
10 GitHub Repositories to Master Machine Learning DeploymentKDnuggets Master the essential skill of deploying machine learning models with courses, projects, examples, resources, and interview questions.
Master the essential skill of deploying machine learning models with courses, projects, examples, resources, and interview questions. Read More
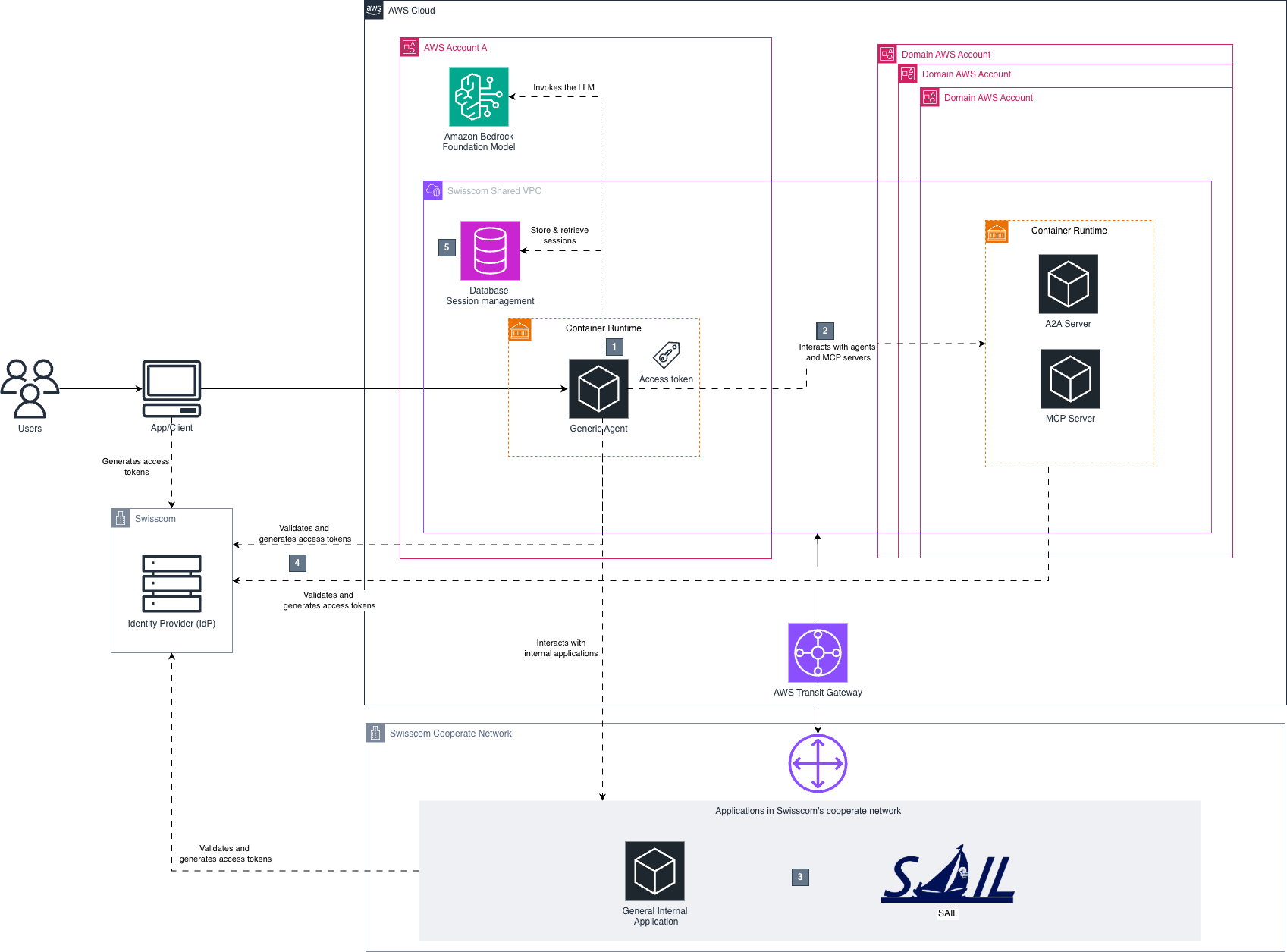
How Swisscom builds enterprise agentic AI for customer support and sales using Amazon Bedrock AgentCoreArtificial Intelligence In this post, we’ll show how Swisscom implemented Amazon Bedrock AgentCore to build and scale their enterprise AI agents for customer support and sales operations. As an early adopter of Amazon Bedrock in the AWS Europe Region (Zurich), Swisscom leads in enterprise AI implementation with their Chatbot Builder system and various AI initiatives. Their successful deployments include Conversational AI powered by Rasa and fine-tuned LLMs on Amazon SageMaker, and the Swisscom Swisscom myAI assistant, built to meet Swiss data protection standards.
In this post, we’ll show how Swisscom implemented Amazon Bedrock AgentCore to build and scale their enterprise AI agents for customer support and sales operations. As an early adopter of Amazon Bedrock in the AWS Europe Region (Zurich), Swisscom leads in enterprise AI implementation with their Chatbot Builder system and various AI initiatives. Their successful deployments include Conversational AI powered by Rasa and fine-tuned LLMs on Amazon SageMaker, and the Swisscom Swisscom myAI assistant, built to meet Swiss data protection standards. Read More
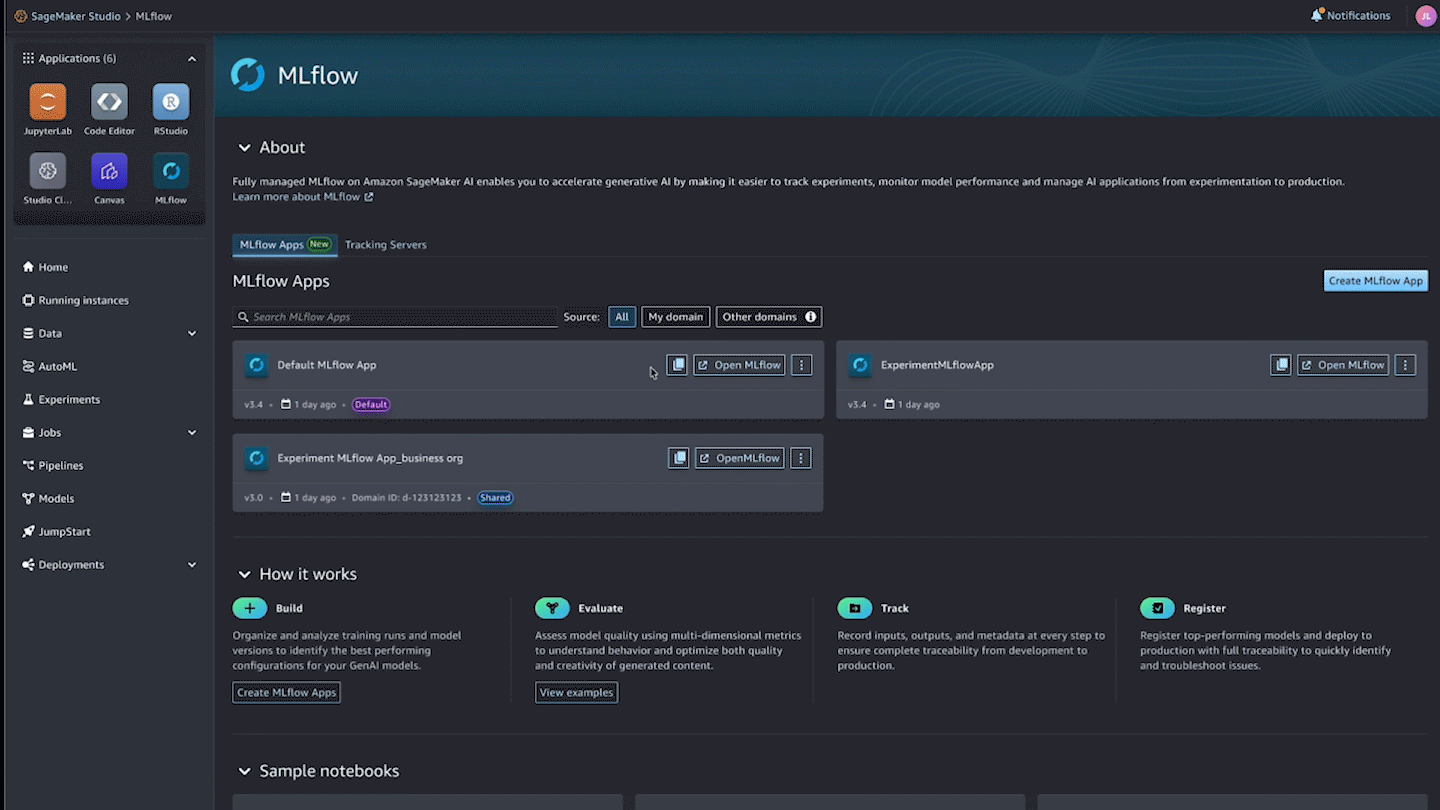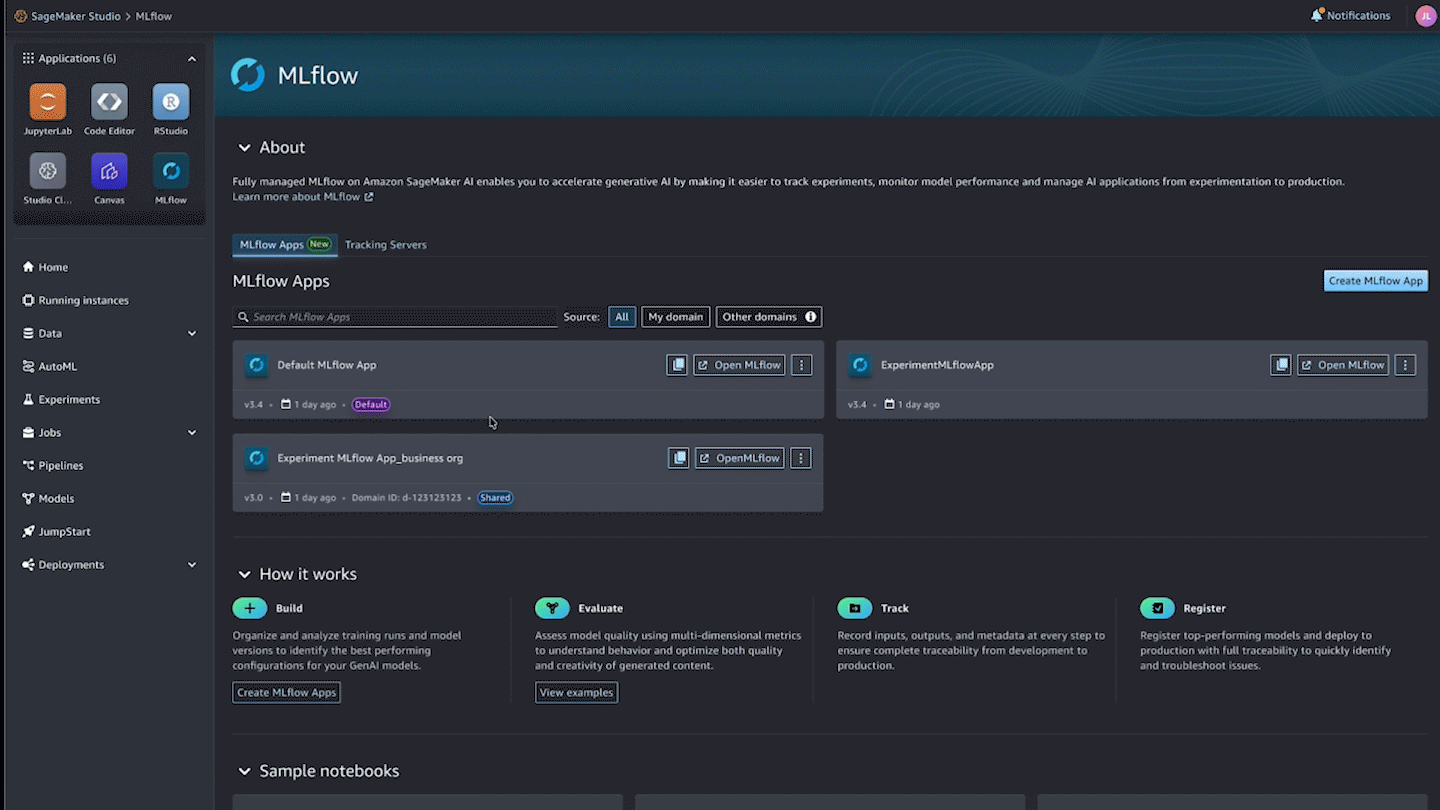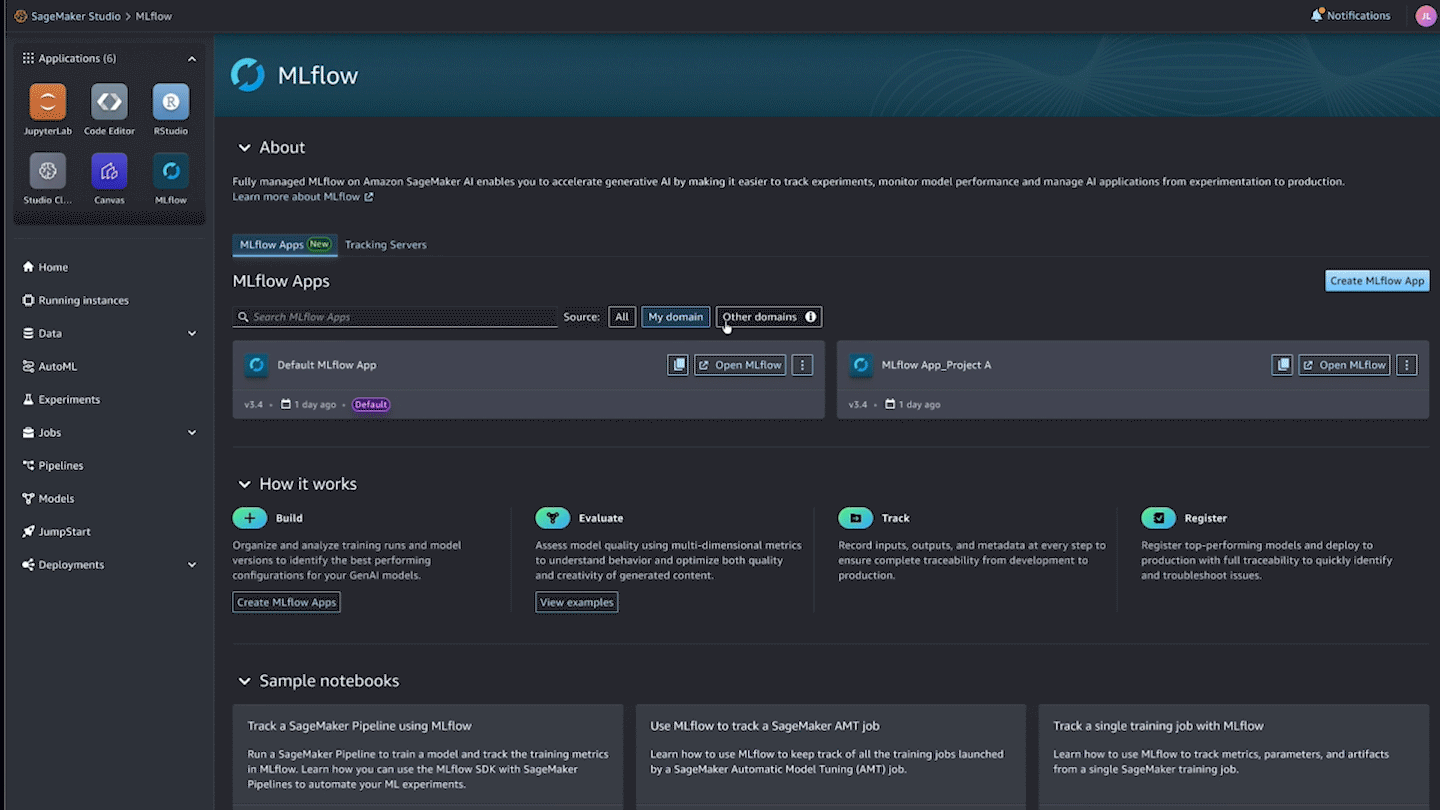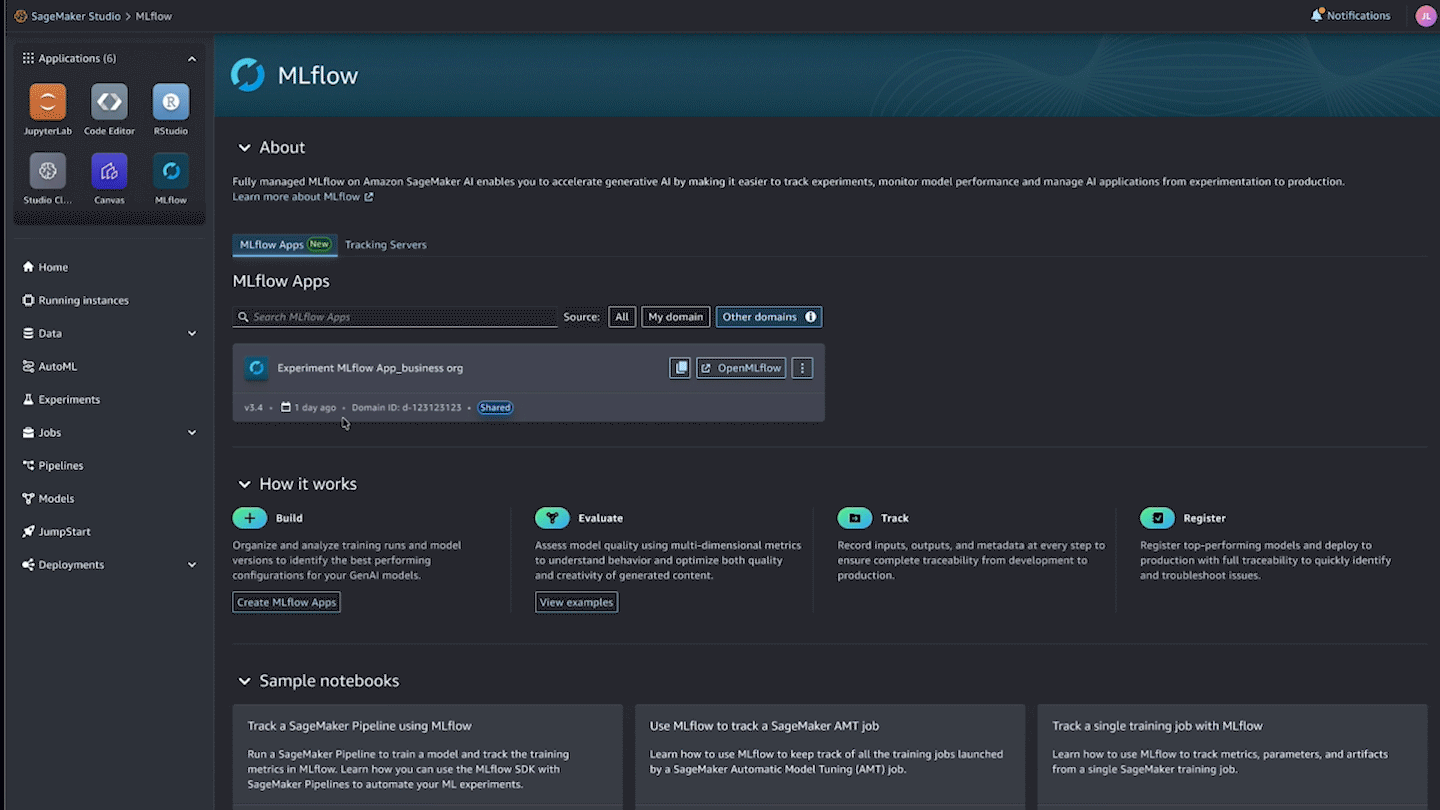
Scaling MLflow for enterprise AI: What’s New in SageMaker AI with MLflowArtificial Intelligence Today we’re announcing Amazon SageMaker AI with MLflow, now including a serverless capability that dynamically manages infrastructure provisioning, scaling, and operations for artificial intelligence and machine learning (AI/ML) development tasks. In this post, we explore how these new capabilities help you run large MLflow workloads—from generative AI agents to large language model (LLM) experimentation—with improved performance, automation, and security using SageMaker AI with MLflow.
Today we’re announcing Amazon SageMaker AI with MLflow, now including a serverless capability that dynamically manages infrastructure provisioning, scaling, and operations for artificial intelligence and machine learning (AI/ML) development tasks. In this post, we explore how these new capabilities help you run large MLflow workloads—from generative AI agents to large language model (LLM) experimentation—with improved performance, automation, and security using SageMaker AI with MLflow. Read More
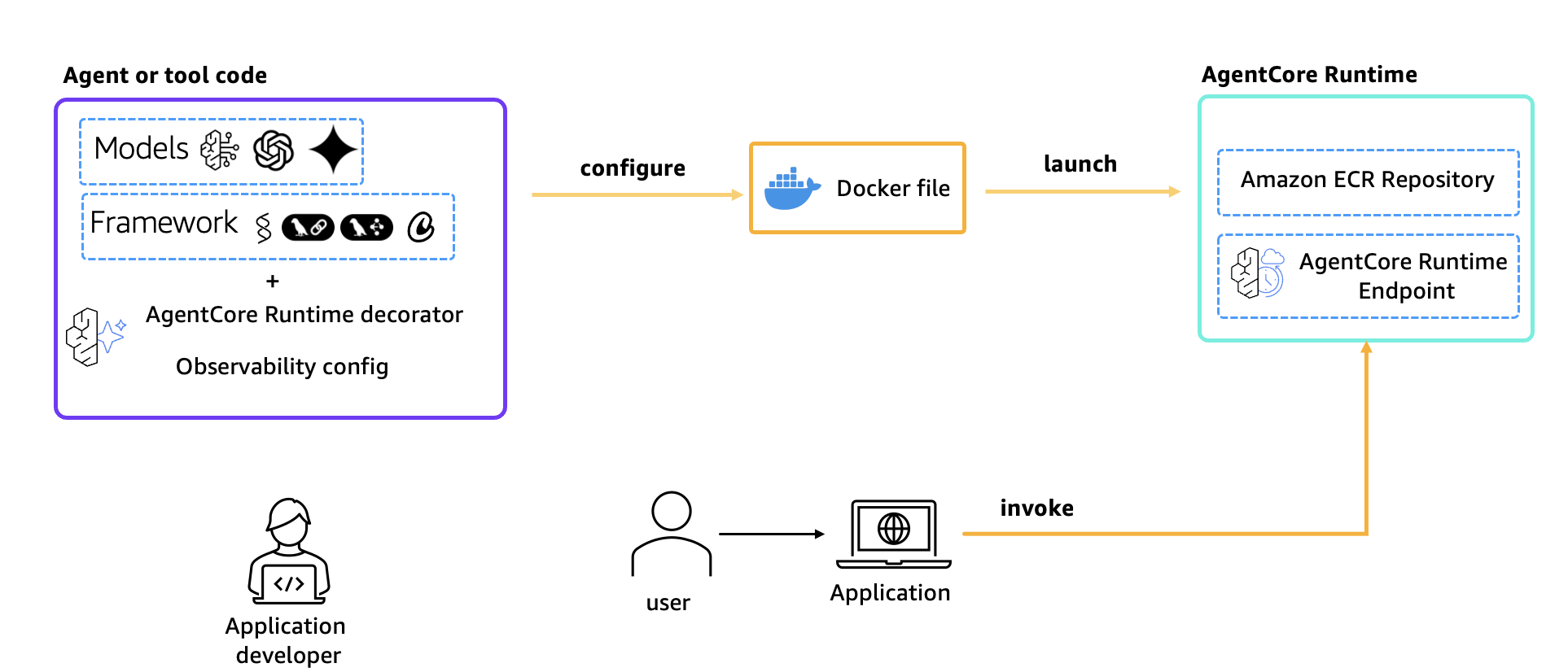
Amazon Bedrock AgentCore Observability with LangfuseArtificial Intelligence In this post, we explain how to integrate Langfuse observability with Amazon Bedrock AgentCore to gain deep visibility into an AI agent’s performance, debug issues faster, and optimize costs. We walk through a complete implementation using Strands agents deployed on AgentCore Runtime followed by step-by-step code examples.
In this post, we explain how to integrate Langfuse observability with Amazon Bedrock AgentCore to gain deep visibility into an AI agent’s performance, debug issues faster, and optimize costs. We walk through a complete implementation using Strands agents deployed on AgentCore Runtime followed by step-by-step code examples. Read More

The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research AdoptionMarkTechPost Los Angeles, December 11, 2025 — Marktechpost has released ML Global Impact Report 2025 (AIResearchTrends.com). This educational report’s analysis includes over 5,000 articles from more than 125 countries, all published within the Nature family of journals between January 1 and September 30, 2025. The scope of this report is strictly confined to this specific body
The post The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research Adoption appeared first on MarkTechPost.
Los Angeles, December 11, 2025 — Marktechpost has released ML Global Impact Report 2025 (AIResearchTrends.com). This educational report’s analysis includes over 5,000 articles from more than 125 countries, all published within the Nature family of journals between January 1 and September 30, 2025. The scope of this report is strictly confined to this specific body
The post The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research Adoption appeared first on MarkTechPost. Read More

7 Steps to Mastering Agentic AIKDnuggets As AI systems begin handling more complex, multi-stage tasks, understanding agentic design is becoming essential. This article outlines seven practical steps to build reliable, effective AI agents.
As AI systems begin handling more complex, multi-stage tasks, understanding agentic design is becoming essential. This article outlines seven practical steps to build reliable, effective AI agents. Read More

The Machine Learning “Advent Calendar” Day 11: Linear Regression in ExcelTowards Data Science Linear Regression looks simple, but it introduces the core ideas of modern machine learning: loss functions, optimization, gradients, scaling, and interpretation.
In this article, we rebuild Linear Regression in Excel, compare the closed-form solution with Gradient Descent, and see how the coefficients evolve step by step.
This foundation naturally leads to regularization, kernels, classification, and the dual view.
Linear Regression is not just a straight line, but the starting point for many models we will explore next in the Advent Calendar.
The post The Machine Learning “Advent Calendar” Day 11: Linear Regression in Excel appeared first on Towards Data Science.
Linear Regression looks simple, but it introduces the core ideas of modern machine learning: loss functions, optimization, gradients, scaling, and interpretation.
In this article, we rebuild Linear Regression in Excel, compare the closed-form solution with Gradient Descent, and see how the coefficients evolve step by step.
This foundation naturally leads to regularization, kernels, classification, and the dual view.
Linear Regression is not just a straight line, but the starting point for many models we will explore next in the Advent Calendar.
The post The Machine Learning “Advent Calendar” Day 11: Linear Regression in Excel appeared first on Towards Data Science. Read More

Microsoft ‘Promptions’ fix AI prompts failing to deliverAI News Microsoft believes it has a fix for AI prompts being given, the response missing the mark, and the cycle repeating. This inefficiency is a drain on resources. The “trial-and-error loop can feel unpredictable and discouraging,” turning what should be a productivity booster into a time sink. Knowledge workers often spend more time managing the interaction
The post Microsoft ‘Promptions’ fix AI prompts failing to deliver appeared first on AI News.
Microsoft believes it has a fix for AI prompts being given, the response missing the mark, and the cycle repeating. This inefficiency is a drain on resources. The “trial-and-error loop can feel unpredictable and discouraging,” turning what should be a productivity booster into a time sink. Knowledge workers often spend more time managing the interaction
The post Microsoft ‘Promptions’ fix AI prompts failing to deliver appeared first on AI News. Read More
7 Pandas Performance Tricks Every Data Scientist Should KnowTowards Data Science What I’ve learned about making Pandas faster after too many slow notebooks and frozen sessions
The post 7 Pandas Performance Tricks Every Data Scientist Should Know appeared first on Towards Data Science.
What I’ve learned about making Pandas faster after too many slow notebooks and frozen sessions
The post 7 Pandas Performance Tricks Every Data Scientist Should Know appeared first on Towards Data Science. Read More
How Agent Handoffs Work in Multi-Agent SystemsTowards Data Science Understanding how LLM agents transfer control to each other in a multi-agent system with LangGraph
The post How Agent Handoffs Work in Multi-Agent Systems appeared first on Towards Data Science.
Understanding how LLM agents transfer control to each other in a multi-agent system with LangGraph
The post How Agent Handoffs Work in Multi-Agent Systems appeared first on Towards Data Science. Read More