
The integration of AI in modern forex automationAI News Try to think of just one area where artificial intelligence is not leaving a mark, and you’ll realise there’s almost none. And in the forex world, things have not been any different. It’s a big part of why Fortune Business Insights values the global AI market size at $375.93 billion. Looking ahead, the sector could
The post The integration of AI in modern forex automation appeared first on AI News.
Try to think of just one area where artificial intelligence is not leaving a mark, and you’ll realise there’s almost none. And in the forex world, things have not been any different. It’s a big part of why Fortune Business Insights values the global AI market size at $375.93 billion. Looking ahead, the sector could
The post The integration of AI in modern forex automation appeared first on AI News. Read More

7 Essential OpenClaw Skills You Need Right NowKDnuggets Skills are what make OpenClaw more than a local assistant, and these are the most popular ones worth installing today.
Skills are what make OpenClaw more than a local assistant, and these are the most popular ones worth installing today. Read More
Gemini 3.1 Flash-Lite: Built for intelligence at scaleGoogle DeepMind News Gemini 3.1 Flash-Lite is our fastest and most cost-efficient Gemini 3 series model yet.
Gemini 3.1 Flash-Lite is our fastest and most cost-efficient Gemini 3 series model yet. Read More

Building a scalable virtual try-on solution using Amazon Nova on AWS: part 1 Artificial Intelligence
Building a scalable virtual try-on solution using Amazon Nova on AWS: part 1Artificial Intelligence In this post, we explore the virtual try-on capability now available in Amazon Nova Canvas, including sample code to get started quickly and tips to help get the best outputs.
In this post, we explore the virtual try-on capability now available in Amazon Nova Canvas, including sample code to get started quickly and tips to help get the best outputs. Read More
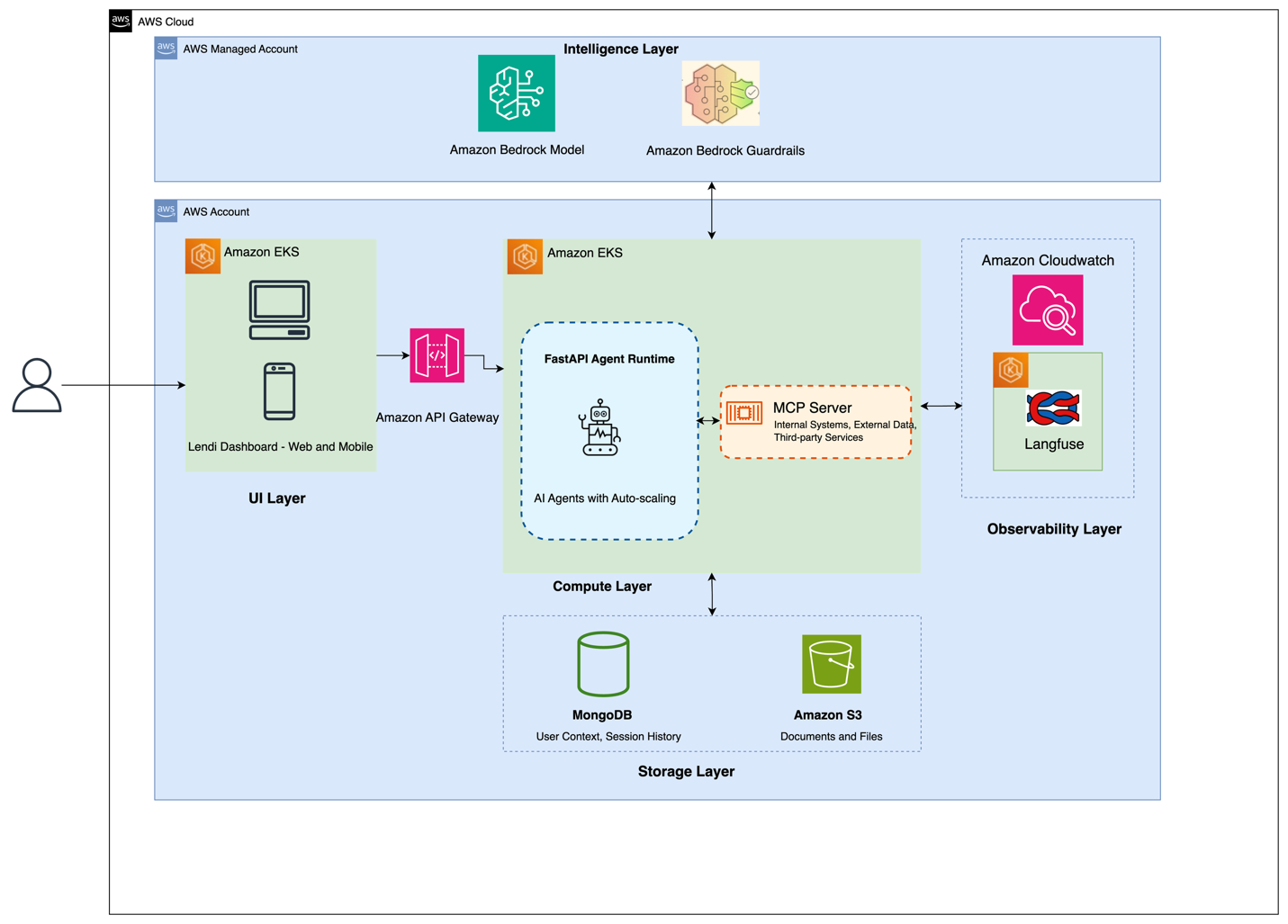
How Lendi revamped the refinance journey for its customers using agentic AI in 16 weeks using Amazon BedrockArtificial Intelligence This post details how Lendi Group built their AI-powered Home Loan Guardian using Amazon Bedrock, the challenges they faced, the architecture they implemented, and the significant business outcomes they’ve achieved. Their journey offers valuable insights for organizations that want to use generative AI to transform customer experiences while maintaining the human touch that builds trust and loyalty.
This post details how Lendi Group built their AI-powered Home Loan Guardian using Amazon Bedrock, the challenges they faced, the architecture they implemented, and the significant business outcomes they’ve achieved. Their journey offers valuable insights for organizations that want to use generative AI to transform customer experiences while maintaining the human touch that builds trust and loyalty. Read More
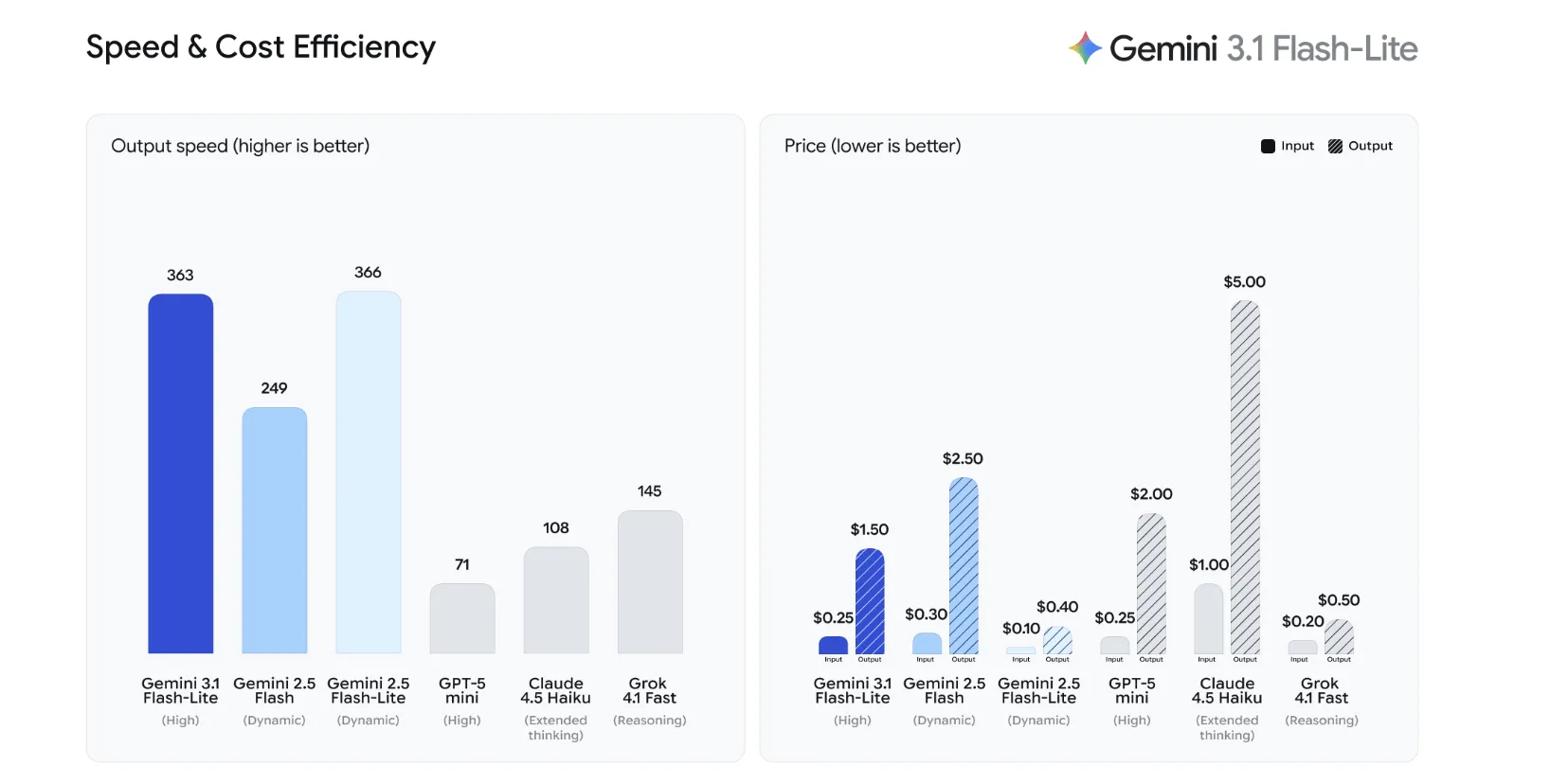
Google Drops Gemini 3.1 Flash-Lite: A Cost-efficient Powerhouse with Adjustable Thinking Levels Designed for High-Scale Production AIMarkTechPost Google has released Gemini 3.1 Flash-Lite, the most cost-efficient entry in the Gemini 3 model series. Designed for ‘intelligence at scale,’ this model is optimized for high-volume tasks where low latency and cost-per-token are the primary engineering constraints. It is currently available in Public Preview via the Gemini API (Google AI Studio) and Vertex AI.
The post Google Drops Gemini 3.1 Flash-Lite: A Cost-efficient Powerhouse with Adjustable Thinking Levels Designed for High-Scale Production AI appeared first on MarkTechPost.
Google has released Gemini 3.1 Flash-Lite, the most cost-efficient entry in the Gemini 3 model series. Designed for ‘intelligence at scale,’ this model is optimized for high-volume tasks where low latency and cost-per-token are the primary engineering constraints. It is currently available in Public Preview via the Gemini API (Google AI Studio) and Vertex AI.
The post Google Drops Gemini 3.1 Flash-Lite: A Cost-efficient Powerhouse with Adjustable Thinking Levels Designed for High-Scale Production AI appeared first on MarkTechPost. Read More
I Quit My $130,000 ML Engineer Job After Learning 4 LessonsTowards Data Science What they don’t tell you about “dream tech jobs”
The post I Quit My $130,000 ML Engineer Job After Learning 4 Lessons appeared first on Towards Data Science.
What they don’t tell you about “dream tech jobs”
The post I Quit My $130,000 ML Engineer Job After Learning 4 Lessons appeared first on Towards Data Science. Read More

10 Agentic AI Concepts Explained in Under 10 MinutesKDnuggets An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context and a control loop to decide what happens next.
An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context and a control loop to decide what happens next. Read More
Agentic RAG vs Classic RAG: From a Pipeline to a Control LoopTowards Data Science A practical guide to choosing between single-pass pipelines and adaptive retrieval loops based on your use case’s complexity, cost, and reliability requirements
The post Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop appeared first on Towards Data Science.
A practical guide to choosing between single-pass pipelines and adaptive retrieval loops based on your use case’s complexity, cost, and reliability requirements
The post Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop appeared first on Towards Data Science. Read More

Physical AI adoption boosts customer service ROIAI News The adoption of physical AI drives ROI in frontline customer service by merging digital intelligence with human-like physical interaction. As businesses navigate shrinking labour pools, they are finding that simply automating routine workflows is no longer enough. A new partnership between KDDI and AVITA demonstrates how companies can address complex operational gaps through humanoid deployment.
The post Physical AI adoption boosts customer service ROI appeared first on AI News.
The adoption of physical AI drives ROI in frontline customer service by merging digital intelligence with human-like physical interaction. As businesses navigate shrinking labour pools, they are finding that simply automating routine workflows is no longer enough. A new partnership between KDDI and AVITA demonstrates how companies can address complex operational gaps through humanoid deployment.
The post Physical AI adoption boosts customer service ROI appeared first on AI News. Read More