
How to Run Claude Code for Free with Local and Cloud Models from OllamaTowards Data Science Ollama now offers Anthropic API compatibility
The post How to Run Claude Code for Free with Local and Cloud Models from Ollama appeared first on Towards Data Science.
Ollama now offers Anthropic API compatibility
The post How to Run Claude Code for Free with Local and Cloud Models from Ollama appeared first on Towards Data Science. Read More
How to Apply Agentic Coding to Solve ProblemsTowards Data Science Learn how to efficiently solve problems with coding agents
The post How to Apply Agentic Coding to Solve Problems appeared first on Towards Data Science.
Learn how to efficiently solve problems with coding agents
The post How to Apply Agentic Coding to Solve Problems appeared first on Towards Data Science. Read More
Why Your Multi-Agent System is Failing: Escaping the 17x Error Trap of the “Bag of Agents”Towards Data Science Hard-won lessons on how to scale agentic systems without scaling the chaos, including a taxonomy of core agent types.
The post Why Your Multi-Agent System is Failing: Escaping the 17x Error Trap of the “Bag of Agents” appeared first on Towards Data Science.
Hard-won lessons on how to scale agentic systems without scaling the chaos, including a taxonomy of core agent types.
The post Why Your Multi-Agent System is Failing: Escaping the 17x Error Trap of the “Bag of Agents” appeared first on Towards Data Science. Read More
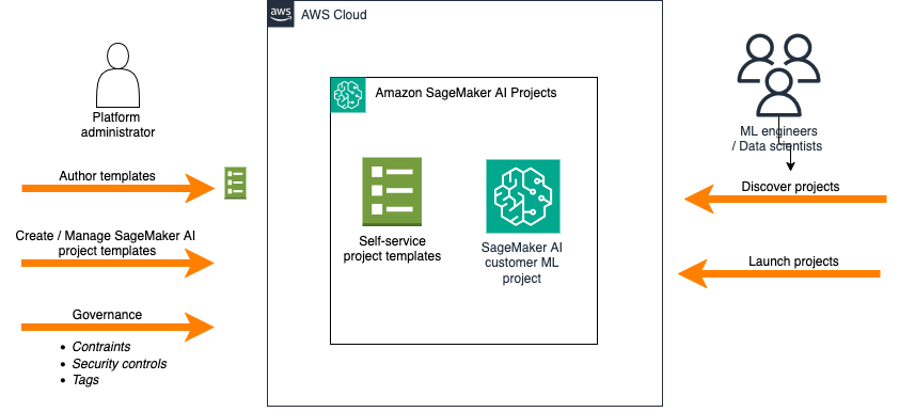
Simplify ModelOps with Amazon SageMaker AI Projects using Amazon S3-based templatesArtificial Intelligence This post explores how you can use Amazon S3-based templates to simplify ModelOps workflows, walk through the key benefits compared to using Service Catalog approaches, and demonstrates how to create a custom ModelOps solution that integrates with GitHub and GitHub Actions—giving your team one-click provisioning of a fully functional ML environment.
This post explores how you can use Amazon S3-based templates to simplify ModelOps workflows, walk through the key benefits compared to using Service Catalog approaches, and demonstrates how to create a custom ModelOps solution that integrates with GitHub and GitHub Actions—giving your team one-click provisioning of a fully functional ML environment. Read More

Scale AI in South Africa using Amazon Bedrock global cross-Region inference with Anthropic Claude 4.5 modelsArtificial Intelligence In this post, we walk through how global cross-Region inference routes requests and where your data resides, then show you how to configure the required AWS Identity and Access Management (IAM) permissions and invoke Claude 4.5 models using the global inference profile Amazon Resource Name (ARN). We also cover how to request quota increases for your workload. By the end, you’ll have a working implementation of global cross-Region inference in af-south-1.
In this post, we walk through how global cross-Region inference routes requests and where your data resides, then show you how to configure the required AWS Identity and Access Management (IAM) permissions and invoke Claude 4.5 models using the global inference profile Amazon Resource Name (ARN). We also cover how to request quota increases for your workload. By the end, you’ll have a working implementation of global cross-Region inference in af-south-1. Read More
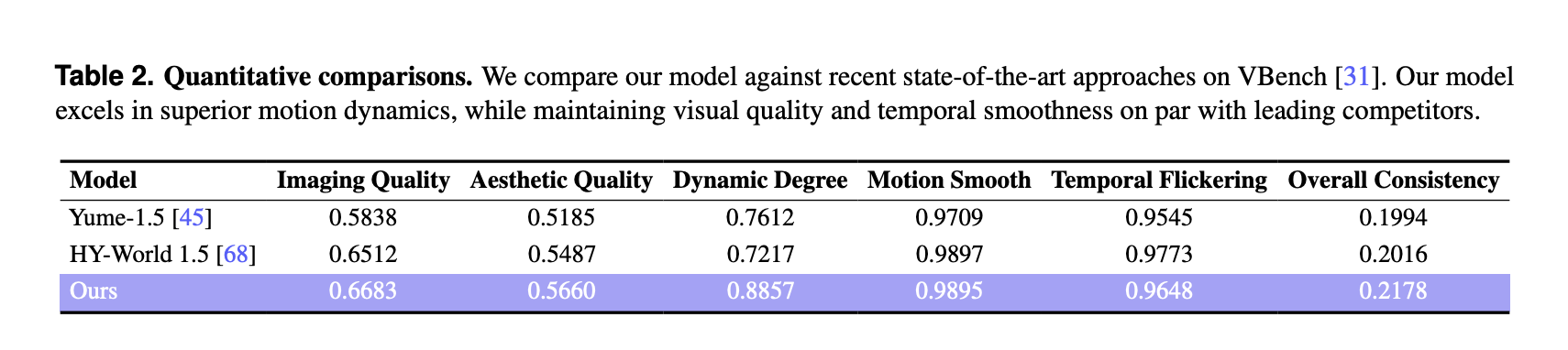
Robbyant Open Sources LingBot World: a Real Time World Model for Interactive Simulation and Embodied AIMarkTechPost Robbyant, the embodied AI unit inside Ant Group, has open sourced LingBot-World, a large scale world model that turns video generation into an interactive simulator for embodied agents, autonomous driving and games. The system is designed to render controllable environments with high visual fidelity, strong dynamics and long temporal horizons, while staying responsive enough for
The post Robbyant Open Sources LingBot World: a Real Time World Model for Interactive Simulation and Embodied AI appeared first on MarkTechPost.
Robbyant, the embodied AI unit inside Ant Group, has open sourced LingBot-World, a large scale world model that turns video generation into an interactive simulator for embodied agents, autonomous driving and games. The system is designed to render controllable environments with high visual fidelity, strong dynamics and long temporal horizons, while staying responsive enough for
The post Robbyant Open Sources LingBot World: a Real Time World Model for Interactive Simulation and Embodied AI appeared first on MarkTechPost. Read More
A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEENMarkTechPost In this tutorial, we walk through an end-to-end, advanced workflow for knowledge graph embeddings using PyKEEN, actively exploring how modern embedding models are trained, evaluated, optimized, and interpreted in practice. We start by understanding the structure of a real knowledge graph dataset, then systematically train and compare multiple embedding models, tune their hyperparameters, and analyze
The post A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEEN appeared first on MarkTechPost.
In this tutorial, we walk through an end-to-end, advanced workflow for knowledge graph embeddings using PyKEEN, actively exploring how modern embedding models are trained, evaluated, optimized, and interpreted in practice. We start by understanding the structure of a real knowledge graph dataset, then systematically train and compare multiple embedding models, tune their hyperparameters, and analyze
The post A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEEN appeared first on MarkTechPost. Read More
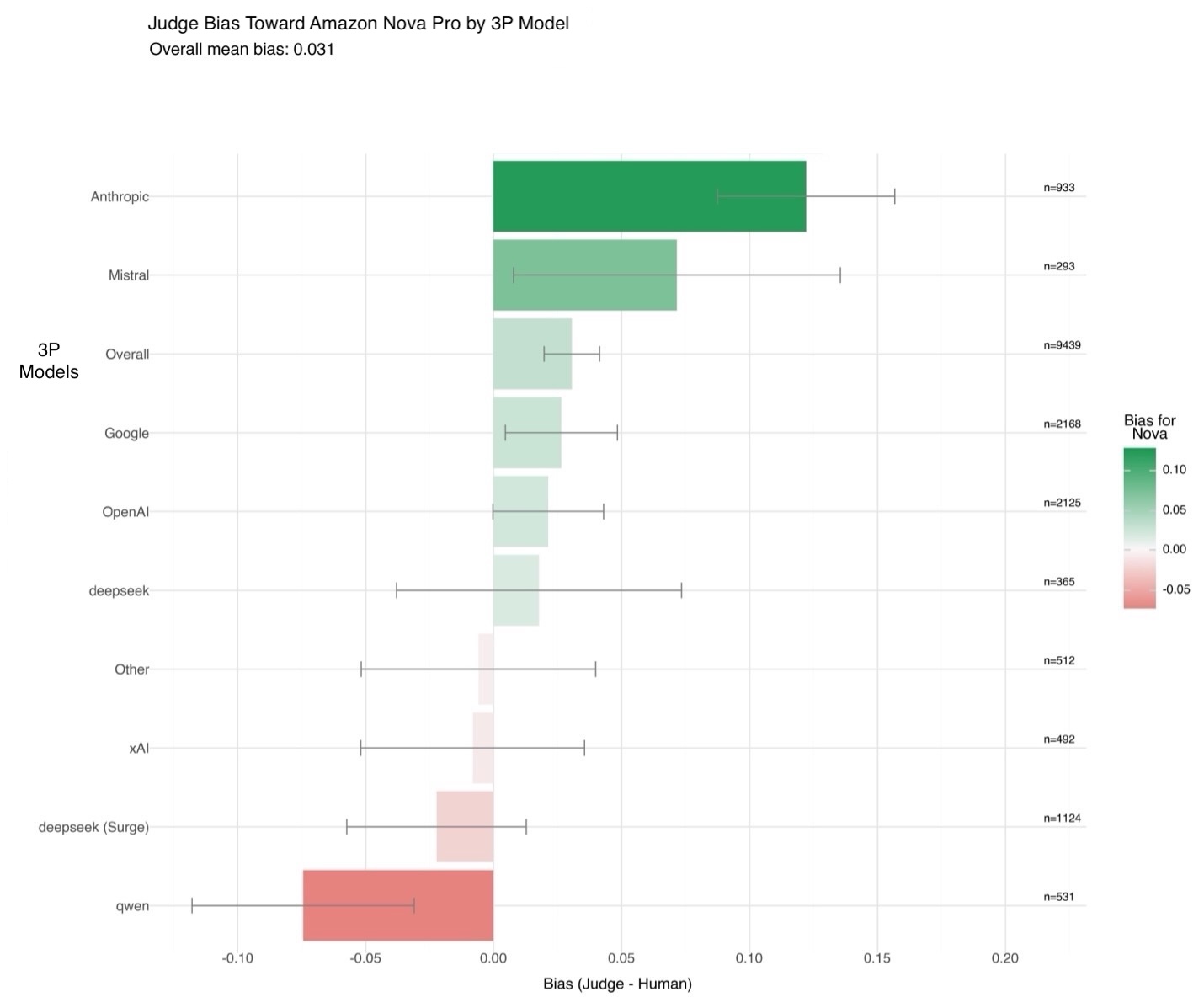
Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AIArtificial Intelligence Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation,
Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation, Read More
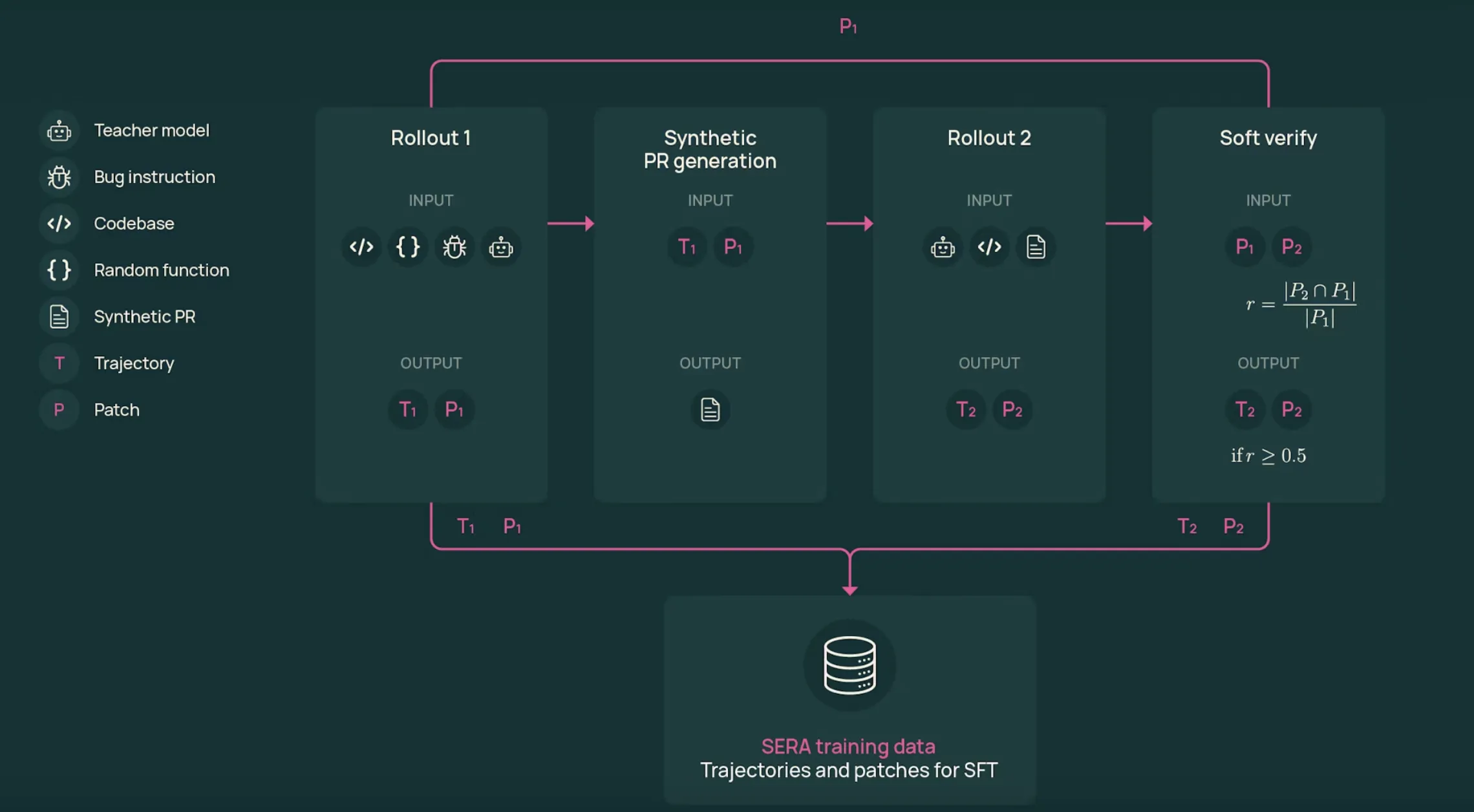
AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation WorkflowsMarkTechPost Allen Institute for AI (AI2) Researchers introduce SERA, Soft Verified Efficient Repository Agents, as a coding agent family that aims to match much larger closed systems using only supervised training and synthetic trajectories. What is SERA? SERA is the first release in AI2’s Open Coding Agents series. The flagship model, SERA-32B, is built on the
The post AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation Workflows appeared first on MarkTechPost.
Allen Institute for AI (AI2) Researchers introduce SERA, Soft Verified Efficient Repository Agents, as a coding agent family that aims to match much larger closed systems using only supervised training and synthetic trajectories. What is SERA? SERA is the first release in AI2’s Open Coding Agents series. The flagship model, SERA-32B, is built on the
The post AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation Workflows appeared first on MarkTechPost. Read More
Large language models accurately predict public perceptions of support for climate action worldwidecs.AI updates on arXiv.org arXiv:2601.20141v1 Announce Type: cross
Abstract: Although most people support climate action, widespread underestimation of others’ support stalls individual and systemic changes. In this preregistered experiment, we test whether large language models (LLMs) can reliably predict these perception gaps worldwide. Using country-level indicators and public opinion data from 125 countries, we benchmark four state-of-the-art LLMs against Gallup World Poll 2021/22 data and statistical regressions. LLMs, particularly Claude, accurately capture public perceptions of others’ willingness to contribute financially to climate action (MAE approximately 5 p.p.; r = .77), comparable to statistical models, though performance declines in less digitally connected, lower-GDP countries. Controlled tests show that LLMs capture the key psychological process – social projection with a systematic downward bias – and rely on structured reasoning rather than memorized values. Overall, LLMs provide a rapid tool for assessing perception gaps in climate action, serving as an alternative to costly surveys in resource-rich countries and as a complement in underrepresented populations.
arXiv:2601.20141v1 Announce Type: cross
Abstract: Although most people support climate action, widespread underestimation of others’ support stalls individual and systemic changes. In this preregistered experiment, we test whether large language models (LLMs) can reliably predict these perception gaps worldwide. Using country-level indicators and public opinion data from 125 countries, we benchmark four state-of-the-art LLMs against Gallup World Poll 2021/22 data and statistical regressions. LLMs, particularly Claude, accurately capture public perceptions of others’ willingness to contribute financially to climate action (MAE approximately 5 p.p.; r = .77), comparable to statistical models, though performance declines in less digitally connected, lower-GDP countries. Controlled tests show that LLMs capture the key psychological process – social projection with a systematic downward bias – and rely on structured reasoning rather than memorized values. Overall, LLMs provide a rapid tool for assessing perception gaps in climate action, serving as an alternative to costly surveys in resource-rich countries and as a complement in underrepresented populations. Read More