
Mortar: Evolving Mechanics for Automatic Game Designcs.AI updates on arXiv.org arXiv:2601.00105v1 Announce Type: new
Abstract: We present Mortar, a system for autonomously evolving game mechanics for automatic game design. Game mechanics define the rules and interactions that govern gameplay, and designing them manually is a time-consuming and expert-driven process. Mortar combines a quality-diversity algorithm with a large language model to explore a diverse set of mechanics, which are evaluated by synthesising complete games that incorporate both evolved mechanics and those drawn from an archive. The mechanics are evaluated by composing complete games through a tree search procedure, where the resulting games are evaluated by their ability to preserve a skill-based ordering over players — that is, whether stronger players consistently outperform weaker ones. We assess the mechanics based on their contribution towards the skill-based ordering score in the game. We demonstrate that Mortar produces games that appear diverse and playable, and mechanics that contribute more towards the skill-based ordering score in the game. We perform ablation studies to assess the role of each system component and a user study to evaluate the games based on human feedback.
arXiv:2601.00105v1 Announce Type: new
Abstract: We present Mortar, a system for autonomously evolving game mechanics for automatic game design. Game mechanics define the rules and interactions that govern gameplay, and designing them manually is a time-consuming and expert-driven process. Mortar combines a quality-diversity algorithm with a large language model to explore a diverse set of mechanics, which are evaluated by synthesising complete games that incorporate both evolved mechanics and those drawn from an archive. The mechanics are evaluated by composing complete games through a tree search procedure, where the resulting games are evaluated by their ability to preserve a skill-based ordering over players — that is, whether stronger players consistently outperform weaker ones. We assess the mechanics based on their contribution towards the skill-based ordering score in the game. We demonstrate that Mortar produces games that appear diverse and playable, and mechanics that contribute more towards the skill-based ordering score in the game. We perform ablation studies to assess the role of each system component and a user study to evaluate the games based on human feedback. Read More
Towards Automated Differential Diagnosis of Skin Diseases Using Deep Learning and Imbalance-Aware Strategiescs.AI updates on arXiv.org arXiv:2601.00286v1 Announce Type: cross
Abstract: As dermatological conditions become increasingly common and the availability of dermatologists remains limited, there is a growing need for intelligent tools to support both patients and clinicians in the timely and accurate diagnosis of skin diseases. In this project, we developed a deep learning based model for the classification and diagnosis of skin conditions. By leveraging pretraining on publicly available skin disease image datasets, our model effectively extracted visual features and accurately classified various dermatological cases. Throughout the project, we refined the model architecture, optimized data preprocessing workflows, and applied targeted data augmentation techniques to improve overall performance. The final model, based on the Swin Transformer, achieved a prediction accuracy of 87.71 percent across eight skin lesion classes on the ISIC2019 dataset. These results demonstrate the model’s potential as a diagnostic support tool for clinicians and a self assessment aid for patients.
arXiv:2601.00286v1 Announce Type: cross
Abstract: As dermatological conditions become increasingly common and the availability of dermatologists remains limited, there is a growing need for intelligent tools to support both patients and clinicians in the timely and accurate diagnosis of skin diseases. In this project, we developed a deep learning based model for the classification and diagnosis of skin conditions. By leveraging pretraining on publicly available skin disease image datasets, our model effectively extracted visual features and accurately classified various dermatological cases. Throughout the project, we refined the model architecture, optimized data preprocessing workflows, and applied targeted data augmentation techniques to improve overall performance. The final model, based on the Swin Transformer, achieved a prediction accuracy of 87.71 percent across eight skin lesion classes on the ISIC2019 dataset. These results demonstrate the model’s potential as a diagnostic support tool for clinicians and a self assessment aid for patients. Read More
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexitycs.AI updates on arXiv.org arXiv:2601.00268v1 Announce Type: cross
Abstract: We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents’ function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
arXiv:2601.00268v1 Announce Type: cross
Abstract: We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents’ function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction. Read More
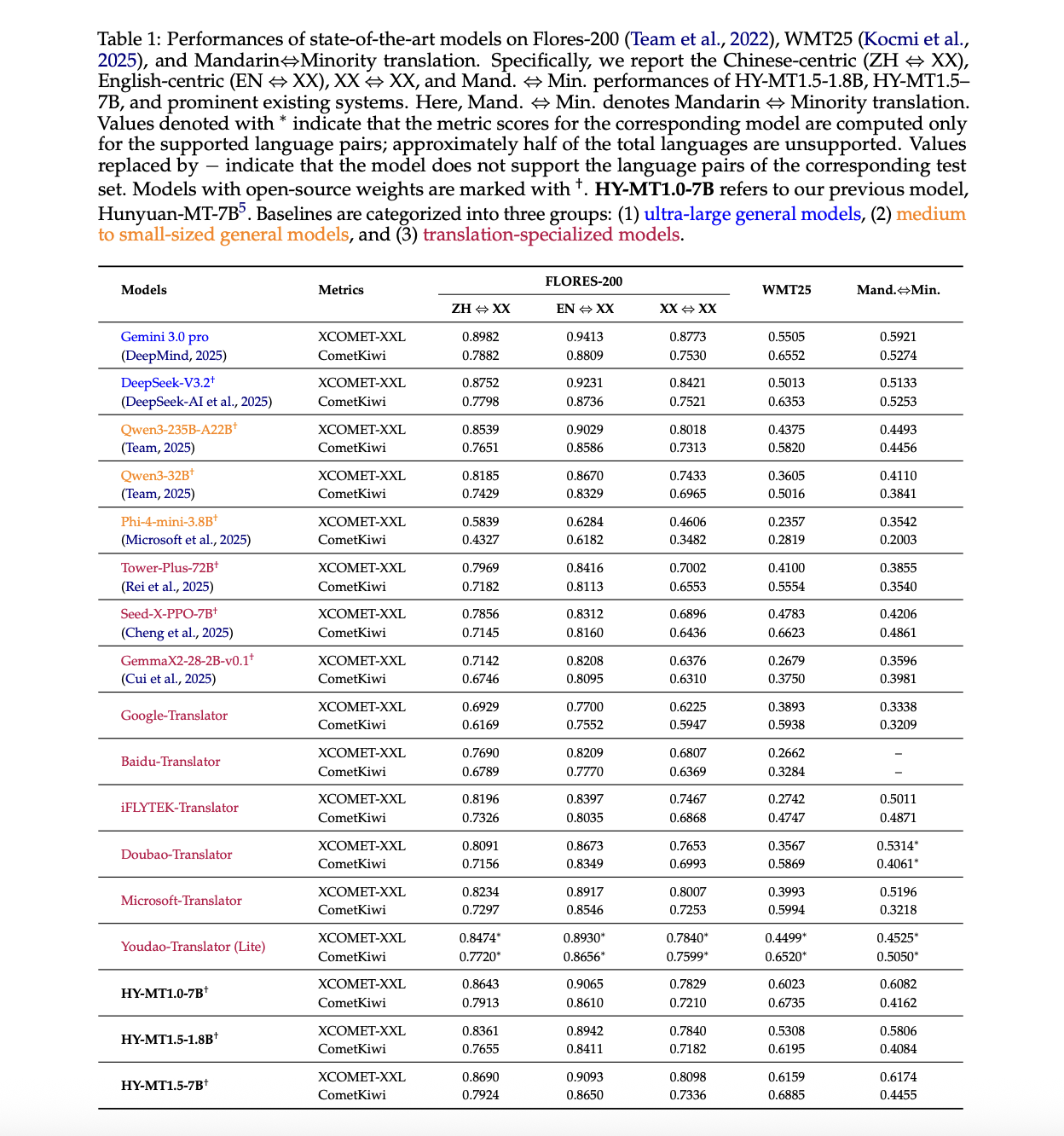
Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud DeploymentMarkTechPost Tencent Hunyuan researchers have released HY-MT1.5, a multilingual machine translation family that targets both mobile devices and cloud systems with the same training recipe and metrics. HY-MT1.5 consists of 2 translation models, HY-MT1.5-1.8B and HY-MT1.5-7B, supports mutual translation across 33 languages with 5 ethnic and dialect variations, and is available on GitHub and Hugging Face
The post Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment appeared first on MarkTechPost.
Tencent Hunyuan researchers have released HY-MT1.5, a multilingual machine translation family that targets both mobile devices and cloud systems with the same training recipe and metrics. HY-MT1.5 consists of 2 translation models, HY-MT1.5-1.8B and HY-MT1.5-7B, supports mutual translation across 33 languages with 5 ethnic and dialect variations, and is available on GitHub and Hugging Face
The post Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment appeared first on MarkTechPost. Read More

AI Interview Series #5: Prompt CachingMarkTechPost Question: Imagine your company’s LLM API costs suddenly doubled last month. A deeper analysis shows that while user inputs look different at a text level, many of them are semantically similar. As an engineer, how would you identify and reduce this redundancy without impacting response quality? What is Prompt Caching? Prompt caching is an optimization
The post AI Interview Series #5: Prompt Caching appeared first on MarkTechPost.
Question: Imagine your company’s LLM API costs suddenly doubled last month. A deeper analysis shows that while user inputs look different at a text level, many of them are semantically similar. As an engineer, how would you identify and reduce this redundancy without impacting response quality? What is Prompt Caching? Prompt caching is an optimization
The post AI Interview Series #5: Prompt Caching appeared first on MarkTechPost. Read More
Reasoning in Action: MCTS-Driven Knowledge Retrieval for Large Language Modelscs.AI updates on arXiv.org arXiv:2601.00003v1 Announce Type: new
Abstract: Large language models (LLMs) typically enhance their performance through either the retrieval of semantically similar information or the improvement of their reasoning capabilities. However, a significant challenge remains in effectively integrating both retrieval and reasoning strategies to optimize LLM performance. In this paper, we introduce a reasoning-aware knowledge retrieval method that enriches LLMs with information aligned to the logical structure of conversations, moving beyond surface-level semantic similarity. We follow a coarse-to-fine approach for knowledge retrieval. First, we identify a contextually relevant sub-region of the knowledge base, ensuring that all sentences within it are relevant to the context topic. Next, we refine our search within this sub-region to extract knowledge that is specifically relevant to the reasoning process. Throughout both phases, we employ the Monte Carlo Tree Search-inspired search method to effectively navigate through knowledge sentences using common keywords. Experiments on two multi-turn dialogue datasets demonstrate that our knowledge retrieval approach not only aligns more closely with the underlying reasoning in human conversations but also significantly enhances the diversity of the retrieved knowledge, resulting in more informative and creative responses.
arXiv:2601.00003v1 Announce Type: new
Abstract: Large language models (LLMs) typically enhance their performance through either the retrieval of semantically similar information or the improvement of their reasoning capabilities. However, a significant challenge remains in effectively integrating both retrieval and reasoning strategies to optimize LLM performance. In this paper, we introduce a reasoning-aware knowledge retrieval method that enriches LLMs with information aligned to the logical structure of conversations, moving beyond surface-level semantic similarity. We follow a coarse-to-fine approach for knowledge retrieval. First, we identify a contextually relevant sub-region of the knowledge base, ensuring that all sentences within it are relevant to the context topic. Next, we refine our search within this sub-region to extract knowledge that is specifically relevant to the reasoning process. Throughout both phases, we employ the Monte Carlo Tree Search-inspired search method to effectively navigate through knowledge sentences using common keywords. Experiments on two multi-turn dialogue datasets demonstrate that our knowledge retrieval approach not only aligns more closely with the underlying reasoning in human conversations but also significantly enhances the diversity of the retrieved knowledge, resulting in more informative and creative responses. Read More
Narrative-to-Scene Generation: An LLM-Driven Pipeline for 2D Game Environmentscs.AI updates on arXiv.org arXiv:2509.04481v2 Announce Type: replace-cross
Abstract: Recent advances in large language models (LLMs) enable compelling story generation, but connecting narrative text to playable visual environments remains an open challenge in procedural content generation (PCG). We present a lightweight pipeline that transforms short narrative prompts into a sequence of 2D tile-based game scenes, reflecting the temporal structure of stories. Given an LLM-generated narrative, our system identifies three key time frames, extracts spatial predicates in the form of “Object-Relation-Object” triples, and retrieves visual assets using affordance-aware semantic embeddings from the GameTileNet dataset. A layered terrain is generated using Cellular Automata, and objects are placed using spatial rules grounded in the predicate structure. We evaluated our system in ten diverse stories, analyzing tile-object matching, affordance-layer alignment, and spatial constraint satisfaction across frames. This prototype offers a scalable approach to narrative-driven scene generation and lays the foundation for future work on multi-frame continuity, symbolic tracking, and multi-agent coordination in story-centered PCG.
arXiv:2509.04481v2 Announce Type: replace-cross
Abstract: Recent advances in large language models (LLMs) enable compelling story generation, but connecting narrative text to playable visual environments remains an open challenge in procedural content generation (PCG). We present a lightweight pipeline that transforms short narrative prompts into a sequence of 2D tile-based game scenes, reflecting the temporal structure of stories. Given an LLM-generated narrative, our system identifies three key time frames, extracts spatial predicates in the form of “Object-Relation-Object” triples, and retrieves visual assets using affordance-aware semantic embeddings from the GameTileNet dataset. A layered terrain is generated using Cellular Automata, and objects are placed using spatial rules grounded in the predicate structure. We evaluated our system in ten diverse stories, analyzing tile-object matching, affordance-layer alignment, and spatial constraint satisfaction across frames. This prototype offers a scalable approach to narrative-driven scene generation and lays the foundation for future work on multi-frame continuity, symbolic tracking, and multi-agent coordination in story-centered PCG. Read More
YOLOv1 Loss Function Walkthrough: Regression for AllTowards Data Science An explanation of how YOLOv1 measures the correctness of its object detection and classification predictions
The post YOLOv1 Loss Function Walkthrough: Regression for All appeared first on Towards Data Science.
An explanation of how YOLOv1 measures the correctness of its object detection and classification predictions
The post YOLOv1 Loss Function Walkthrough: Regression for All appeared first on Towards Data Science. Read More

L’Oréal brings AI into everyday digital advertising productionAI News Producing digital advertising at global scale has become less about one standout campaign and more about volume, speed, and consistency. For consumer brands operating across dozens of markets, the challenge is not creativity alone, but how to keep content flowing without repeating expensive production cycles. That pressure is pushing some large companies to test where
The post L’Oréal brings AI into everyday digital advertising production appeared first on AI News.
Producing digital advertising at global scale has become less about one standout campaign and more about volume, speed, and consistency. For consumer brands operating across dozens of markets, the challenge is not creativity alone, but how to keep content flowing without repeating expensive production cycles. That pressure is pushing some large companies to test where
The post L’Oréal brings AI into everyday digital advertising production appeared first on AI News. Read More
A Coding Guide to Design and Orchestrate Advanced ReAct-Based Multi-Agent Workflows with AgentScope and OpenAIMarkTechPost In this tutorial, we build an advanced multi-agent incident response system using AgentScope. We orchestrate multiple ReAct agents, each with a clearly defined role such as routing, triage, analysis, writing, and review, and connect them through structured routing and a shared message hub. By integrating OpenAI models, lightweight tool calling, and a simple internal runbook,
The post A Coding Guide to Design and Orchestrate Advanced ReAct-Based Multi-Agent Workflows with AgentScope and OpenAI appeared first on MarkTechPost.
In this tutorial, we build an advanced multi-agent incident response system using AgentScope. We orchestrate multiple ReAct agents, each with a clearly defined role such as routing, triage, analysis, writing, and review, and connect them through structured routing and a shared message hub. By integrating OpenAI models, lightweight tool calling, and a simple internal runbook,
The post A Coding Guide to Design and Orchestrate Advanced ReAct-Based Multi-Agent Workflows with AgentScope and OpenAI appeared first on MarkTechPost. Read More