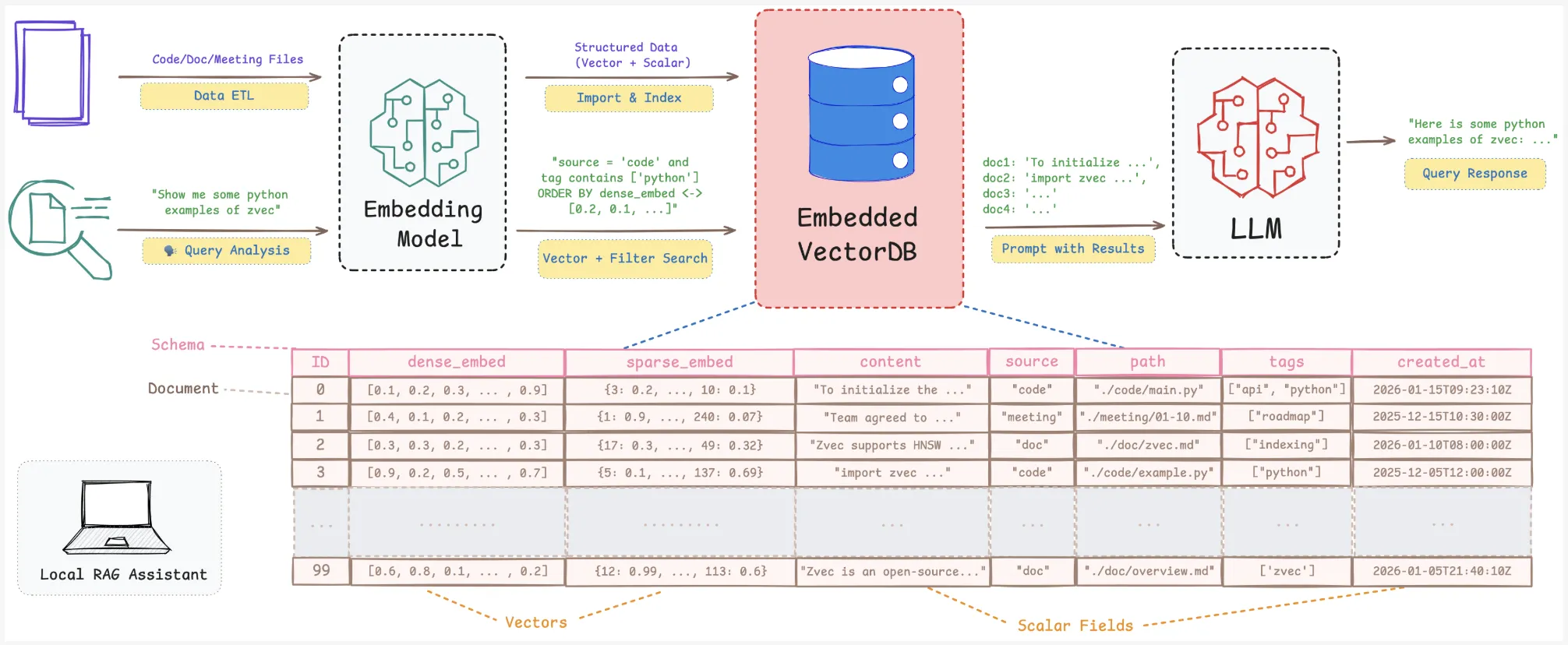
Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-like Simplicity and High-Performance On-Device RAG to Edge ApplicationsMarkTechPost Alibaba Tongyi Lab research team released ‘Zvec’, an open source, in-process vector database that targets edge and on-device retrieval workloads. It is positioned as ‘the SQLite of vector databases’ because it runs as a library inside your application and does not require any external service or daemon. It is designed for retrieval augmented generation (RAG),
The post Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-like Simplicity and High-Performance On-Device RAG to Edge Applications appeared first on MarkTechPost.
Alibaba Tongyi Lab research team released ‘Zvec’, an open source, in-process vector database that targets edge and on-device retrieval workloads. It is positioned as ‘the SQLite of vector databases’ because it runs as a library inside your application and does not require any external service or daemon. It is designed for retrieval augmented generation (RAG),
The post Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-like Simplicity and High-Performance On-Device RAG to Edge Applications appeared first on MarkTechPost. Read More

Building Your Modern Data Analytics Stack with Python, Parquet, and DuckDBKDnuggets Modern data analytics doesn’t have to be complex. Learn how Python, Parquet, and DuckDB work together in practice.
Modern data analytics doesn’t have to be complex. Learn how Python, Parquet, and DuckDB work together in practice. Read More

How to Model The Expected Value of Marketing CampaignsTowards Data Science The approach that takes companies to the next level of data maturity
The post How to Model The Expected Value of Marketing Campaigns appeared first on Towards Data Science.
The approach that takes companies to the next level of data maturity
The post How to Model The Expected Value of Marketing Campaigns appeared first on Towards Data Science. Read More

What Every Small Business Needs to Know About Agentic AIKDnuggets Generative AI, as experienced using traditional chat-style interfaces, has proven to be an incredibly useful tool. Still, it has a major limitation: it sits there and waits for you to type.
Generative AI, as experienced using traditional chat-style interfaces, has proven to be an incredibly useful tool. Still, it has a major limitation: it sits there and waits for you to type. Read More
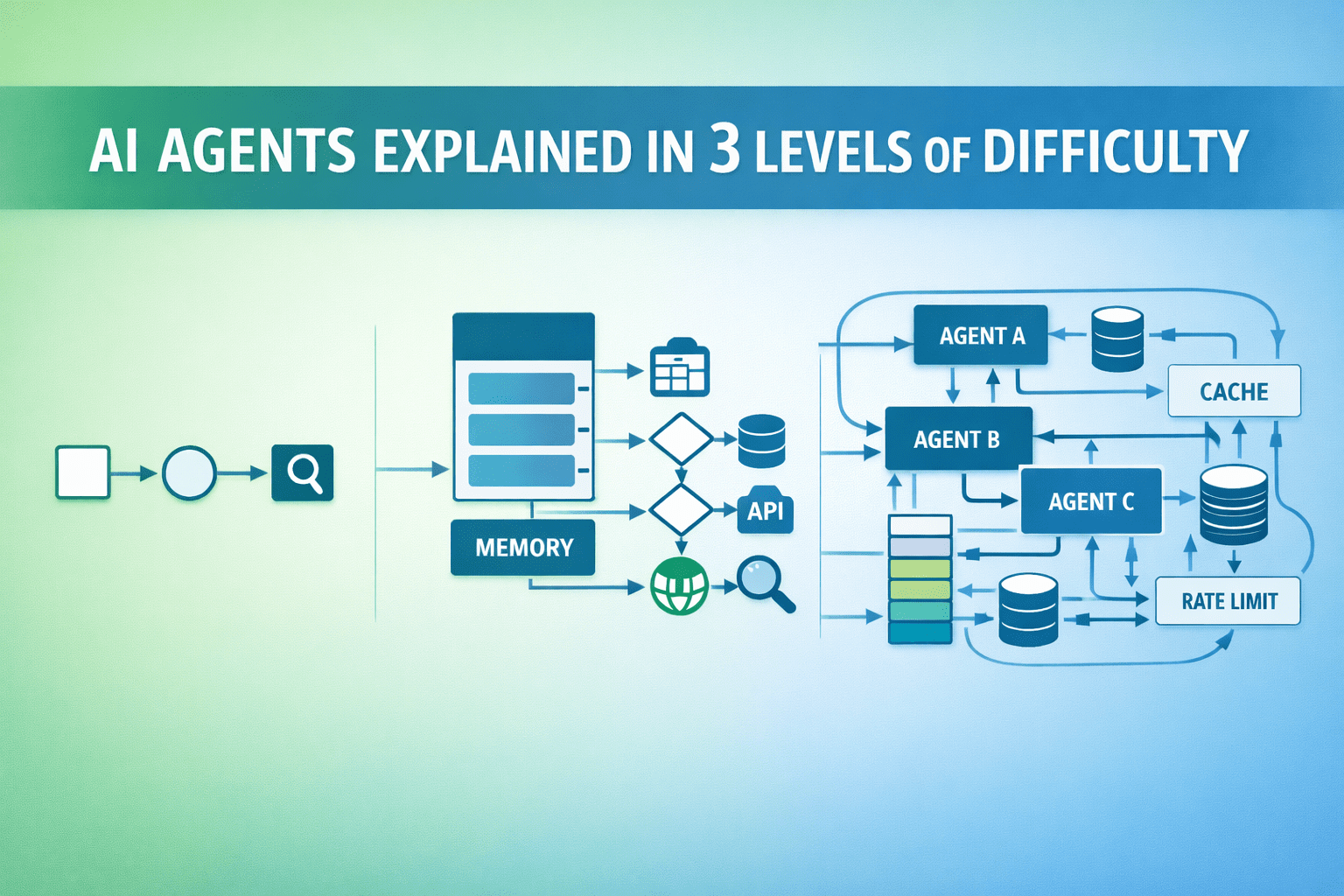
AI Agents Explained in 3 Levels of DifficultyKDnuggets AI agents go beyond single responses to perform tasks autonomously. Here’s a simple breakdown across three levels of difficulty.
AI agents go beyond single responses to perform tasks autonomously. Here’s a simple breakdown across three levels of difficulty. Read More
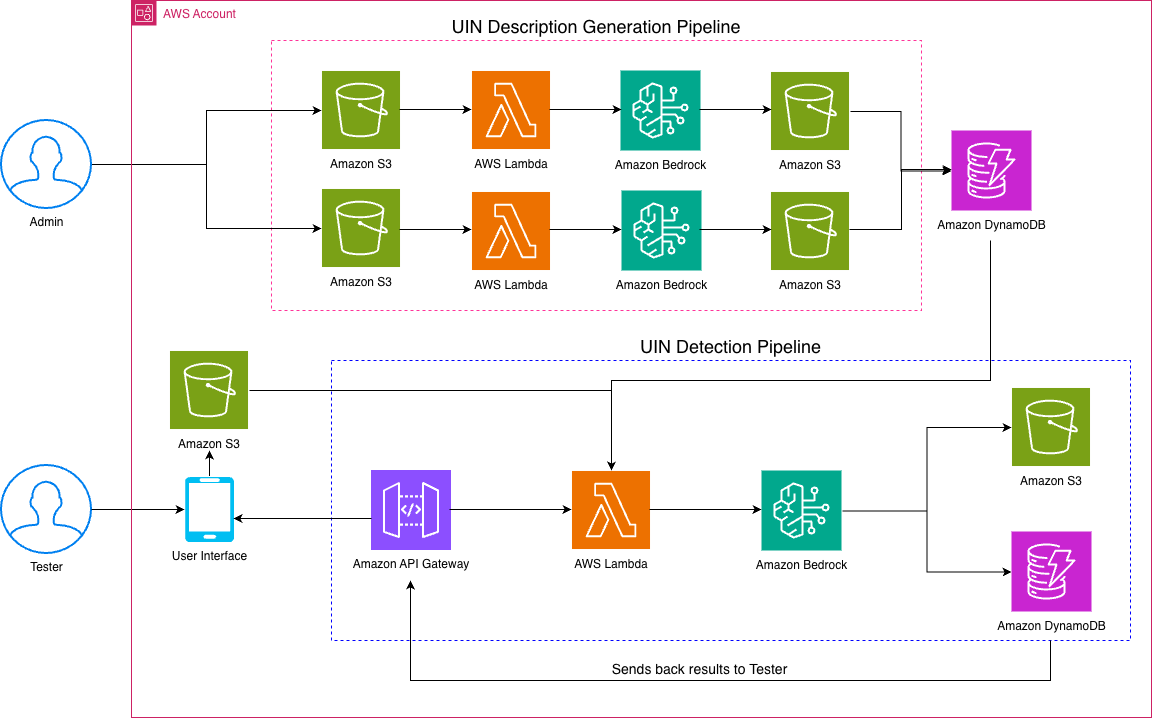
How Amazon uses Amazon Nova models to automate operational readiness testing for new fulfillment centersArtificial Intelligence In this post, we discuss how Amazon Nova in Amazon Bedrock can be used to implement an AI-powered image recognition solution that automates the detection and validation of module components, significantly reducing manual verification efforts and improving accuracy.
In this post, we discuss how Amazon Nova in Amazon Bedrock can be used to implement an AI-powered image recognition solution that automates the detection and validation of module components, significantly reducing manual verification efforts and improving accuracy. Read More
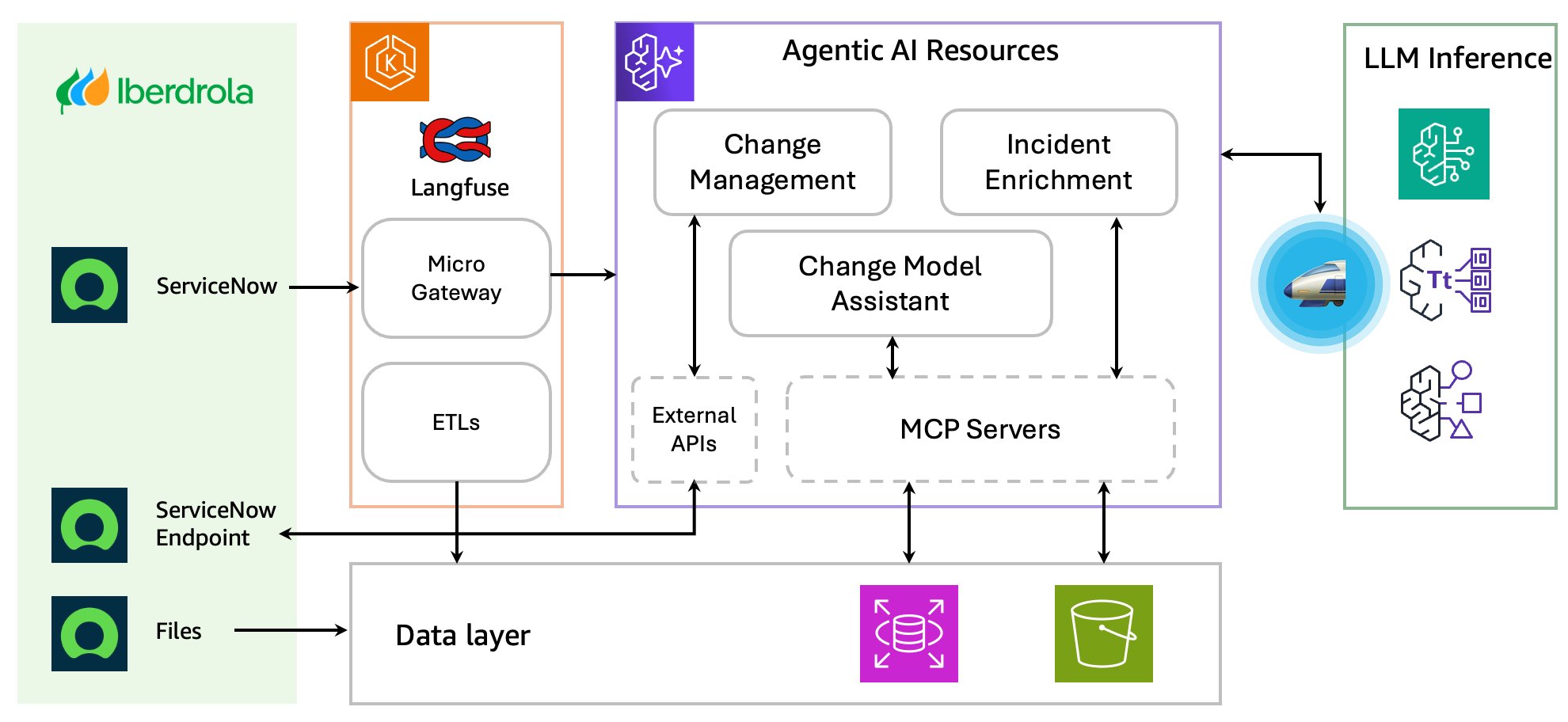
Iberdrola enhances IT operations using Amazon Bedrock AgentCoreArtificial Intelligence Iberdrola, one of the world’s largest utility companies, has embraced cutting-edge AI technology to revolutionize its IT operations in ServiceNow. Through its partnership with AWS, Iberdrola implemented different agentic architectures using Amazon Bedrock AgentCore, targeting three key areas: optimizing change request validation in the draft phase, enriching incident management with contextual intelligence, and simplifying change model selection using conversational AI. These innovations reduce bottlenecks, help teams accelerate ticket resolution, and deliver consistent and high-quality data handling throughout the organization.
Iberdrola, one of the world’s largest utility companies, has embraced cutting-edge AI technology to revolutionize its IT operations in ServiceNow. Through its partnership with AWS, Iberdrola implemented different agentic architectures using Amazon Bedrock AgentCore, targeting three key areas: optimizing change request validation in the draft phase, enriching incident management with contextual intelligence, and simplifying change model selection using conversational AI. These innovations reduce bottlenecks, help teams accelerate ticket resolution, and deliver consistent and high-quality data handling throughout the organization. Read More
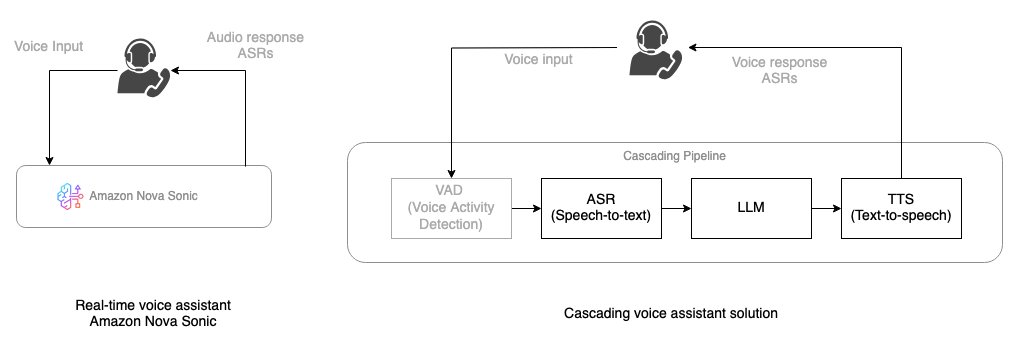
Building real-time voice assistants with Amazon Nova Sonic compared to cascading architecturesArtificial Intelligence Amazon Nova Sonic delivers real-time, human-like voice conversations through the bidirectional streaming interface. In this post, you learn how Amazon Nova Sonic can solve some of the challenges faced by cascaded approaches, simplify building voice AI agents, and provide natural conversational capabilities. We also provide guidance on when to choose each approach to help you make informed decisions for your voice AI projects.
Amazon Nova Sonic delivers real-time, human-like voice conversations through the bidirectional streaming interface. In this post, you learn how Amazon Nova Sonic can solve some of the challenges faced by cascaded approaches, simplify building voice AI agents, and provide natural conversational capabilities. We also provide guidance on when to choose each approach to help you make informed decisions for your voice AI projects. Read More
Is there “Secret Sauce” in Large Language Model Development?cs.AI updates on arXiv.org arXiv:2602.07238v1 Announce Type: new
Abstract: Do leading LLM developers possess a proprietary “secret sauce”, or is LLM performance driven by scaling up compute? Using training and benchmark data for 809 models released between 2022 and 2025, we estimate scaling-law regressions with release-date and developer fixed effects. We find clear evidence of developer-specific efficiency advantages, but their importance depends on where models lie in the performance distribution. At the frontier, 80-90% of performance differences are explained by higher training compute, implying that scale–not proprietary technology–drives frontier advances. Away from the frontier, however, proprietary techniques and shared algorithmic progress substantially reduce the compute required to reach fixed capability thresholds. Some companies can systematically produce smaller models more efficiently. Strikingly, we also find substantial variation of model efficiency within companies; a firm can train two models with more than 40x compute efficiency difference. We also discuss the implications for AI leadership and capability diffusion.
arXiv:2602.07238v1 Announce Type: new
Abstract: Do leading LLM developers possess a proprietary “secret sauce”, or is LLM performance driven by scaling up compute? Using training and benchmark data for 809 models released between 2022 and 2025, we estimate scaling-law regressions with release-date and developer fixed effects. We find clear evidence of developer-specific efficiency advantages, but their importance depends on where models lie in the performance distribution. At the frontier, 80-90% of performance differences are explained by higher training compute, implying that scale–not proprietary technology–drives frontier advances. Away from the frontier, however, proprietary techniques and shared algorithmic progress substantially reduce the compute required to reach fixed capability thresholds. Some companies can systematically produce smaller models more efficiently. Strikingly, we also find substantial variation of model efficiency within companies; a firm can train two models with more than 40x compute efficiency difference. We also discuss the implications for AI leadership and capability diffusion. Read More
Tighnari v2: Mitigating Label Noise and Distribution Shift in Multimodal Plant Distribution Prediction via Mixture of Experts and Weakly Supervised Learningcs.AI updates on arXiv.org arXiv:2602.08282v1 Announce Type: cross
Abstract: Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts.
arXiv:2602.08282v1 Announce Type: cross
Abstract: Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts. Read More