
A Comparison of DeepSeek and Other LLMscs.AI updates on arXiv.org arXiv:2502.03688v3 Announce Type: replace-cross
Abstract: Recently, DeepSeek has been the focus of attention in and beyond the AI community. An interesting problem is how DeepSeek compares to other large language models (LLMs). There are many tasks an LLM can do, and in this paper, we use the task of “predicting an outcome using a short text” for comparison. We consider two settings, an authorship classification setting and a citation classification setting. In the first one, the goal is to determine whether a short text is written by human or AI. In the second one, the goal is to classify a citation to one of four types using the textual content. For each experiment, we compare DeepSeek with $4$ popular LLMs: Claude, Gemini, GPT, and Llama.
We find that, in terms of classification accuracy, DeepSeek outperforms Gemini, GPT, and Llama in most cases, but underperforms Claude. We also find that DeepSeek is comparably slower than others but with a low cost to use, while Claude is much more expensive than all the others. Finally, we find that in terms of similarity, the output of DeepSeek is most similar to those of Gemini and Claude (and among all $5$ LLMs, Claude and Gemini have the most similar outputs).
In this paper, we also present a fully-labeled dataset collected by ourselves, and propose a recipe where we can use the LLMs and a recent data set, MADStat, to generate new data sets. The datasets in our paper can be used as benchmarks for future study on LLMs.
arXiv:2502.03688v3 Announce Type: replace-cross
Abstract: Recently, DeepSeek has been the focus of attention in and beyond the AI community. An interesting problem is how DeepSeek compares to other large language models (LLMs). There are many tasks an LLM can do, and in this paper, we use the task of “predicting an outcome using a short text” for comparison. We consider two settings, an authorship classification setting and a citation classification setting. In the first one, the goal is to determine whether a short text is written by human or AI. In the second one, the goal is to classify a citation to one of four types using the textual content. For each experiment, we compare DeepSeek with $4$ popular LLMs: Claude, Gemini, GPT, and Llama.
We find that, in terms of classification accuracy, DeepSeek outperforms Gemini, GPT, and Llama in most cases, but underperforms Claude. We also find that DeepSeek is comparably slower than others but with a low cost to use, while Claude is much more expensive than all the others. Finally, we find that in terms of similarity, the output of DeepSeek is most similar to those of Gemini and Claude (and among all $5$ LLMs, Claude and Gemini have the most similar outputs).
In this paper, we also present a fully-labeled dataset collected by ourselves, and propose a recipe where we can use the LLMs and a recent data set, MADStat, to generate new data sets. The datasets in our paper can be used as benchmarks for future study on LLMs. Read More
FVA-RAG: Falsification-Verification Alignment for Mitigating Sycophantic Hallucinationscs.AI updates on arXiv.org arXiv:2512.07015v2 Announce Type: replace-cross
Abstract: Retrieval-Augmented Generation (RAG) reduces hallucinations by grounding answers in retrieved evidence, yet standard retrievers often exhibit retrieval sycophancy: they preferentially surface evidence that supports a user’s premise, even when the premise is false. We propose FVA-RAG (Falsification-Verification Alignment RAG), a pipeline that inverts the standard RAG workflow by treating the initial response as a draft hypothesis and explicitly retrieving anti-context to stress-test it. We evaluate on the full TruthfulQA-Generation benchmark (N=817) under a fully frozen protocol with 0 live web calls and identical retrieval budgets across methods. Using gpt-4o for generation and deterministic judging, FVA-RAG achieves 79.80-80.05% accuracy across two independently built frozen corpora , significantly outperforming prompted variants of Self-RAG (71.11-72.22%) and CRAG (71.36-73.93%) with p < 10^-6 according to McNemar’s test. FVA-RAG triggers falsification on 24.5-29.3% of queries, demonstrating that targeted counter-evidence retrieval is decisive for mitigating premise-confirming hallucinations.
arXiv:2512.07015v2 Announce Type: replace-cross
Abstract: Retrieval-Augmented Generation (RAG) reduces hallucinations by grounding answers in retrieved evidence, yet standard retrievers often exhibit retrieval sycophancy: they preferentially surface evidence that supports a user’s premise, even when the premise is false. We propose FVA-RAG (Falsification-Verification Alignment RAG), a pipeline that inverts the standard RAG workflow by treating the initial response as a draft hypothesis and explicitly retrieving anti-context to stress-test it. We evaluate on the full TruthfulQA-Generation benchmark (N=817) under a fully frozen protocol with 0 live web calls and identical retrieval budgets across methods. Using gpt-4o for generation and deterministic judging, FVA-RAG achieves 79.80-80.05% accuracy across two independently built frozen corpora , significantly outperforming prompted variants of Self-RAG (71.11-72.22%) and CRAG (71.36-73.93%) with p < 10^-6 according to McNemar’s test. FVA-RAG triggers falsification on 24.5-29.3% of queries, demonstrating that targeted counter-evidence retrieval is decisive for mitigating premise-confirming hallucinations. Read More
How to Build Production-Grade Agentic Workflows with GraphBit Using Deterministic Tools, Validated Execution Graphs, and Optional LLM OrchestrationMarkTechPost In this tutorial, we build an end-to-end, production-style agentic workflow using GraphBit that demonstrates how graph-structured execution, tool calling, and optional LLM-driven agents can coexist in a single system. We start by initializing and inspecting the GraphBit runtime, then define a realistic customer-support ticket domain with typed data structures and deterministic, offline-executable tools. We show
The post How to Build Production-Grade Agentic Workflows with GraphBit Using Deterministic Tools, Validated Execution Graphs, and Optional LLM Orchestration appeared first on MarkTechPost.
In this tutorial, we build an end-to-end, production-style agentic workflow using GraphBit that demonstrates how graph-structured execution, tool calling, and optional LLM-driven agents can coexist in a single system. We start by initializing and inspecting the GraphBit runtime, then define a realistic customer-support ticket domain with typed data structures and deterministic, offline-executable tools. We show
The post How to Build Production-Grade Agentic Workflows with GraphBit Using Deterministic Tools, Validated Execution Graphs, and Optional LLM Orchestration appeared first on MarkTechPost. Read More
Hugging Face Transformers in Action: Learning How To Leverage AI for NLPTowards Data Science A practical guide to Hugging Face Transformers and to how you can analyze your resumé sentiment in seconds with AI
The post Hugging Face Transformers in Action: Learning How To Leverage AI for NLP appeared first on Towards Data Science.
A practical guide to Hugging Face Transformers and to how you can analyze your resumé sentiment in seconds with AI
The post Hugging Face Transformers in Action: Learning How To Leverage AI for NLP appeared first on Towards Data Science. Read More
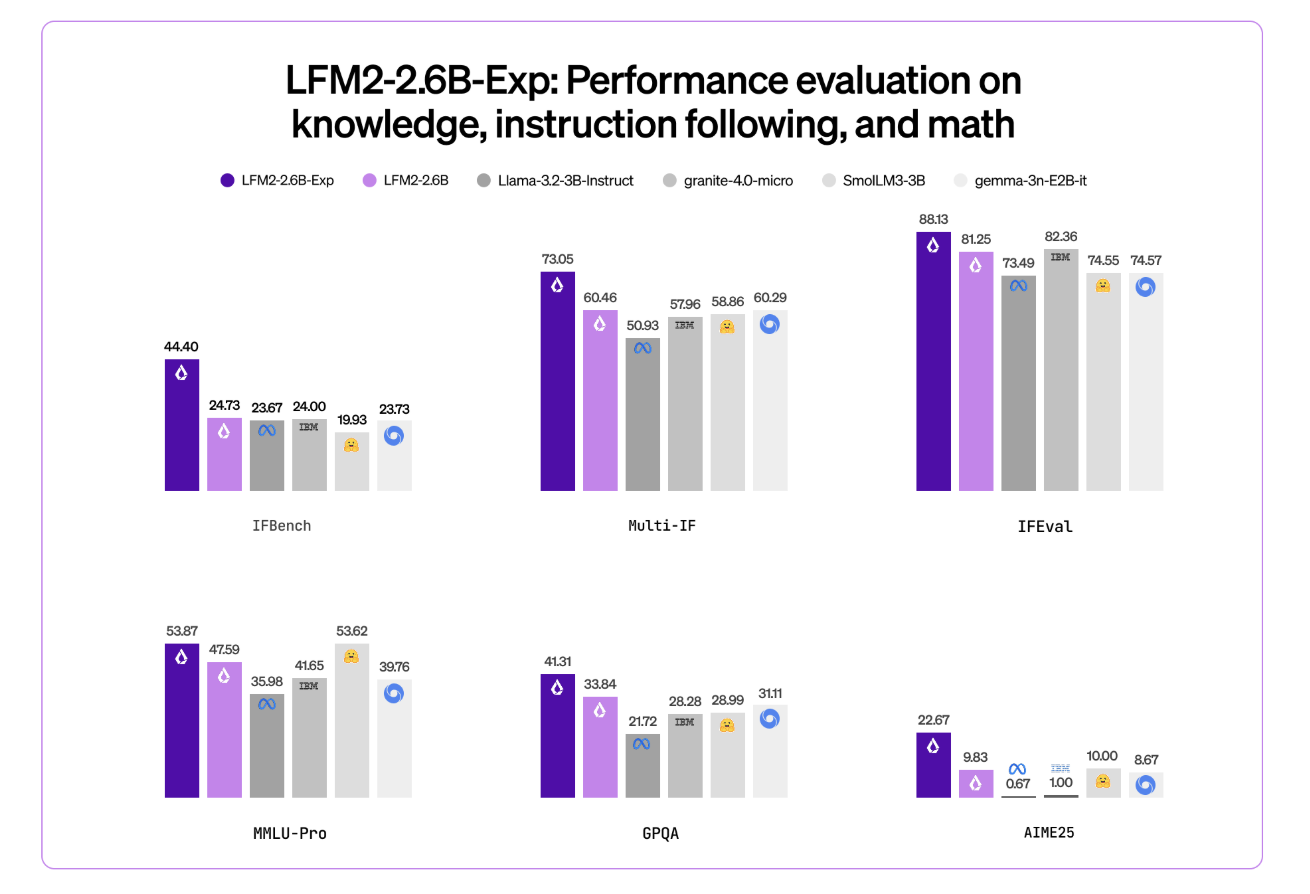
Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model BehaviorMarkTechPost Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment. Where LFM2-2.6B-Exp Fits
The post Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior appeared first on MarkTechPost.
Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment. Where LFM2-2.6B-Exp Fits
The post Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior appeared first on MarkTechPost. Read More
Breaking the Hardware Barrier: Software FP8 for Older GPUsTowards Data Science Deep learning workloads are increasingly memory-bound, with GPU cores sitting idle while waiting for data transfers. FP8 precision solves this on newer hardware, but what about the millions of RTX 30 and 20 series GPUs already deployed? Feather demonstrates that software-based FP8 emulation through bitwise packing can achieve near-theoretical 4x bandwidth improvements (3.3x measured), making efficient deep learning accessible without expensive hardware upgrades
The post Breaking the Hardware Barrier: Software FP8 for Older GPUs appeared first on Towards Data Science.
Deep learning workloads are increasingly memory-bound, with GPU cores sitting idle while waiting for data transfers. FP8 precision solves this on newer hardware, but what about the millions of RTX 30 and 20 series GPUs already deployed? Feather demonstrates that software-based FP8 emulation through bitwise packing can achieve near-theoretical 4x bandwidth improvements (3.3x measured), making efficient deep learning accessible without expensive hardware upgrades
The post Breaking the Hardware Barrier: Software FP8 for Older GPUs appeared first on Towards Data Science. Read More
How IntelliNode Automates Complex Workflows with Vibe AgentsTowards Data Science Many AI systems focus on isolated tasks or simple prompt engineering. This approach allowed us to build interesting applications from a single prompt, but we are starting to hit a limit. Simple prompting falls short when we tackle complex AI tasks that require multiple stages or enterprise systems that must factor in information gradually. The
The post How IntelliNode Automates Complex Workflows with Vibe Agents appeared first on Towards Data Science.
Many AI systems focus on isolated tasks or simple prompt engineering. This approach allowed us to build interesting applications from a single prompt, but we are starting to hit a limit. Simple prompting falls short when we tackle complex AI tasks that require multiple stages or enterprise systems that must factor in information gradually. The
The post How IntelliNode Automates Complex Workflows with Vibe Agents appeared first on Towards Data Science. Read More
Exploring TabPFN: A Foundation Model Built for Tabular DataTowards Data Science Understanding the architecture, training pipeline and implementing TabPFN in practice
The post Exploring TabPFN: A Foundation Model Built for Tabular Data appeared first on Towards Data Science.
Understanding the architecture, training pipeline and implementing TabPFN in practice
The post Exploring TabPFN: A Foundation Model Built for Tabular Data appeared first on Towards Data Science. Read More

Train a Model Faster with torch.compile and Gradient AccumulationMachineLearningMastery.com This article is divided into two parts; they are: • Using `torch.
This article is divided into two parts; they are: • Using `torch. Read More

Training a Model on Multiple GPUs with Data ParallelismMachineLearningMastery.com This article is divided into two parts; they are: • Data Parallelism • Distributed Data Parallelism If you have multiple GPUs, you can combine them to operate as a single GPU with greater memory capacity.
This article is divided into two parts; they are: • Data Parallelism • Distributed Data Parallelism If you have multiple GPUs, you can combine them to operate as a single GPU with greater memory capacity. Read More