
Toward a benchmark for CTR prediction in online advertising: datasets, evaluation protocols and perspectivescs.AI updates on arXiv.org arXiv:2512.01179v1 Announce Type: cross
Abstract: This research designs a unified architecture of CTR prediction benchmark (Bench-CTR) platform that offers flexible interfaces with datasets and components of a wide range of CTR prediction models. Moreover, we construct a comprehensive system of evaluation protocols encompassing real-world and synthetic datasets, a taxonomy of metrics, standardized procedures and experimental guidelines for calibrating the performance of CTR prediction models. Furthermore, we implement the proposed benchmark platform and conduct a comparative study to evaluate a wide range of state-of-the-art models from traditional multivariate statistical to modern large language model (LLM)-based approaches on three public datasets and two synthetic datasets. Experimental results reveal that, (1) high-order models largely outperform low-order models, though such advantage varies in terms of metrics and on different datasets; (2) LLM-based models demonstrate a remarkable data efficiency, i.e., achieving the comparable performance to other models while using only 2% of the training data; (3) the performance of CTR prediction models has achieved significant improvements from 2015 to 2016, then reached a stage with slow progress, which is consistent across various datasets. This benchmark is expected to facilitate model development and evaluation and enhance practitioners’ understanding of the underlying mechanisms of models in the area of CTR prediction. Code is available at https://github.com/NuriaNinja/Bench-CTR.
arXiv:2512.01179v1 Announce Type: cross
Abstract: This research designs a unified architecture of CTR prediction benchmark (Bench-CTR) platform that offers flexible interfaces with datasets and components of a wide range of CTR prediction models. Moreover, we construct a comprehensive system of evaluation protocols encompassing real-world and synthetic datasets, a taxonomy of metrics, standardized procedures and experimental guidelines for calibrating the performance of CTR prediction models. Furthermore, we implement the proposed benchmark platform and conduct a comparative study to evaluate a wide range of state-of-the-art models from traditional multivariate statistical to modern large language model (LLM)-based approaches on three public datasets and two synthetic datasets. Experimental results reveal that, (1) high-order models largely outperform low-order models, though such advantage varies in terms of metrics and on different datasets; (2) LLM-based models demonstrate a remarkable data efficiency, i.e., achieving the comparable performance to other models while using only 2% of the training data; (3) the performance of CTR prediction models has achieved significant improvements from 2015 to 2016, then reached a stage with slow progress, which is consistent across various datasets. This benchmark is expected to facilitate model development and evaluation and enhance practitioners’ understanding of the underlying mechanisms of models in the area of CTR prediction. Code is available at https://github.com/NuriaNinja/Bench-CTR. Read More

Anthropic just revealed how AI-orchestrated cyberattacks actually work—Here’s what enterprises need to knowAI News For years, cybersecurity experts debated when – not if – artificial intelligence would cross the threshold from advisor to autonomous attacker. That theoretical milestone has arrived. Anthropic’s recent investigation into a Chinese state-sponsored operation has documented [PDF] the first case of AI-orchestrated cyber attacks executing at scale with minimal human oversight, altering what enterprises must
The post Anthropic just revealed how AI-orchestrated cyberattacks actually work—Here’s what enterprises need to know appeared first on AI News.
For years, cybersecurity experts debated when – not if – artificial intelligence would cross the threshold from advisor to autonomous attacker. That theoretical milestone has arrived. Anthropic’s recent investigation into a Chinese state-sponsored operation has documented [PDF] the first case of AI-orchestrated cyber attacks executing at scale with minimal human oversight, altering what enterprises must
The post Anthropic just revealed how AI-orchestrated cyberattacks actually work—Here’s what enterprises need to know appeared first on AI News. Read More
DF-Mamba: Deformable State Space Modeling for 3D Hand Pose Estimation in Interactionscs.AI updates on arXiv.org arXiv:2512.02727v1 Announce Type: cross
Abstract: Modeling daily hand interactions often struggles with severe occlusions, such as when two hands overlap, which highlights the need for robust feature learning in 3D hand pose estimation (HPE). To handle such occluded hand images, it is vital to effectively learn the relationship between local image features (e.g., for occluded joints) and global context (e.g., cues from inter-joints, inter-hands, or the scene). However, most current 3D HPE methods still rely on ResNet for feature extraction, and such CNN’s inductive bias may not be optimal for 3D HPE due to its limited capability to model the global context. To address this limitation, we propose an effective and efficient framework for visual feature extraction in 3D HPE using recent state space modeling (i.e., Mamba), dubbed Deformable Mamba (DF-Mamba). DF-Mamba is designed to capture global context cues beyond standard convolution through Mamba’s selective state modeling and the proposed deformable state scanning. Specifically, for local features after convolution, our deformable scanning aggregates these features within an image while selectively preserving useful cues that represent the global context. This approach significantly improves the accuracy of structured 3D HPE, with comparable inference speed to ResNet-50. Our experiments involve extensive evaluations on five divergent datasets including single-hand and two-hand scenarios, hand-only and hand-object interactions, as well as RGB and depth-based estimation. DF-Mamba outperforms the latest image backbones, including VMamba and Spatial-Mamba, on all datasets and achieves state-of-the-art performance.
arXiv:2512.02727v1 Announce Type: cross
Abstract: Modeling daily hand interactions often struggles with severe occlusions, such as when two hands overlap, which highlights the need for robust feature learning in 3D hand pose estimation (HPE). To handle such occluded hand images, it is vital to effectively learn the relationship between local image features (e.g., for occluded joints) and global context (e.g., cues from inter-joints, inter-hands, or the scene). However, most current 3D HPE methods still rely on ResNet for feature extraction, and such CNN’s inductive bias may not be optimal for 3D HPE due to its limited capability to model the global context. To address this limitation, we propose an effective and efficient framework for visual feature extraction in 3D HPE using recent state space modeling (i.e., Mamba), dubbed Deformable Mamba (DF-Mamba). DF-Mamba is designed to capture global context cues beyond standard convolution through Mamba’s selective state modeling and the proposed deformable state scanning. Specifically, for local features after convolution, our deformable scanning aggregates these features within an image while selectively preserving useful cues that represent the global context. This approach significantly improves the accuracy of structured 3D HPE, with comparable inference speed to ResNet-50. Our experiments involve extensive evaluations on five divergent datasets including single-hand and two-hand scenarios, hand-only and hand-object interactions, as well as RGB and depth-based estimation. DF-Mamba outperforms the latest image backbones, including VMamba and Spatial-Mamba, on all datasets and achieves state-of-the-art performance. Read More
Pianist Transformer: Towards Expressive Piano Performance Rendering via Scalable Self-Supervised Pre-Trainingcs.AI updates on arXiv.org arXiv:2512.02652v1 Announce Type: cross
Abstract: Existing methods for expressive music performance rendering rely on supervised learning over small labeled datasets, which limits scaling of both data volume and model size, despite the availability of vast unlabeled music, as in vision and language. To address this gap, we introduce Pianist Transformer, with four key contributions: 1) a unified Musical Instrument Digital Interface (MIDI) data representation for learning the shared principles of musical structure and expression without explicit annotation; 2) an efficient asymmetric architecture, enabling longer contexts and faster inference without sacrificing rendering quality; 3) a self-supervised pre-training pipeline with 10B tokens and 135M-parameter model, unlocking data and model scaling advantages for expressive performance rendering; 4) a state-of-the-art performance model, which achieves strong objective metrics and human-level subjective ratings. Overall, Pianist Transformer establishes a scalable path toward human-like performance synthesis in the music domain.
arXiv:2512.02652v1 Announce Type: cross
Abstract: Existing methods for expressive music performance rendering rely on supervised learning over small labeled datasets, which limits scaling of both data volume and model size, despite the availability of vast unlabeled music, as in vision and language. To address this gap, we introduce Pianist Transformer, with four key contributions: 1) a unified Musical Instrument Digital Interface (MIDI) data representation for learning the shared principles of musical structure and expression without explicit annotation; 2) an efficient asymmetric architecture, enabling longer contexts and faster inference without sacrificing rendering quality; 3) a self-supervised pre-training pipeline with 10B tokens and 135M-parameter model, unlocking data and model scaling advantages for expressive performance rendering; 4) a state-of-the-art performance model, which achieves strong objective metrics and human-level subjective ratings. Overall, Pianist Transformer establishes a scalable path toward human-like performance synthesis in the music domain. Read More
Projecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometrycs.AI updates on arXiv.org arXiv:2503.01822v2 Announce Type: replace-cross
Abstract: Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from their representations. However, do SAEs truly uncover all concepts a model relies on, or are they inherently biased toward certain kinds of concepts? We introduce a unified framework that recasts SAEs as solutions to a bilevel optimization problem, revealing a fundamental challenge: each SAE imposes structural assumptions about how concepts are encoded in model representations, which in turn shapes what it can and cannot detect. This means different SAEs are not interchangeable — switching architectures can expose entirely new concepts or obscure existing ones. To systematically probe this effect, we evaluate SAEs across a spectrum of settings: from controlled toy models that isolate key variables, to semi-synthetic experiments on real model activations and finally to large-scale, naturalistic datasets. Across this progression, we examine two fundamental properties that real-world concepts often exhibit: heterogeneity in intrinsic dimensionality (some concepts are inherently low-dimensional, others are not) and nonlinear separability. We show that SAEs fail to recover concepts when these properties are ignored, and we design a new SAE that explicitly incorporates both, enabling the discovery of previously hidden concepts and reinforcing our theoretical insights. Our findings challenge the idea of a universal SAE and underscores the need for architecture-specific choices in model interpretability. Overall, we argue an SAE does not just reveal concepts — it determines what can be seen at all.
arXiv:2503.01822v2 Announce Type: replace-cross
Abstract: Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from their representations. However, do SAEs truly uncover all concepts a model relies on, or are they inherently biased toward certain kinds of concepts? We introduce a unified framework that recasts SAEs as solutions to a bilevel optimization problem, revealing a fundamental challenge: each SAE imposes structural assumptions about how concepts are encoded in model representations, which in turn shapes what it can and cannot detect. This means different SAEs are not interchangeable — switching architectures can expose entirely new concepts or obscure existing ones. To systematically probe this effect, we evaluate SAEs across a spectrum of settings: from controlled toy models that isolate key variables, to semi-synthetic experiments on real model activations and finally to large-scale, naturalistic datasets. Across this progression, we examine two fundamental properties that real-world concepts often exhibit: heterogeneity in intrinsic dimensionality (some concepts are inherently low-dimensional, others are not) and nonlinear separability. We show that SAEs fail to recover concepts when these properties are ignored, and we design a new SAE that explicitly incorporates both, enabling the discovery of previously hidden concepts and reinforcing our theoretical insights. Our findings challenge the idea of a universal SAE and underscores the need for architecture-specific choices in model interpretability. Overall, we argue an SAE does not just reveal concepts — it determines what can be seen at all. Read More
How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward LearningMarkTechPost In this tutorial, we explore Online Process Reward Learning (OPRL) and demonstrate how we can learn dense, step-level reward signals from trajectory preferences to solve sparse-reward reinforcement learning tasks. We walk through each component, from the maze environment and reward-model network to preference generation, training loops, and evaluation, while observing how the agent gradually improves
The post How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward Learning appeared first on MarkTechPost.
In this tutorial, we explore Online Process Reward Learning (OPRL) and demonstrate how we can learn dense, step-level reward signals from trajectory preferences to solve sparse-reward reinforcement learning tasks. We walk through each component, from the maze environment and reward-model network to preference generation, training loops, and evaluation, while observing how the agent gradually improves
The post How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward Learning appeared first on MarkTechPost. Read More
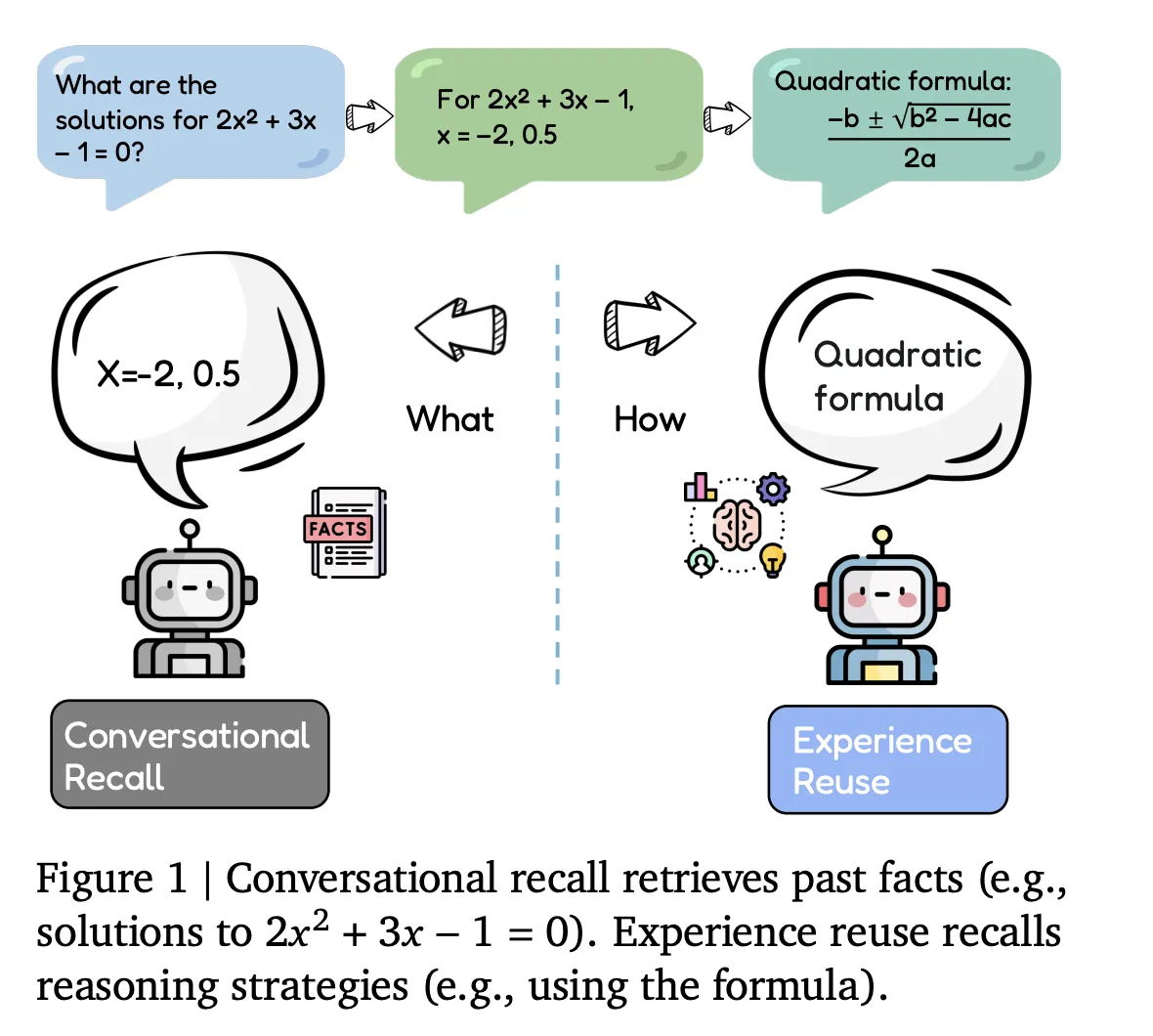
Google DeepMind Researchers Introduce Evo-Memory Benchmark and ReMem Framework for Experience Reuse in LLM AgentsMarkTechPost Large language model agents are starting to store everything they see, but can they actually improve their policies at test time from those experiences rather than just replaying context windows? Researchers from University of Illinois Urbana Champaign and Google DeepMind propose Evo-Memory, a streaming benchmark and agent framework that targets this exact gap. Evo-Memory evaluates
The post Google DeepMind Researchers Introduce Evo-Memory Benchmark and ReMem Framework for Experience Reuse in LLM Agents appeared first on MarkTechPost.
Large language model agents are starting to store everything they see, but can they actually improve their policies at test time from those experiences rather than just replaying context windows? Researchers from University of Illinois Urbana Champaign and Google DeepMind propose Evo-Memory, a streaming benchmark and agent framework that targets this exact gap. Evo-Memory evaluates
The post Google DeepMind Researchers Introduce Evo-Memory Benchmark and ReMem Framework for Experience Reuse in LLM Agents appeared first on MarkTechPost. Read More

New control system teaches soft robots the art of staying safeMIT News – Machine learning MIT CSAIL and LIDS researchers developed a mathematically grounded system that lets soft robots deform, adapt, and interact with people and objects, without violating safety limits.
MIT CSAIL and LIDS researchers developed a mathematically grounded system that lets soft robots deform, adapt, and interact with people and objects, without violating safety limits. Read More
The Machine Learning “Advent Calendar” Day 2: k-NN Classifier in ExcelTowards Data Science Exploring the k-NN classifier with its variants and improvements
The post The Machine Learning “Advent Calendar” Day 2: k-NN Classifier in Excel appeared first on Towards Data Science.
Exploring the k-NN classifier with its variants and improvements
The post The Machine Learning “Advent Calendar” Day 2: k-NN Classifier in Excel appeared first on Towards Data Science. Read More
JSON Parsing for Large Payloads: Balancing Speed, Memory, and ScalabilityTowards Data Science Benchmarking JSON libraries for large payloads
The post JSON Parsing for Large Payloads: Balancing Speed, Memory, and Scalability appeared first on Towards Data Science.
Benchmarking JSON libraries for large payloads
The post JSON Parsing for Large Payloads: Balancing Speed, Memory, and Scalability appeared first on Towards Data Science. Read More