
Inside Standard Chartered’s approach to running AI under privacy rulesAI News For banks trying to put AI into real use, the hardest questions often come before any model is trained. Can the data be used at all? Where is it allowed to be stored? Who is responsible once the system goes live? At Standard Chartered, these privacy-driven questions now shape how AI systems are built, and
The post Inside Standard Chartered’s approach to running AI under privacy rules appeared first on AI News.
For banks trying to put AI into real use, the hardest questions often come before any model is trained. Can the data be used at all? Where is it allowed to be stored? Who is responsible once the system goes live? At Standard Chartered, these privacy-driven questions now shape how AI systems are built, and
The post Inside Standard Chartered’s approach to running AI under privacy rules appeared first on AI News. Read More

More at Stake: How Payoff and Language Shape LLM Agent Strategies in Cooperation Dilemmascs.AI updates on arXiv.org arXiv:2601.19082v1 Announce Type: new
Abstract: As LLMs increasingly act as autonomous agents in interactive and multi-agent settings, understanding their strategic behavior is critical for safety, coordination, and AI-driven social and economic systems. We investigate how payoff magnitude and linguistic context shape LLM strategies in repeated social dilemmas, using a payoff-scaled Prisoner’s Dilemma to isolate sensitivity to incentive strength. Across models and languages, we observe consistent behavioral patterns, including incentive-sensitive conditional strategies and cross-linguistic divergence. To interpret these dynamics, we train supervised classifiers on canonical repeated-game strategies and apply them to LLM decisions, revealing systematic, model- and language-dependent behavioral intentions, with linguistic framing sometimes matching or exceeding architectural effects. Our results provide a unified framework for auditing LLMs as strategic agents and highlight cooperation biases with direct implications for AI governance and multi-agent system design.
arXiv:2601.19082v1 Announce Type: new
Abstract: As LLMs increasingly act as autonomous agents in interactive and multi-agent settings, understanding their strategic behavior is critical for safety, coordination, and AI-driven social and economic systems. We investigate how payoff magnitude and linguistic context shape LLM strategies in repeated social dilemmas, using a payoff-scaled Prisoner’s Dilemma to isolate sensitivity to incentive strength. Across models and languages, we observe consistent behavioral patterns, including incentive-sensitive conditional strategies and cross-linguistic divergence. To interpret these dynamics, we train supervised classifiers on canonical repeated-game strategies and apply them to LLM decisions, revealing systematic, model- and language-dependent behavioral intentions, with linguistic framing sometimes matching or exceeding architectural effects. Our results provide a unified framework for auditing LLMs as strategic agents and highlight cooperation biases with direct implications for AI governance and multi-agent system design. Read More
Can We Trust LLM Detectors?cs.AI updates on arXiv.org arXiv:2601.15301v2 Announce Type: replace-cross
Abstract: The rapid adoption of LLMs has increased the need for reliable AI text detection, yet existing detectors often fail outside controlled benchmarks. We systematically evaluate 2 dominant paradigms (training-free and supervised) and show that both are brittle under distribution shift, unseen generators, and simple stylistic perturbations. To address these limitations, we propose a supervised contrastive learning (SCL) framework that learns discriminative style embeddings. Experiments show that while supervised detectors excel in-domain, they degrade sharply out-of-domain, and training-free methods remain highly sensitive to proxy choice. Overall, our results expose fundamental challenges in building domain-agnostic detectors. Our code is available at: https://github.com/HARSHITJAIS14/DetectAI
arXiv:2601.15301v2 Announce Type: replace-cross
Abstract: The rapid adoption of LLMs has increased the need for reliable AI text detection, yet existing detectors often fail outside controlled benchmarks. We systematically evaluate 2 dominant paradigms (training-free and supervised) and show that both are brittle under distribution shift, unseen generators, and simple stylistic perturbations. To address these limitations, we propose a supervised contrastive learning (SCL) framework that learns discriminative style embeddings. Experiments show that while supervised detectors excel in-domain, they degrade sharply out-of-domain, and training-free methods remain highly sensitive to proxy choice. Overall, our results expose fundamental challenges in building domain-agnostic detectors. Our code is available at: https://github.com/HARSHITJAIS14/DetectAI Read More
Bridging Visual and Wireless Sensing: A Unified Radiation Field for 3D Radio Map Constructioncs.AI updates on arXiv.org arXiv:2601.19216v1 Announce Type: cross
Abstract: The emerging applications of next-generation wireless networks (e.g., immersive 3D communication, low-altitude networks, and integrated sensing and communication) necessitate high-fidelity environmental intelligence. 3D radio maps have emerged as a critical tool for this purpose, enabling spectrum-aware planning and environment-aware sensing by bridging the gap between physical environments and electromagnetic signal propagation. However, constructing accurate 3D radio maps requires fine-grained 3D geometric information and a profound understanding of electromagnetic wave propagation. Existing approaches typically treat optical and wireless knowledge as distinct modalities, failing to exploit the fundamental physical principles governing both light and electromagnetic propagation. To bridge this gap, we propose URF-GS, a unified radio-optical radiation field representation framework for accurate and generalizable 3D radio map construction based on 3D Gaussian splatting (3D-GS) and inverse rendering. By fusing visual and wireless sensing observations, URF-GS recovers scene geometry and material properties while accurately predicting radio signal behavior at arbitrary transmitter-receiver (Tx-Rx) configurations. Experimental results demonstrate that URF-GS achieves up to a 24.7% improvement in spatial spectrum prediction accuracy and a 10x increase in sample efficiency for 3D radio map construction compared with neural radiance field (NeRF)-based methods. This work establishes a foundation for next-generation wireless networks by integrating perception, interaction, and communication through holistic radiation field reconstruction.
arXiv:2601.19216v1 Announce Type: cross
Abstract: The emerging applications of next-generation wireless networks (e.g., immersive 3D communication, low-altitude networks, and integrated sensing and communication) necessitate high-fidelity environmental intelligence. 3D radio maps have emerged as a critical tool for this purpose, enabling spectrum-aware planning and environment-aware sensing by bridging the gap between physical environments and electromagnetic signal propagation. However, constructing accurate 3D radio maps requires fine-grained 3D geometric information and a profound understanding of electromagnetic wave propagation. Existing approaches typically treat optical and wireless knowledge as distinct modalities, failing to exploit the fundamental physical principles governing both light and electromagnetic propagation. To bridge this gap, we propose URF-GS, a unified radio-optical radiation field representation framework for accurate and generalizable 3D radio map construction based on 3D Gaussian splatting (3D-GS) and inverse rendering. By fusing visual and wireless sensing observations, URF-GS recovers scene geometry and material properties while accurately predicting radio signal behavior at arbitrary transmitter-receiver (Tx-Rx) configurations. Experimental results demonstrate that URF-GS achieves up to a 24.7% improvement in spatial spectrum prediction accuracy and a 10x increase in sample efficiency for 3D radio map construction compared with neural radiance field (NeRF)-based methods. This work establishes a foundation for next-generation wireless networks by integrating perception, interaction, and communication through holistic radiation field reconstruction. Read More
AgenticSCR: An Autonomous Agentic Secure Code Review for Immature Vulnerabilities Detectioncs.AI updates on arXiv.org arXiv:2601.19138v1 Announce Type: cross
Abstract: Secure code review is critical at the pre-commit stage, where vulnerabilities must be caught early under tight latency and limited-context constraints. Existing SAST-based checks are noisy and often miss immature, context-dependent vulnerabilities, while standalone Large Language Models (LLMs) are constrained by context windows and lack explicit tool use. Agentic AI, which combine LLMs with autonomous decision-making, tool invocation, and code navigation, offer a promising alternative, but their effectiveness for pre-commit secure code review is not yet well understood. In this work, we introduce AgenticSCR, an agentic AI for secure code review for detecting immature vulnerabilities during the pre-commit stage, augmented by security-focused semantic memories. Using our own curated benchmark of immature vulnerabilities, tailored to the pre-commit secure code review, we empirically evaluate how accurate is our AgenticSCR for localizing, detecting, and explaining immature vulnerabilities. Our results show that AgenticSCR achieves at least 153% relatively higher percentage of correct code review comments than the static LLM-based baseline, and also substantially surpasses SAST tools. Moreover, AgenticSCR generates more correct comments in four out of five vulnerability types, consistently and significantly outperforming all other baselines. These findings highlight the importance of Agentic Secure Code Review, paving the way towards an emerging research area of immature vulnerability detection.
arXiv:2601.19138v1 Announce Type: cross
Abstract: Secure code review is critical at the pre-commit stage, where vulnerabilities must be caught early under tight latency and limited-context constraints. Existing SAST-based checks are noisy and often miss immature, context-dependent vulnerabilities, while standalone Large Language Models (LLMs) are constrained by context windows and lack explicit tool use. Agentic AI, which combine LLMs with autonomous decision-making, tool invocation, and code navigation, offer a promising alternative, but their effectiveness for pre-commit secure code review is not yet well understood. In this work, we introduce AgenticSCR, an agentic AI for secure code review for detecting immature vulnerabilities during the pre-commit stage, augmented by security-focused semantic memories. Using our own curated benchmark of immature vulnerabilities, tailored to the pre-commit secure code review, we empirically evaluate how accurate is our AgenticSCR for localizing, detecting, and explaining immature vulnerabilities. Our results show that AgenticSCR achieves at least 153% relatively higher percentage of correct code review comments than the static LLM-based baseline, and also substantially surpasses SAST tools. Moreover, AgenticSCR generates more correct comments in four out of five vulnerability types, consistently and significantly outperforming all other baselines. These findings highlight the importance of Agentic Secure Code Review, paving the way towards an emerging research area of immature vulnerability detection. Read More
GradPruner: Gradient-Guided Layer Pruning Enabling Efficient Fine-Tuning and Inference for LLMscs.AI updates on arXiv.org arXiv:2601.19503v1 Announce Type: cross
Abstract: Fine-tuning Large Language Models (LLMs) with downstream data is often considered time-consuming and expensive. Structured pruning methods are primarily employed to improve the inference efficiency of pre-trained models. Meanwhile, they often require additional time and memory for training, knowledge distillation, structure search, and other strategies, making efficient model fine-tuning challenging to achieve. To simultaneously enhance the training and inference efficiency of downstream task fine-tuning, we introduce GradPruner, which can prune layers of LLMs guided by gradients in the early stages of fine-tuning. GradPruner uses the cumulative gradients of each parameter during the initial phase of fine-tuning to compute the Initial Gradient Information Accumulation Matrix (IGIA-Matrix) to assess the importance of layers and perform pruning. We sparsify the pruned layers based on the IGIA-Matrix and merge them with the remaining layers. Only elements with the same sign are merged to reduce interference from sign variations. We conducted extensive experiments on two LLMs across eight downstream datasets. Including medical, financial, and general benchmark tasks. The results demonstrate that GradPruner has achieved a parameter reduction of 40% with only a 0.99% decrease in accuracy. Our code is publicly available.
arXiv:2601.19503v1 Announce Type: cross
Abstract: Fine-tuning Large Language Models (LLMs) with downstream data is often considered time-consuming and expensive. Structured pruning methods are primarily employed to improve the inference efficiency of pre-trained models. Meanwhile, they often require additional time and memory for training, knowledge distillation, structure search, and other strategies, making efficient model fine-tuning challenging to achieve. To simultaneously enhance the training and inference efficiency of downstream task fine-tuning, we introduce GradPruner, which can prune layers of LLMs guided by gradients in the early stages of fine-tuning. GradPruner uses the cumulative gradients of each parameter during the initial phase of fine-tuning to compute the Initial Gradient Information Accumulation Matrix (IGIA-Matrix) to assess the importance of layers and perform pruning. We sparsify the pruned layers based on the IGIA-Matrix and merge them with the remaining layers. Only elements with the same sign are merged to reduce interference from sign variations. We conducted extensive experiments on two LLMs across eight downstream datasets. Including medical, financial, and general benchmark tasks. The results demonstrate that GradPruner has achieved a parameter reduction of 40% with only a 0.99% decrease in accuracy. Our code is publicly available. Read More
From Observations to Events: Event-Aware World Model for Reinforcement Learningcs.AI updates on arXiv.org arXiv:2601.19336v1 Announce Type: cross
Abstract: While model-based reinforcement learning (MBRL) improves sample efficiency by learning world models from raw observations, existing methods struggle to generalize across structurally similar scenes and remain vulnerable to spurious variations such as textures or color shifts. From a cognitive science perspective, humans segment continuous sensory streams into discrete events and rely on these key events for decision-making. Motivated by this principle, we propose the Event-Aware World Model (EAWM), a general framework that learns event-aware representations to streamline policy learning without requiring handcrafted labels. EAWM employs an automated event generator to derive events from raw observations and introduces a Generic Event Segmentor (GES) to identify event boundaries, which mark the start and end time of event segments. Through event prediction, the representation space is shaped to capture meaningful spatio-temporal transitions. Beyond this, we present a unified formulation of seemingly distinct world model architectures and show the broad applicability of our methods. Experiments on Atari 100K, Craftax 1M, and DeepMind Control 500K, DMC-GB2 500K demonstrate that EAWM consistently boosts the performance of strong MBRL baselines by 10%-45%, setting new state-of-the-art results across benchmarks. Our code is released at https://github.com/MarquisDarwin/EAWM.
arXiv:2601.19336v1 Announce Type: cross
Abstract: While model-based reinforcement learning (MBRL) improves sample efficiency by learning world models from raw observations, existing methods struggle to generalize across structurally similar scenes and remain vulnerable to spurious variations such as textures or color shifts. From a cognitive science perspective, humans segment continuous sensory streams into discrete events and rely on these key events for decision-making. Motivated by this principle, we propose the Event-Aware World Model (EAWM), a general framework that learns event-aware representations to streamline policy learning without requiring handcrafted labels. EAWM employs an automated event generator to derive events from raw observations and introduces a Generic Event Segmentor (GES) to identify event boundaries, which mark the start and end time of event segments. Through event prediction, the representation space is shaped to capture meaningful spatio-temporal transitions. Beyond this, we present a unified formulation of seemingly distinct world model architectures and show the broad applicability of our methods. Experiments on Atari 100K, Craftax 1M, and DeepMind Control 500K, DMC-GB2 500K demonstrate that EAWM consistently boosts the performance of strong MBRL baselines by 10%-45%, setting new state-of-the-art results across benchmarks. Our code is released at https://github.com/MarquisDarwin/EAWM. Read More
Tencent Hunyuan Releases HPC-Ops: A High Performance LLM Inference Operator LibraryMarkTechPost Tencent Hunyuan has open sourced HPC-Ops, a production grade operator library for large language model inference architecture devices. HPC-Ops focuses on low level CUDA kernels for core operators such as Attention, Grouped GEMM, and Fused MoE, and exposes them through a compact-C and Python API for integration into existing inference stacks. HPC-Ops runs in large
The post Tencent Hunyuan Releases HPC-Ops: A High Performance LLM Inference Operator Library appeared first on MarkTechPost.
Tencent Hunyuan has open sourced HPC-Ops, a production grade operator library for large language model inference architecture devices. HPC-Ops focuses on low level CUDA kernels for core operators such as Attention, Grouped GEMM, and Fused MoE, and exposes them through a compact-C and Python API for integration into existing inference stacks. HPC-Ops runs in large
The post Tencent Hunyuan Releases HPC-Ops: A High Performance LLM Inference Operator Library appeared first on MarkTechPost. Read More

Moonshot AI Releases Kimi K2.5: An Open Source Visual Agentic Intelligence Model with Native Swarm ExecutionMarkTechPost Moonshot AI has released Kimi K2.5 as an open source visual agentic intelligence model. It combines a large Mixture of Experts language backbone, a native vision encoder, and a parallel multi agent system called Agent Swarm. The model targets coding, multimodal reasoning, and deep web research with strong benchmark results on agentic, vision, and coding
The post Moonshot AI Releases Kimi K2.5: An Open Source Visual Agentic Intelligence Model with Native Swarm Execution appeared first on MarkTechPost.
Moonshot AI has released Kimi K2.5 as an open source visual agentic intelligence model. It combines a large Mixture of Experts language backbone, a native vision encoder, and a parallel multi agent system called Agent Swarm. The model targets coding, multimodal reasoning, and deep web research with strong benchmark results on agentic, vision, and coding
The post Moonshot AI Releases Kimi K2.5: An Open Source Visual Agentic Intelligence Model with Native Swarm Execution appeared first on MarkTechPost. Read More
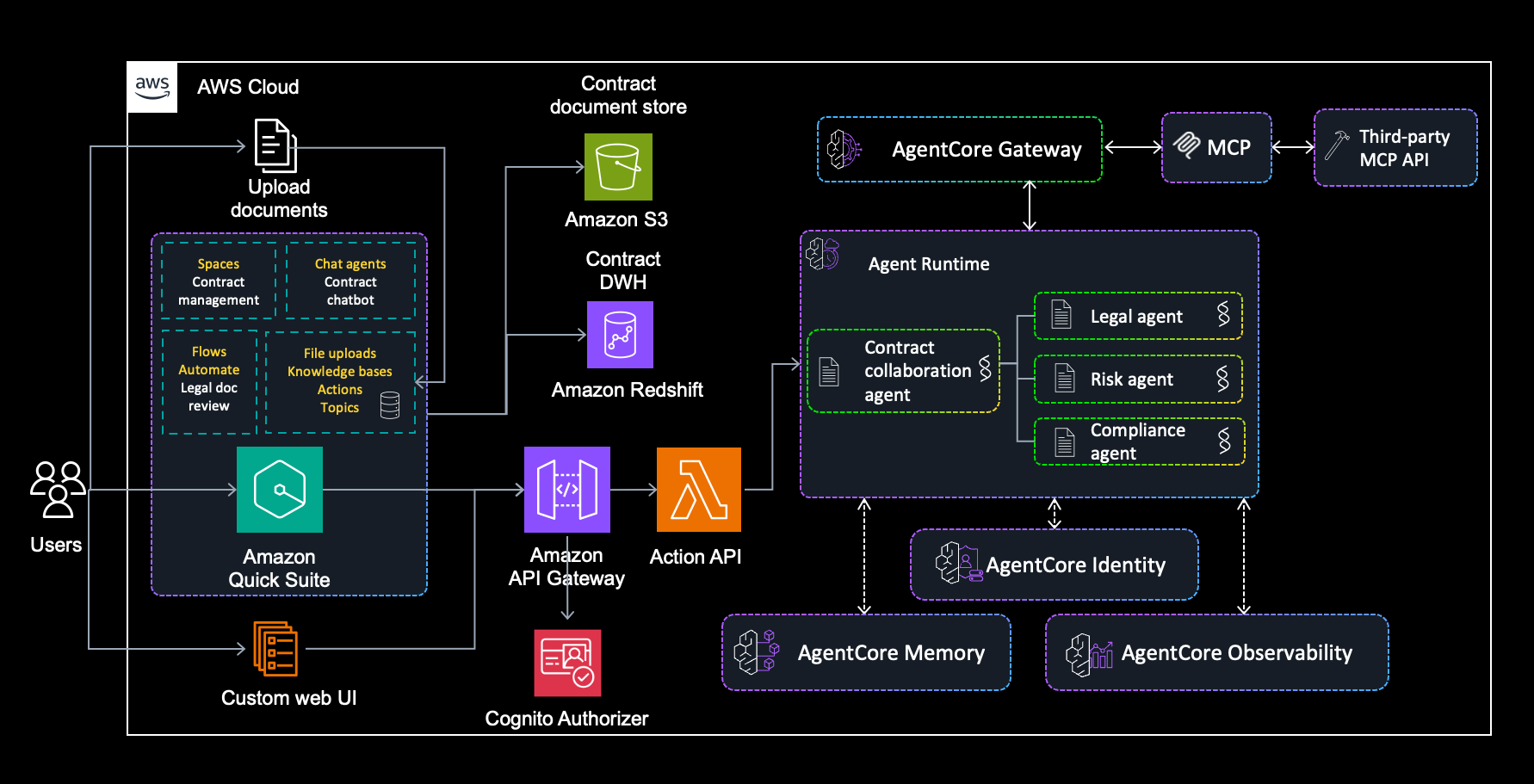
Build an intelligent contract management solution with Amazon Quick Suite and Bedrock AgentCoreArtificial Intelligence This blog post demonstrates how to build an intelligent contract management solution using Amazon Quick Suite as your primary contract management solution, augmented with Amazon Bedrock AgentCore for advanced multi-agent capabilities.
This blog post demonstrates how to build an intelligent contract management solution using Amazon Quick Suite as your primary contract management solution, augmented with Amazon Bedrock AgentCore for advanced multi-agent capabilities. Read More