducing inference latency by up to $sim2times$ at matched accuracy.
arXiv:2512.05033v2 Announce Type: replace-cross
Abstract: Modern Large Language Models achieve impressive reasoning capabilities with long Chain of Thoughts, but they incur substantial computational cost during inference, and this motivates techniques to improve the performance-cost ratio. Among these techniques, Speculative Decoding accelerates inference by employing a fast but inaccurate draft model to autoregressively propose tokens, which are then verified in parallel by a more capable target model. However, due to unnecessary rejections caused by token mismatches in semantically equivalent steps, traditional token-level Speculative Decoding struggles in reasoning tasks. Although recent works have shifted to step-level semantic verification, which improve efficiency by accepting or rejecting entire reasoning steps, existing step-level methods still regenerate many rejected steps with little improvement, wasting valuable target compute. To address this challenge, we propose Arbitrage, a novel step-level speculative generation framework that routes generation dynamically based on the relative advantage between draft and target models. Instead of applying a fixed acceptance threshold, Arbitrage uses a lightweight router trained to predict when the target model is likely to produce a meaningfully better step. This routing approximates an ideal Arbitrage Oracle that always chooses the higher-quality step, achieving near-optimal efficiency-accuracy trade-offs. Across multiple mathematical reasoning benchmarks, Arbitrage consistently surpasses prior step-level Speculative Decoding baselines, reducing inference latency by up to $sim2times$ at matched accuracy. Read More
GraphRAG in Practice: How to Build Cost-Efficient, High-Recall Retrieval SystemsTowards Data Science Smarter retrieval strategies that outperform dense graphs — with hybrid pipelines and lower cost
The post GraphRAG in Practice: How to Build Cost-Efficient, High-Recall Retrieval Systems appeared first on Towards Data Science.
Smarter retrieval strategies that outperform dense graphs — with hybrid pipelines and lower cost
The post GraphRAG in Practice: How to Build Cost-Efficient, High-Recall Retrieval Systems appeared first on Towards Data Science. Read More
A Coding Guide to Build a Procedural Memory Agent That Learns, Stores, Retrieves, and Reuses Skills as Neural Modules Over TimeMarkTechPost In this tutorial, we explore how an intelligent agent can gradually form procedural memory by learning reusable skills directly from its interactions with an environment. We design a minimal yet powerful framework in which skills behave like neural modules: they store action sequences, carry contextual embeddings, and are retrieved by similarity when a new situation
The post A Coding Guide to Build a Procedural Memory Agent That Learns, Stores, Retrieves, and Reuses Skills as Neural Modules Over Time appeared first on MarkTechPost.
In this tutorial, we explore how an intelligent agent can gradually form procedural memory by learning reusable skills directly from its interactions with an environment. We design a minimal yet powerful framework in which skills behave like neural modules: they store action sequences, carry contextual embeddings, and are retrieved by similarity when a new situation
The post A Coding Guide to Build a Procedural Memory Agent That Learns, Stores, Retrieves, and Reuses Skills as Neural Modules Over Time appeared first on MarkTechPost. Read More
Google LiteRT NeuroPilot Stack Turns MediaTek Dimensity NPUs into First Class Targets for on Device LLMsMarkTechPost The new LiteRT NeuroPilot Accelerator from Google and MediaTek is a concrete step toward running real generative models on phones, laptops, and IoT hardware without shipping every request to a data center. It takes the existing LiteRT runtime and wires it directly into MediaTek’s NeuroPilot NPU stack, so developers can deploy LLMs and embedding models
The post Google LiteRT NeuroPilot Stack Turns MediaTek Dimensity NPUs into First Class Targets for on Device LLMs appeared first on MarkTechPost.
The new LiteRT NeuroPilot Accelerator from Google and MediaTek is a concrete step toward running real generative models on phones, laptops, and IoT hardware without shipping every request to a data center. It takes the existing LiteRT runtime and wires it directly into MediaTek’s NeuroPilot NPU stack, so developers can deploy LLMs and embedding models
The post Google LiteRT NeuroPilot Stack Turns MediaTek Dimensity NPUs into First Class Targets for on Device LLMs appeared first on MarkTechPost. Read More

Why model distillation is becoming the most important technique in production AIKDnuggets Nebius Token Factory customers use distillation today for search ranking, grammar correction, summarization, chat quality improvement, code refinement, and dozens of other narrow tasks.
Nebius Token Factory customers use distillation today for search ranking, grammar correction, summarization, chat quality improvement, code refinement, and dozens of other narrow tasks. Read More