
5 Useful DIY Python Functions for JSON Parsing and ProcessingKDnuggets Stop wrestling with messy JSON. These five Python functions help you parse, validate, and transform JSON data efficiently.
Stop wrestling with messy JSON. These five Python functions help you parse, validate, and transform JSON data efficiently. Read More

Time Series Isn’t Enough: How Graph Neural Networks Change Demand ForecastingTowards Data Science Why modeling SKUs as a network reveals what traditional forecasts miss
The post Time Series Isn’t Enough: How Graph Neural Networks Change Demand Forecasting appeared first on Towards Data Science.
Why modeling SKUs as a network reveals what traditional forecasts miss
The post Time Series Isn’t Enough: How Graph Neural Networks Change Demand Forecasting appeared first on Towards Data Science. Read More

JPMorgan Chase treats AI spending as core infrastructureAI News Inside large banks, artificial intelligence has moved into a category once reserved for payment systems, data centres, and core risk controls. At JPMorgan Chase, AI is framed as infrastructure the bank believes it cannot afford to neglect. That position came through clearly in recent comments from CEO Jamie Dimon, who defended the bank’s rising technology
The post JPMorgan Chase treats AI spending as core infrastructure appeared first on AI News.
Inside large banks, artificial intelligence has moved into a category once reserved for payment systems, data centres, and core risk controls. At JPMorgan Chase, AI is framed as infrastructure the bank believes it cannot afford to neglect. That position came through clearly in recent comments from CEO Jamie Dimon, who defended the bank’s rising technology
The post JPMorgan Chase treats AI spending as core infrastructure appeared first on AI News. Read More
A business that scales with the value of intelligenceOpenAI News OpenAI’s business model scales with intelligence—spanning subscriptions, API, ads, commerce, and compute—driven by deepening ChatGPT adoption.
OpenAI’s business model scales with intelligence—spanning subscriptions, API, ads, commerce, and compute—driven by deepening ChatGPT adoption. Read More
Vercel Releases Agent Skills: A Package Manager For AI Coding Agents With 10 Years of React and Next.js Optimisation RulesMarkTechPost Vercel has released agent-skills, a collection of skills that turns best practice playbooks into reusable skills for AI coding agents. The project follows the Agent Skills specification and focuses first on React and Next.js performance, web design review, and claimable deployments on Vercel. Skills are installed with a command that feels similar to npm, and
The post Vercel Releases Agent Skills: A Package Manager For AI Coding Agents With 10 Years of React and Next.js Optimisation Rules appeared first on MarkTechPost.
Vercel has released agent-skills, a collection of skills that turns best practice playbooks into reusable skills for AI coding agents. The project follows the Agent Skills specification and focuses first on React and Next.js performance, web design review, and claimable deployments on Vercel. Skills are installed with a command that feels similar to npm, and
The post Vercel Releases Agent Skills: A Package Manager For AI Coding Agents With 10 Years of React and Next.js Optimisation Rules appeared first on MarkTechPost. Read More
How to Build a Self-Evaluating Agentic AI System with LlamaIndex and OpenAI Using Retrieval, Tool Use, and Automated Quality ChecksMarkTechPost In this tutorial, we build an advanced agentic AI workflow using LlamaIndex and OpenAI models. We focus on designing a reliable retrieval-augmented generation (RAG) agent that can reason over evidence, use tools deliberately, and evaluate its own outputs for quality. By structuring the system around retrieval, answer synthesis, and self-evaluation, we demonstrate how agentic patterns
The post How to Build a Self-Evaluating Agentic AI System with LlamaIndex and OpenAI Using Retrieval, Tool Use, and Automated Quality Checks appeared first on MarkTechPost.
In this tutorial, we build an advanced agentic AI workflow using LlamaIndex and OpenAI models. We focus on designing a reliable retrieval-augmented generation (RAG) agent that can reason over evidence, use tools deliberately, and evaluate its own outputs for quality. By structuring the system around retrieval, answer synthesis, and self-evaluation, we demonstrate how agentic patterns
The post How to Build a Self-Evaluating Agentic AI System with LlamaIndex and OpenAI Using Retrieval, Tool Use, and Automated Quality Checks appeared first on MarkTechPost. Read More
The Hidden Opportunity in AI Workflow Automation with n8n for Low-Tech CompaniesTowards Data Science How to use n8n with multimodal AI and optimisation tools to help companies with low data maturity accelerate their digital transformation.
The post The Hidden Opportunity in AI Workflow Automation with n8n for Low-Tech Companies appeared first on Towards Data Science.
How to use n8n with multimodal AI and optimisation tools to help companies with low data maturity accelerate their digital transformation.
The post The Hidden Opportunity in AI Workflow Automation with n8n for Low-Tech Companies appeared first on Towards Data Science. Read More
Why Healthcare Leads in Knowledge GraphsTowards Data Science How science, regulation, collaboration, and public funding shaped the world’s most mature semantic infrastructure
The post Why Healthcare Leads in Knowledge Graphs appeared first on Towards Data Science.
How science, regulation, collaboration, and public funding shaped the world’s most mature semantic infrastructure
The post Why Healthcare Leads in Knowledge Graphs appeared first on Towards Data Science. Read More
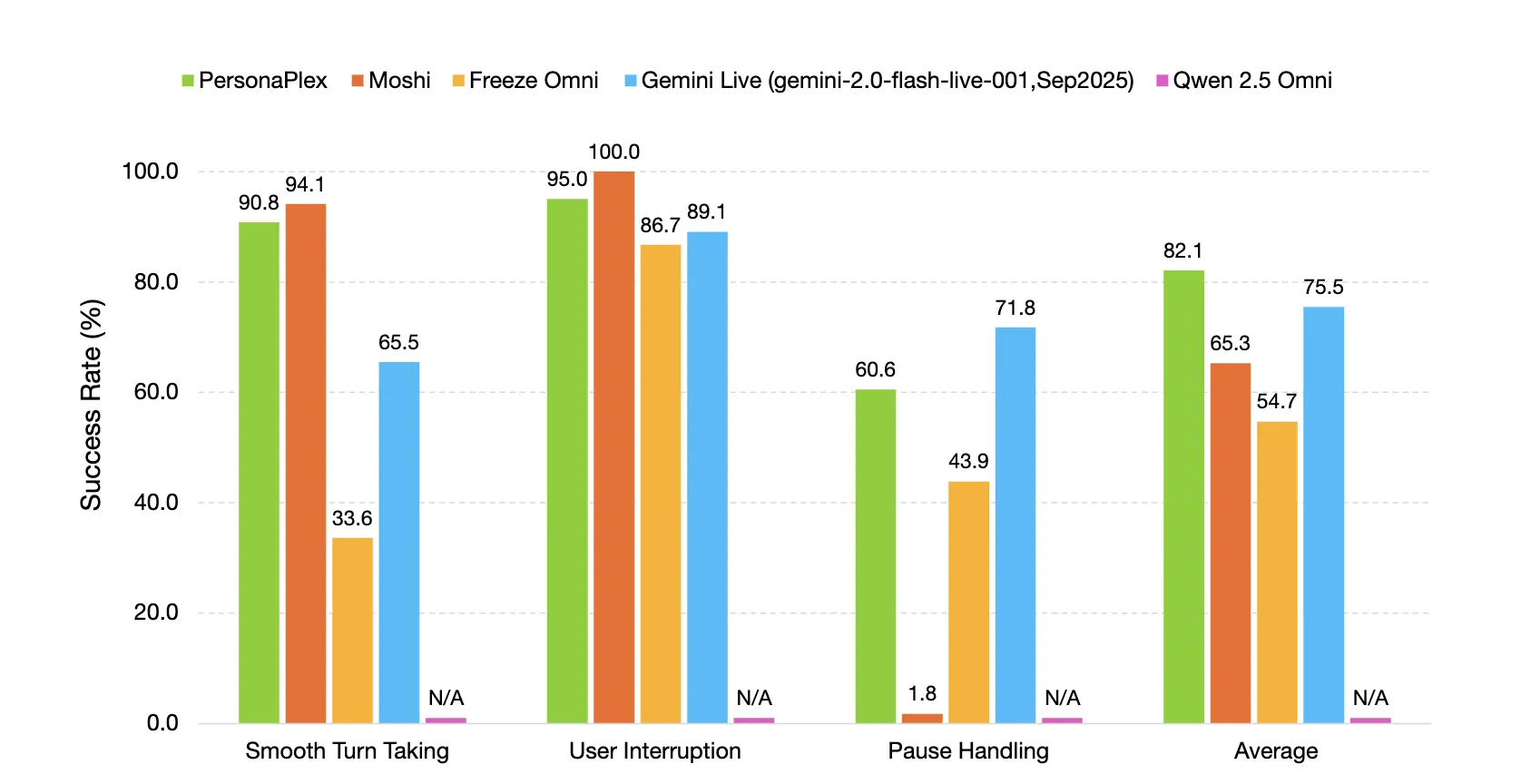
NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex ConversationsMarkTechPost NVIDIA Researchers released PersonaPlex-7B-v1, a full duplex speech to speech conversational model that targets natural voice interactions with precise persona control. From ASR→LLM→TTS to a single full duplex model Conventional voice assistants usually run a cascade. Automatic Speech Recognition (ASR) converts speech to text, a language model generates a text answer, and Text to Speech
The post NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex Conversations appeared first on MarkTechPost.
NVIDIA Researchers released PersonaPlex-7B-v1, a full duplex speech to speech conversational model that targets natural voice interactions with precise persona control. From ASR→LLM→TTS to a single full duplex model Conventional voice assistants usually run a cascade. Automatic Speech Recognition (ASR) converts speech to text, a language model generates a text answer, and Text to Speech
The post NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex Conversations appeared first on MarkTechPost. Read More
A Geometric Method to Spot Hallucinations Without an LLM JudgeTowards Data Science Imagine a flock of birds in flight. There’s no leader. No central command. Each bird aligns with its neighbors—matching direction, adjusting speed, maintaining coherence through purely local coordination. The result is global order emerging from local consistency. Now imagine one bird flying with the same conviction as the others. Its wingbeats are confident. Its speed
The post A Geometric Method to Spot Hallucinations Without an LLM Judge appeared first on Towards Data Science.
Imagine a flock of birds in flight. There’s no leader. No central command. Each bird aligns with its neighbors—matching direction, adjusting speed, maintaining coherence through purely local coordination. The result is global order emerging from local consistency. Now imagine one bird flying with the same conviction as the others. Its wingbeats are confident. Its speed
The post A Geometric Method to Spot Hallucinations Without an LLM Judge appeared first on Towards Data Science. Read More