
Klarna backs Google UCP to power AI agent paymentsAI News Klarna aims to address the lack of interoperability between conversational AI agents and backend payment systems by backing Google’s Universal Commerce Protocol (UCP), an open standard designed to unify how AI agents discover products and execute transactions. The partnership, which also sees Klarna supporting Google’s Agent Payments Protocol (AP2), places the Swedish fintech firm among
The post Klarna backs Google UCP to power AI agent payments appeared first on AI News.
Klarna aims to address the lack of interoperability between conversational AI agents and backend payment systems by backing Google’s Universal Commerce Protocol (UCP), an open standard designed to unify how AI agents discover products and execute transactions. The partnership, which also sees Klarna supporting Google’s Agent Payments Protocol (AP2), places the Swedish fintech firm among
The post Klarna backs Google UCP to power AI agent payments appeared first on AI News. Read More

5 Android Apps for Code EditingKDnuggets From debugging to quick fixes, here are the top Android apps every developer should have on their phone.
From debugging to quick fixes, here are the top Android apps every developer should have on their phone. Read More

Silicon Darwinism: Why Scarcity Is the Source of True IntelligenceTowards Data Science We are confusing “size” with “smart.” The next leap in artificial intelligence will not come from a larger data center, but from a more constrained environment.
The post Silicon Darwinism: Why Scarcity Is the Source of True Intelligence appeared first on Towards Data Science.
We are confusing “size” with “smart.” The next leap in artificial intelligence will not come from a larger data center, but from a more constrained environment.
The post Silicon Darwinism: Why Scarcity Is the Source of True Intelligence appeared first on Towards Data Science. Read More

The Statistical Cost of Zero Padding in Convolutional Neural Networks (CNNs)MarkTechPost What is Zero Padding Zero padding is a technique used in convolutional neural networks where additional pixels with a value of zero are added around the borders of an image. This allows convolutional kernels to slide over edge pixels and helps control how much the spatial dimensions of the feature map shrink after convolution. Padding
The post The Statistical Cost of Zero Padding in Convolutional Neural Networks (CNNs) appeared first on MarkTechPost.
What is Zero Padding Zero padding is a technique used in convolutional neural networks where additional pixels with a value of zero are added around the borders of an image. This allows convolutional kernels to slide over edge pixels and helps control how much the spatial dimensions of the feature map shrink after convolution. Padding
The post The Statistical Cost of Zero Padding in Convolutional Neural Networks (CNNs) appeared first on MarkTechPost. Read More
How to Build Multi-Layered LLM Safety Filters to Defend Against Adaptive, Paraphrased, and Adversarial Prompt AttacksMarkTechPost In this tutorial, we build a robust, multi-layered safety filter designed to defend large language models against adaptive and paraphrased attacks. We combine semantic similarity analysis, rule-based pattern detection, LLM-driven intent classification, and anomaly detection to create a defense system that relies on no single point of failure. Also, we demonstrate how practical, production-style safety
The post How to Build Multi-Layered LLM Safety Filters to Defend Against Adaptive, Paraphrased, and Adversarial Prompt Attacks appeared first on MarkTechPost.
In this tutorial, we build a robust, multi-layered safety filter designed to defend large language models against adaptive and paraphrased attacks. We combine semantic similarity analysis, rule-based pattern detection, LLM-driven intent classification, and anomaly detection to create a defense system that relies on no single point of failure. Also, we demonstrate how practical, production-style safety
The post How to Build Multi-Layered LLM Safety Filters to Defend Against Adaptive, Paraphrased, and Adversarial Prompt Attacks appeared first on MarkTechPost. Read More
Google Releases Conductor: a context driven Gemini CLI extension that stores knowledge as Markdown and orchestrates agentic workflowsMarkTechPost Google has introduced Conductor, an open source preview extension for Gemini CLI that turns AI code generation into a structured, context driven workflow. Conductor stores product knowledge, technical decisions, and work plans as versioned Markdown inside the repository, then drives Gemini agents from those files instead of ad hoc chat prompts. From chat based coding
The post Google Releases Conductor: a context driven Gemini CLI extension that stores knowledge as Markdown and orchestrates agentic workflows appeared first on MarkTechPost.
Google has introduced Conductor, an open source preview extension for Gemini CLI that turns AI code generation into a structured, context driven workflow. Conductor stores product knowledge, technical decisions, and work plans as versioned Markdown inside the repository, then drives Gemini agents from those files instead of ad hoc chat prompts. From chat based coding
The post Google Releases Conductor: a context driven Gemini CLI extension that stores knowledge as Markdown and orchestrates agentic workflows appeared first on MarkTechPost. Read More
Semi-Autonomous Mathematics Discovery with Gemini: A Case Study on the ErdH{o}s Problemscs.AI updates on arXiv.org arXiv:2601.22401v1 Announce Type: new
Abstract: We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled ‘Open’ in Bloom’s ErdH{o}s Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked ‘Open’ in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the ‘Open’ status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ”subconscious plagiarism” by AI. We reflect on the takeaways from AI-assisted efforts on the ErdH{o}s Problems.
arXiv:2601.22401v1 Announce Type: new
Abstract: We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled ‘Open’ in Bloom’s ErdH{o}s Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked ‘Open’ in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the ‘Open’ status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ”subconscious plagiarism” by AI. We reflect on the takeaways from AI-assisted efforts on the ErdH{o}s Problems. Read More
FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attackscs.AI updates on arXiv.org arXiv:2601.22485v1 Announce Type: cross
Abstract: Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model’s generations.
arXiv:2601.22485v1 Announce Type: cross
Abstract: Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model’s generations. Read More
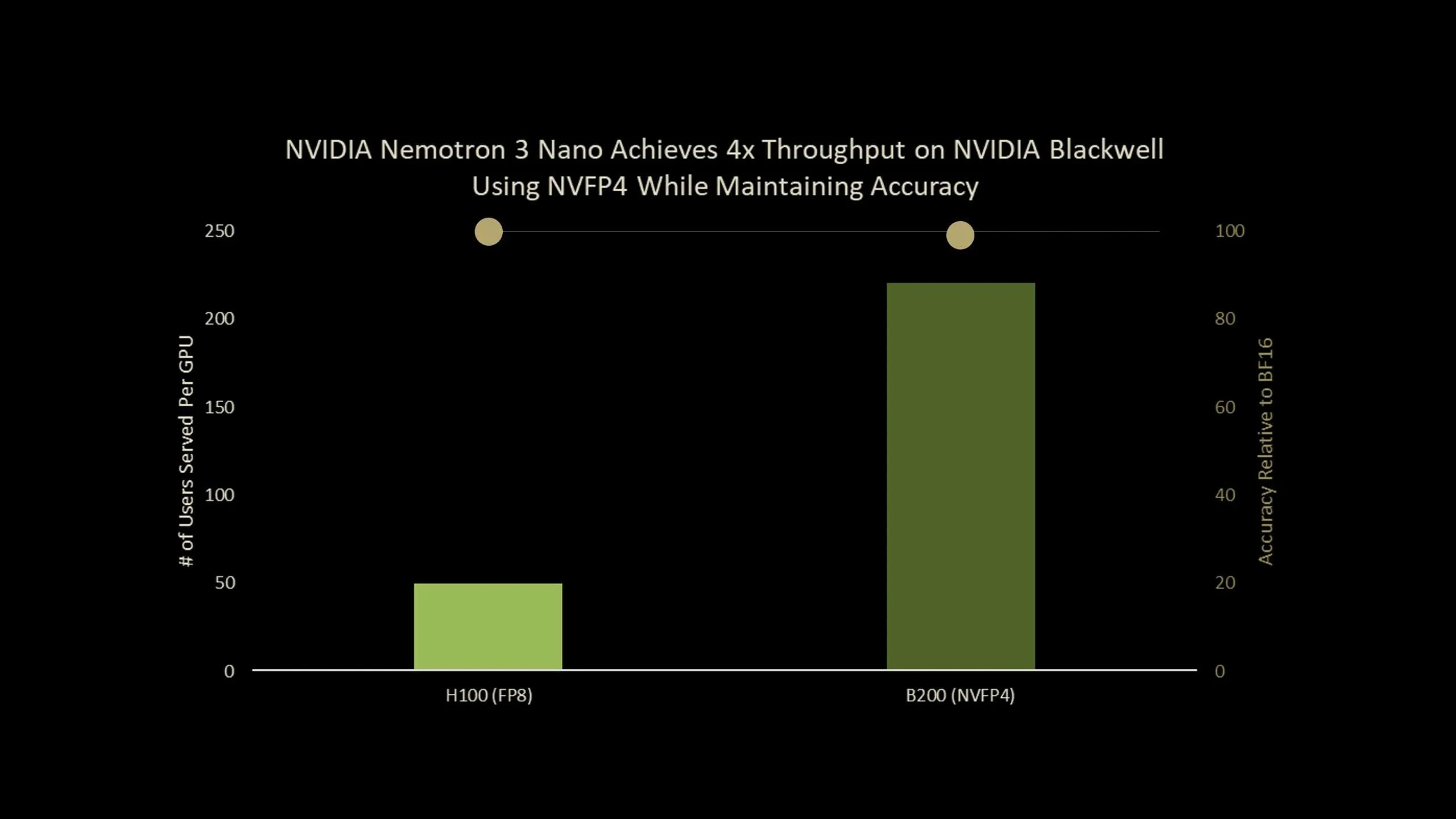
NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning InferenceMarkTechPost NVIDIA has released Nemotron-Nano-3-30B-A3B-NVFP4, a production checkpoint that runs a 30B parameter reasoning model in 4 bit NVFP4 format while keeping accuracy close to its BF16 baseline. The model combines a hybrid Mamba2 Transformer Mixture of Experts architecture with a Quantization Aware Distillation (QAD) recipe designed specifically for NVFP4 deployment. Overall, it is an ultra-efficient
The post NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning Inference appeared first on MarkTechPost.
NVIDIA has released Nemotron-Nano-3-30B-A3B-NVFP4, a production checkpoint that runs a 30B parameter reasoning model in 4 bit NVFP4 format while keeping accuracy close to its BF16 baseline. The model combines a hybrid Mamba2 Transformer Mixture of Experts architecture with a Quantization Aware Distillation (QAD) recipe designed specifically for NVFP4 deployment. Overall, it is an ultra-efficient
The post NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning Inference appeared first on MarkTechPost. Read More
“Existential risk” – Why scientists are racing to define consciousnessArtificial Intelligence News — ScienceDaily Scientists warn that rapid advances in AI and neurotechnology are outpacing our understanding of consciousness, creating serious ethical risks. New research argues that developing scientific tests for awareness could transform medicine, animal welfare, law, and AI development. But identifying consciousness in machines, brain organoids, or patients could also force society to rethink responsibility, rights, and moral boundaries. The question of what it means to be conscious has never been more urgent—or more unsettling.
Scientists warn that rapid advances in AI and neurotechnology are outpacing our understanding of consciousness, creating serious ethical risks. New research argues that developing scientific tests for awareness could transform medicine, animal welfare, law, and AI development. But identifying consciousness in machines, brain organoids, or patients could also force society to rethink responsibility, rights, and moral boundaries. The question of what it means to be conscious has never been more urgent—or more unsettling. Read More