
Distributionally Robust Control with End-to-End Statistically Guaranteed Metric Learningcs.AI updates on arXiv.org arXiv:2510.10214v1 Announce Type: cross
Abstract: Wasserstein distributionally robust control (DRC) recently emerges as a principled paradigm for handling uncertainty in stochastic dynamical systems. However, it constructs data-driven ambiguity sets via uniform distribution shifts before sequentially incorporating them into downstream control synthesis. This segregation between ambiguity set construction and control objectives inherently introduces a structural misalignment, which undesirably leads to conservative control policies with sub-optimal performance. To address this limitation, we propose a novel end-to-end finite-horizon Wasserstein DRC framework that integrates the learning of anisotropic Wasserstein metrics with downstream control tasks in a closed-loop manner, thus enabling ambiguity sets to be systematically adjusted along performance-critical directions and yielding more effective control policies. This framework is formulated as a bilevel program: the inner level characterizes dynamical system evolution under DRC, while the outer level refines the anisotropic metric leveraging control-performance feedback across a range of initial conditions. To solve this program efficiently, we develop a stochastic augmented Lagrangian algorithm tailored to the bilevel structure. Theoretically, we prove that the learned ambiguity sets preserve statistical finite-sample guarantees under a novel radius adjustment mechanism, and we establish the well-posedness of the bilevel formulation by demonstrating its continuity with respect to the learnable metric. Furthermore, we show that the algorithm converges to stationary points of the outer level problem, which are statistically consistent with the optimal metric at a non-asymptotic convergence rate. Experiments on both numerical and inventory control tasks verify that the proposed framework achieves superior closed-loop performance and robustness compared against state-of-the-art methods.
arXiv:2510.10214v1 Announce Type: cross
Abstract: Wasserstein distributionally robust control (DRC) recently emerges as a principled paradigm for handling uncertainty in stochastic dynamical systems. However, it constructs data-driven ambiguity sets via uniform distribution shifts before sequentially incorporating them into downstream control synthesis. This segregation between ambiguity set construction and control objectives inherently introduces a structural misalignment, which undesirably leads to conservative control policies with sub-optimal performance. To address this limitation, we propose a novel end-to-end finite-horizon Wasserstein DRC framework that integrates the learning of anisotropic Wasserstein metrics with downstream control tasks in a closed-loop manner, thus enabling ambiguity sets to be systematically adjusted along performance-critical directions and yielding more effective control policies. This framework is formulated as a bilevel program: the inner level characterizes dynamical system evolution under DRC, while the outer level refines the anisotropic metric leveraging control-performance feedback across a range of initial conditions. To solve this program efficiently, we develop a stochastic augmented Lagrangian algorithm tailored to the bilevel structure. Theoretically, we prove that the learned ambiguity sets preserve statistical finite-sample guarantees under a novel radius adjustment mechanism, and we establish the well-posedness of the bilevel formulation by demonstrating its continuity with respect to the learnable metric. Furthermore, we show that the algorithm converges to stationary points of the outer level problem, which are statistically consistent with the optimal metric at a non-asymptotic convergence rate. Experiments on both numerical and inventory control tasks verify that the proposed framework achieves superior closed-loop performance and robustness compared against state-of-the-art methods. Read More
Combo-Gait: Unified Transformer Framework for Multi-Modal Gait Recognition and Attribute Analysiscs.AI updates on arXiv.org arXiv:2510.10417v1 Announce Type: cross
Abstract: Gait recognition is an important biometric for human identification at a distance, particularly under low-resolution or unconstrained environments. Current works typically focus on either 2D representations (e.g., silhouettes and skeletons) or 3D representations (e.g., meshes and SMPLs), but relying on a single modality often fails to capture the full geometric and dynamic complexity of human walking patterns. In this paper, we propose a multi-modal and multi-task framework that combines 2D temporal silhouettes with 3D SMPL features for robust gait analysis. Beyond identification, we introduce a multitask learning strategy that jointly performs gait recognition and human attribute estimation, including age, body mass index (BMI), and gender. A unified transformer is employed to effectively fuse multi-modal gait features and better learn attribute-related representations, while preserving discriminative identity cues. Extensive experiments on the large-scale BRIAR datasets, collected under challenging conditions such as long-range distances (up to 1 km) and extreme pitch angles (up to 50{deg}), demonstrate that our approach outperforms state-of-the-art methods in gait recognition and provides accurate human attribute estimation. These results highlight the promise of multi-modal and multitask learning for advancing gait-based human understanding in real-world scenarios.
arXiv:2510.10417v1 Announce Type: cross
Abstract: Gait recognition is an important biometric for human identification at a distance, particularly under low-resolution or unconstrained environments. Current works typically focus on either 2D representations (e.g., silhouettes and skeletons) or 3D representations (e.g., meshes and SMPLs), but relying on a single modality often fails to capture the full geometric and dynamic complexity of human walking patterns. In this paper, we propose a multi-modal and multi-task framework that combines 2D temporal silhouettes with 3D SMPL features for robust gait analysis. Beyond identification, we introduce a multitask learning strategy that jointly performs gait recognition and human attribute estimation, including age, body mass index (BMI), and gender. A unified transformer is employed to effectively fuse multi-modal gait features and better learn attribute-related representations, while preserving discriminative identity cues. Extensive experiments on the large-scale BRIAR datasets, collected under challenging conditions such as long-range distances (up to 1 km) and extreme pitch angles (up to 50{deg}), demonstrate that our approach outperforms state-of-the-art methods in gait recognition and provides accurate human attribute estimation. These results highlight the promise of multi-modal and multitask learning for advancing gait-based human understanding in real-world scenarios. Read More
The algorithmic regulatorcs.AI updates on arXiv.org arXiv:2510.10300v1 Announce Type: cross
Abstract: The regulator theorem states that, under certain conditions, any optimal controller must embody a model of the system it regulates, grounding the idea that controllers embed, explicitly or implicitly, internal models of the controlled. This principle underpins neuroscience and predictive brain theories like the Free-Energy Principle or Kolmogorov/Algorithmic Agent theory. However, the theorem is only proven in limited settings. Here, we treat the deterministic, closed, coupled world-regulator system $(W,R)$ as a single self-delimiting program $p$ via a constant-size wrapper that produces the world output string~$x$ fed to the regulator. We analyze regulation from the viewpoint of the algorithmic complexity of the output, $K(x)$. We define $R$ to be a emph{good algorithmic regulator} if it emph{reduces} the algorithmic complexity of the readout relative to a null (unregulated) baseline $varnothing$, i.e., [ Delta = Kbig(O_{W,varnothing}big) – Kbig(O_{W,R}big) > 0. ] We then prove that the larger $Delta$ is, the more world-regulator pairs with high mutual algorithmic information are favored. More precisely, a complexity gap $Delta > 0$ yields [ Prbig((W,R)mid xbig) le C,2^{,M(W{:}R)},2^{-Delta}, ] making low $M(W{:}R)$ exponentially unlikely as $Delta$ grows. This is an AIT version of the idea that “the regulator contains a model of the world.” The framework is distribution-free, applies to individual sequences, and complements the Internal Model Principle. Beyond this necessity claim, the same coding-theorem calculus singles out a emph{canonical scalar objective} and implicates a emph{planner}. On the realized episode, a regulator behaves emph{as if} it minimized the conditional description length of the readout.
arXiv:2510.10300v1 Announce Type: cross
Abstract: The regulator theorem states that, under certain conditions, any optimal controller must embody a model of the system it regulates, grounding the idea that controllers embed, explicitly or implicitly, internal models of the controlled. This principle underpins neuroscience and predictive brain theories like the Free-Energy Principle or Kolmogorov/Algorithmic Agent theory. However, the theorem is only proven in limited settings. Here, we treat the deterministic, closed, coupled world-regulator system $(W,R)$ as a single self-delimiting program $p$ via a constant-size wrapper that produces the world output string~$x$ fed to the regulator. We analyze regulation from the viewpoint of the algorithmic complexity of the output, $K(x)$. We define $R$ to be a emph{good algorithmic regulator} if it emph{reduces} the algorithmic complexity of the readout relative to a null (unregulated) baseline $varnothing$, i.e., [ Delta = Kbig(O_{W,varnothing}big) – Kbig(O_{W,R}big) > 0. ] We then prove that the larger $Delta$ is, the more world-regulator pairs with high mutual algorithmic information are favored. More precisely, a complexity gap $Delta > 0$ yields [ Prbig((W,R)mid xbig) le C,2^{,M(W{:}R)},2^{-Delta}, ] making low $M(W{:}R)$ exponentially unlikely as $Delta$ grows. This is an AIT version of the idea that “the regulator contains a model of the world.” The framework is distribution-free, applies to individual sequences, and complements the Internal Model Principle. Beyond this necessity claim, the same coding-theorem calculus singles out a emph{canonical scalar objective} and implicates a emph{planner}. On the realized episode, a regulator behaves emph{as if} it minimized the conditional description length of the readout. Read More

10 Useful Python One-Liners for CSV ProcessingKDnuggets Working with CSVs? These Python one-liners make common file operations faster and cleaner.
Working with CSVs? These Python one-liners make common file operations faster and cleaner. Read More

Data Analytics Automation Scripts with SQL Stored ProceduresKDnuggets Simplify your query with reusable executed scripts.
Simplify your query with reusable executed scripts. Read More
The Beginner’s Guide to Tracking Token Usage in LLM AppsKDnuggets If you’re not tracking tokens, you’re basically burning cash every time your app talks to an LLM.
If you’re not tracking tokens, you’re basically burning cash every time your app talks to an LLM. Read More

5 Signs Your Business Is Ready For AI (Sponsored)KDnuggets How do you know if you’re ready to take the AI plunge? Here are five dead giveaways that AI could transform how you work.
How do you know if you’re ready to take the AI plunge? Here are five dead giveaways that AI could transform how you work. Read More

Here’s When You Would Choose Spreadsheets Over SQLKDnuggets Spreadsheets might seem obsolete in the world of relational databases. They’re not! Here are situations when spreadsheets easily topple SQL.
Spreadsheets might seem obsolete in the world of relational databases. They’re not! Here are situations when spreadsheets easily topple SQL. Read More
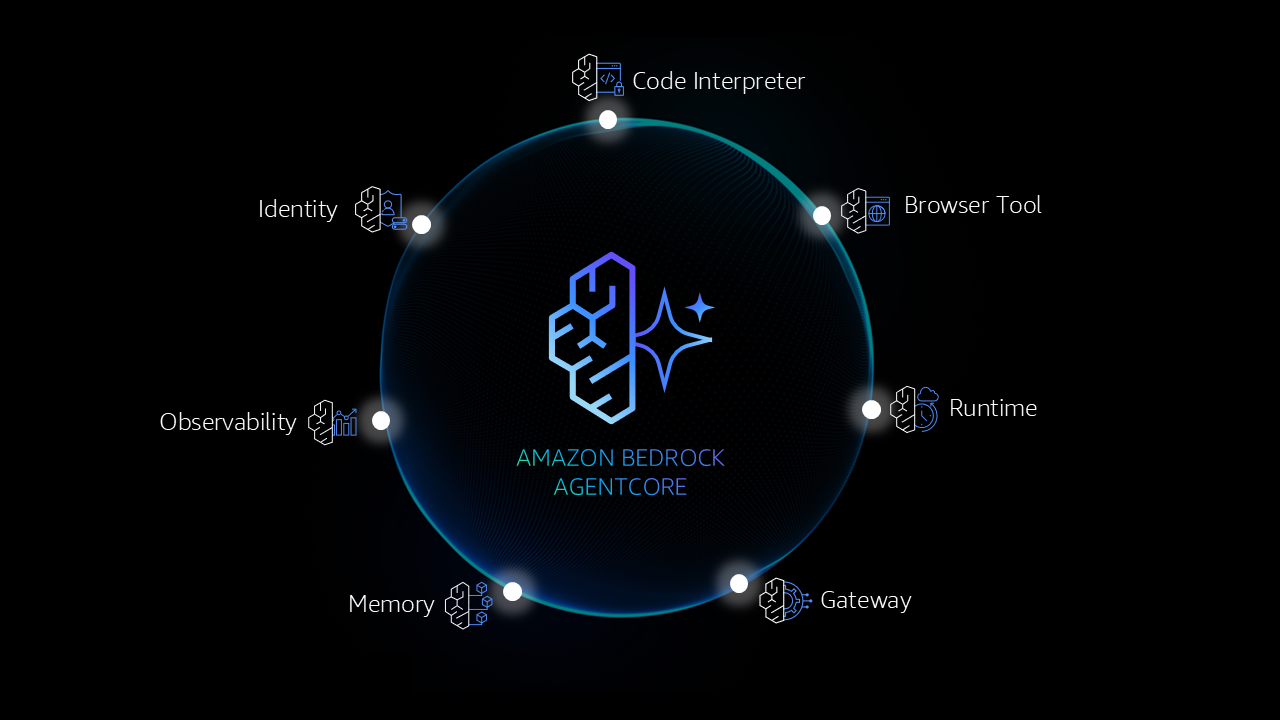
Make agents a reality with Amazon Bedrock AgentCore: Now generally availableArtificial Intelligence Learn why customers choose AgentCore to build secure, reliable AI solutions using their choice of frameworks and models for production workloads.
Learn why customers choose AgentCore to build secure, reliable AI solutions using their choice of frameworks and models for production workloads. Read More
What Is Your Agent’s GPA? A Framework for Evaluating Agent Goal-Plan-Action Alignmentcs.AI updates on arXiv.org arXiv:2510.08847v1 Announce Type: new
Abstract: We introduce the Agent GPA (Goal-Plan-Action) framework: an evaluation paradigm based on an agent’s operational loop of setting goals, devising plans, and executing actions. The framework includes five evaluation metrics: Goal Fulfillment, Logical Consistency, Execution Efficiency, Plan Quality, and Plan Adherence. Logical Consistency checks that an agent’s actions are consistent with its prior actions. Execution Efficiency checks whether the agent executes in the most efficient way to achieve its goal. Plan Quality checks whether an agent’s plans are aligned with its goals; Plan Adherence checks if an agent’s actions are aligned with its plan; and Goal Fulfillment checks that agent’s final outcomes match the stated goals. Our experimental results on two benchmark datasets – the public TRAIL/GAIA dataset and an internal dataset for a production-grade data agent – show that this framework (a) provides a systematic way to cover a broad range of agent failures, including all agent errors on the TRAIL/GAIA benchmark dataset; (b) supports LLM-judges that exhibit strong agreement with human annotation, covering 80% to over 95% errors; and (c) localizes errors with 86% agreement to enable targeted improvement of agent performance.
arXiv:2510.08847v1 Announce Type: new
Abstract: We introduce the Agent GPA (Goal-Plan-Action) framework: an evaluation paradigm based on an agent’s operational loop of setting goals, devising plans, and executing actions. The framework includes five evaluation metrics: Goal Fulfillment, Logical Consistency, Execution Efficiency, Plan Quality, and Plan Adherence. Logical Consistency checks that an agent’s actions are consistent with its prior actions. Execution Efficiency checks whether the agent executes in the most efficient way to achieve its goal. Plan Quality checks whether an agent’s plans are aligned with its goals; Plan Adherence checks if an agent’s actions are aligned with its plan; and Goal Fulfillment checks that agent’s final outcomes match the stated goals. Our experimental results on two benchmark datasets – the public TRAIL/GAIA dataset and an internal dataset for a production-grade data agent – show that this framework (a) provides a systematic way to cover a broad range of agent failures, including all agent errors on the TRAIL/GAIA benchmark dataset; (b) supports LLM-judges that exhibit strong agreement with human annotation, covering 80% to over 95% errors; and (c) localizes errors with 86% agreement to enable targeted improvement of agent performance. Read More