
SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Prediction?cs.AI updates on arXiv.org arXiv:2602.00327v1 Announce Type: new
Abstract: We explore the use of large language models (LLMs) for next-utterance prediction in human dialogue. Despite recent advances in LLMs demonstrating their ability to engage in natural conversations with users, we show that even leading models surprisingly struggle to predict a human speaker’s next utterance. Instead, humans can readily anticipate forthcoming utterances based on multimodal cues, such as gestures, gaze, and emotional tone, from the context. To systematically examine whether LLMs can reproduce this ability, we propose SayNext-Bench, a benchmark that evaluates LLMs and Multimodal LLMs (MLLMs) on anticipating context-conditioned responses from multimodal cues spanning a variety of real-world scenarios. To support this benchmark, we build SayNext-PC, a novel large-scale dataset containing dialogues with rich multimodal cues. Building on this, we further develop a dual-route prediction MLLM, SayNext-Chat, that incorporates cognitively inspired design to emulate predictive processing in conversation. Experimental results demonstrate that our model outperforms state-of-the-art MLLMs in terms of lexical overlap, semantic similarity, and emotion consistency. Our results prove the feasibility of next-utterance prediction with LLMs from multimodal cues and emphasize the (i) indispensable role of multimodal cues and (ii) actively predictive processing as the foundation of natural human interaction, which is missing in current MLLMs. We hope that this exploration offers a new research entry toward more human-like, context-sensitive AI interaction for human-centered AI. Our benchmark and model can be accessed at https://saynext.github.io/.
arXiv:2602.00327v1 Announce Type: new
Abstract: We explore the use of large language models (LLMs) for next-utterance prediction in human dialogue. Despite recent advances in LLMs demonstrating their ability to engage in natural conversations with users, we show that even leading models surprisingly struggle to predict a human speaker’s next utterance. Instead, humans can readily anticipate forthcoming utterances based on multimodal cues, such as gestures, gaze, and emotional tone, from the context. To systematically examine whether LLMs can reproduce this ability, we propose SayNext-Bench, a benchmark that evaluates LLMs and Multimodal LLMs (MLLMs) on anticipating context-conditioned responses from multimodal cues spanning a variety of real-world scenarios. To support this benchmark, we build SayNext-PC, a novel large-scale dataset containing dialogues with rich multimodal cues. Building on this, we further develop a dual-route prediction MLLM, SayNext-Chat, that incorporates cognitively inspired design to emulate predictive processing in conversation. Experimental results demonstrate that our model outperforms state-of-the-art MLLMs in terms of lexical overlap, semantic similarity, and emotion consistency. Our results prove the feasibility of next-utterance prediction with LLMs from multimodal cues and emphasize the (i) indispensable role of multimodal cues and (ii) actively predictive processing as the foundation of natural human interaction, which is missing in current MLLMs. We hope that this exploration offers a new research entry toward more human-like, context-sensitive AI interaction for human-centered AI. Our benchmark and model can be accessed at https://saynext.github.io/. Read More
LLMs as High-Dimensional Nonlinear Autoregressive Models with Attention: Training, Alignment and Inferencecs.AI updates on arXiv.org arXiv:2602.00426v1 Announce Type: cross
Abstract: Large language models (LLMs) based on transformer architectures are typically described through collections of architectural components and training procedures, obscuring their underlying computational structure. This review article provides a concise mathematical reference for researchers seeking an explicit, equation-level description of LLM training, alignment, and generation. We formulate LLMs as high-dimensional nonlinear autoregressive models with attention-based dependencies. The framework encompasses pretraining via next-token prediction, alignment methods such as reinforcement learning from human feedback (RLHF), direct preference optimization (DPO), rejection sampling fine-tuning (RSFT), and reinforcement learning from verifiable rewards (RLVR), as well as autoregressive generation during inference. Self-attention emerges naturally as a repeated bilinear–softmax–linear composition, yielding highly expressive sequence models. This formulation enables principled analysis of alignment-induced behaviors (including sycophancy), inference-time phenomena (such as hallucination, in-context learning, chain-of-thought prompting, and retrieval-augmented generation), and extensions like continual learning, while serving as a concise reference for interpretation and further theoretical development.
arXiv:2602.00426v1 Announce Type: cross
Abstract: Large language models (LLMs) based on transformer architectures are typically described through collections of architectural components and training procedures, obscuring their underlying computational structure. This review article provides a concise mathematical reference for researchers seeking an explicit, equation-level description of LLM training, alignment, and generation. We formulate LLMs as high-dimensional nonlinear autoregressive models with attention-based dependencies. The framework encompasses pretraining via next-token prediction, alignment methods such as reinforcement learning from human feedback (RLHF), direct preference optimization (DPO), rejection sampling fine-tuning (RSFT), and reinforcement learning from verifiable rewards (RLVR), as well as autoregressive generation during inference. Self-attention emerges naturally as a repeated bilinear–softmax–linear composition, yielding highly expressive sequence models. This formulation enables principled analysis of alignment-induced behaviors (including sycophancy), inference-time phenomena (such as hallucination, in-context learning, chain-of-thought prompting, and retrieval-augmented generation), and extensions like continual learning, while serving as a concise reference for interpretation and further theoretical development. Read More
PPoGA: Predictive Plan-on-Graph with Action for Knowledge Graph Question Answeringcs.AI updates on arXiv.org arXiv:2602.00007v1 Announce Type: cross
Abstract: Large Language Models (LLMs) augmented with Knowledge Graphs (KGs) have advanced complex question answering, yet they often remain susceptible to failure when their initial high-level reasoning plan is flawed. This limitation, analogous to cognitive functional fixedness, prevents agents from restructuring their approach, leading them to pursue unworkable solutions. To address this, we propose PPoGA (Predictive Plan-on-Graph with Action), a novel KGQA framework inspired by human cognitive control and problem-solving. PPoGA incorporates a Planner-Executor architecture to separate high-level strategy from low-level execution and leverages a Predictive Processing mechanism to anticipate outcomes. The core innovation of our work is a self-correction mechanism that empowers the agent to perform not only Path Correction for local execution errors but also Plan Correction by identifying, discarding, and reformulating the entire plan when it proves ineffective. We conduct extensive experiments on three challenging multi-hop KGQA benchmarks: GrailQA, CWQ, and WebQSP. The results demonstrate that PPoGA achieves state-of-the-art performance, significantly outperforming existing methods. Our work highlights the critical importance of metacognitive abilities like problem restructuring for building more robust and flexible AI reasoning systems.
arXiv:2602.00007v1 Announce Type: cross
Abstract: Large Language Models (LLMs) augmented with Knowledge Graphs (KGs) have advanced complex question answering, yet they often remain susceptible to failure when their initial high-level reasoning plan is flawed. This limitation, analogous to cognitive functional fixedness, prevents agents from restructuring their approach, leading them to pursue unworkable solutions. To address this, we propose PPoGA (Predictive Plan-on-Graph with Action), a novel KGQA framework inspired by human cognitive control and problem-solving. PPoGA incorporates a Planner-Executor architecture to separate high-level strategy from low-level execution and leverages a Predictive Processing mechanism to anticipate outcomes. The core innovation of our work is a self-correction mechanism that empowers the agent to perform not only Path Correction for local execution errors but also Plan Correction by identifying, discarding, and reformulating the entire plan when it proves ineffective. We conduct extensive experiments on three challenging multi-hop KGQA benchmarks: GrailQA, CWQ, and WebQSP. The results demonstrate that PPoGA achieves state-of-the-art performance, significantly outperforming existing methods. Our work highlights the critical importance of metacognitive abilities like problem restructuring for building more robust and flexible AI reasoning systems. Read More
Artificial Intelligence and Symmetries: Learning, Encoding, and Discovering Structure in Physical Datacs.AI updates on arXiv.org arXiv:2602.02351v1 Announce Type: cross
Abstract: Symmetries play a central role in physics, organizing dynamics, constraining interactions, and determining the effective number of physical degrees of freedom. In parallel, modern artificial intelligence methods have demonstrated a remarkable ability to extract low-dimensional structure from high-dimensional data through representation learning. This review examines the interplay between these two perspectives, focusing on the extent to which symmetry-induced constraints can be identified, encoded, or diagnosed using machine learning techniques.
Rather than emphasizing architectures that enforce known symmetries by construction, we concentrate on data-driven approaches and latent representation learning, with particular attention to variational autoencoders. We discuss how symmetries and conservation laws reduce the intrinsic dimensionality of physical datasets, and how this reduction may manifest itself through self-organization of latent spaces in generative models trained to balance reconstruction and compression. We review recent results, including case studies from simple geometric systems and particle physics processes, and analyze the theoretical and practical limitations of inferring symmetry structure without explicit inductive bias.
arXiv:2602.02351v1 Announce Type: cross
Abstract: Symmetries play a central role in physics, organizing dynamics, constraining interactions, and determining the effective number of physical degrees of freedom. In parallel, modern artificial intelligence methods have demonstrated a remarkable ability to extract low-dimensional structure from high-dimensional data through representation learning. This review examines the interplay between these two perspectives, focusing on the extent to which symmetry-induced constraints can be identified, encoded, or diagnosed using machine learning techniques.
Rather than emphasizing architectures that enforce known symmetries by construction, we concentrate on data-driven approaches and latent representation learning, with particular attention to variational autoencoders. We discuss how symmetries and conservation laws reduce the intrinsic dimensionality of physical datasets, and how this reduction may manifest itself through self-organization of latent spaces in generative models trained to balance reconstruction and compression. We review recent results, including case studies from simple geometric systems and particle physics processes, and analyze the theoretical and practical limitations of inferring symmetry structure without explicit inductive bias. Read More
Real-Time Human Activity Recognition on Edge Microcontrollers: Dynamic Hierarchical Inference with Multi-Spectral Sensor Fusioncs.AI updates on arXiv.org arXiv:2602.00152v1 Announce Type: cross
Abstract: The demand for accurate on-device pattern recognition in edge applications is intensifying, yet existing approaches struggle to reconcile accuracy with computational constraints. To address this challenge, a resource-aware hierarchical network based on multi-spectral fusion and interpretable modules, namely the Hierarchical Parallel Pseudo-image Enhancement Fusion Network (HPPI-Net), is proposed for real-time, on-device Human Activity Recognition (HAR). Deployed on an ARM Cortex-M4 microcontroller for low-power real-time inference, HPPI-Net achieves 96.70% accuracy while utilizing only 22.3 KiB of RAM and 439.5 KiB of ROM after optimization. HPPI-Net employs a two-layer architecture. The first layer extracts preliminary features using Fast Fourier Transform (FFT) spectrograms, while the second layer selectively activates either a dedicated module for stationary activity recognition or a parallel LSTM-MobileNet network (PLMN) for dynamic states. PLMN fuses FFT, Wavelet, and Gabor spectrograms through three parallel LSTM encoders and refines the concatenated features using Efficient Channel Attention (ECA) and Depthwise Separable Convolution (DSC), thereby offering channel-level interpretability while substantially reducing multiply-accumulate operations. Compared with MobileNetV3, HPPI-Net improves accuracy by 1.22% and reduces RAM usage by 71.2% and ROM usage by 42.1%. These results demonstrate that HPPI-Net achieves a favorable accuracy-efficiency trade-off and provides explainable predictions, establishing a practical solution for wearable, industrial, and smart home HAR on memory-constrained edge platforms.
arXiv:2602.00152v1 Announce Type: cross
Abstract: The demand for accurate on-device pattern recognition in edge applications is intensifying, yet existing approaches struggle to reconcile accuracy with computational constraints. To address this challenge, a resource-aware hierarchical network based on multi-spectral fusion and interpretable modules, namely the Hierarchical Parallel Pseudo-image Enhancement Fusion Network (HPPI-Net), is proposed for real-time, on-device Human Activity Recognition (HAR). Deployed on an ARM Cortex-M4 microcontroller for low-power real-time inference, HPPI-Net achieves 96.70% accuracy while utilizing only 22.3 KiB of RAM and 439.5 KiB of ROM after optimization. HPPI-Net employs a two-layer architecture. The first layer extracts preliminary features using Fast Fourier Transform (FFT) spectrograms, while the second layer selectively activates either a dedicated module for stationary activity recognition or a parallel LSTM-MobileNet network (PLMN) for dynamic states. PLMN fuses FFT, Wavelet, and Gabor spectrograms through three parallel LSTM encoders and refines the concatenated features using Efficient Channel Attention (ECA) and Depthwise Separable Convolution (DSC), thereby offering channel-level interpretability while substantially reducing multiply-accumulate operations. Compared with MobileNetV3, HPPI-Net improves accuracy by 1.22% and reduces RAM usage by 71.2% and ROM usage by 42.1%. These results demonstrate that HPPI-Net achieves a favorable accuracy-efficiency trade-off and provides explainable predictions, establishing a practical solution for wearable, industrial, and smart home HAR on memory-constrained edge platforms. Read More
Synthetic Student Responses: LLM-Extracted Features for IRT Difficulty Parameter Estimationcs.AI updates on arXiv.org arXiv:2602.00034v1 Announce Type: cross
Abstract: Educational assessment relies heavily on knowing question difficulty, traditionally determined through resource-intensive pre-testing with students. This creates significant barriers for both classroom teachers and assessment developers. We investigate whether Item Response Theory (IRT) difficulty parameters can be accurately estimated without student testing by modeling the response process and explore the relative contribution of different feature types to prediction accuracy. Our approach combines traditional linguistic features with pedagogical insights extracted using Large Language Models (LLMs), including solution step count, cognitive complexity, and potential misconceptions. We implement a two-stage process: first training a neural network to predict how students would respond to questions, then deriving difficulty parameters from these simulated response patterns. Using a dataset of over 250,000 student responses to mathematics questions, our model achieves a Pearson correlation of approximately 0.78 between predicted and actual difficulty parameters on completely unseen questions.
arXiv:2602.00034v1 Announce Type: cross
Abstract: Educational assessment relies heavily on knowing question difficulty, traditionally determined through resource-intensive pre-testing with students. This creates significant barriers for both classroom teachers and assessment developers. We investigate whether Item Response Theory (IRT) difficulty parameters can be accurately estimated without student testing by modeling the response process and explore the relative contribution of different feature types to prediction accuracy. Our approach combines traditional linguistic features with pedagogical insights extracted using Large Language Models (LLMs), including solution step count, cognitive complexity, and potential misconceptions. We implement a two-stage process: first training a neural network to predict how students would respond to questions, then deriving difficulty parameters from these simulated response patterns. Using a dataset of over 250,000 student responses to mathematics questions, our model achieves a Pearson correlation of approximately 0.78 between predicted and actual difficulty parameters on completely unseen questions. Read More
EigenAI: Deterministic Inference, Verifiable Resultscs.AI updates on arXiv.org arXiv:2602.00182v1 Announce Type: cross
Abstract: EigenAI is a verifiable AI platform built on top of the EigenLayer restaking ecosystem. At a high level, it combines a deterministic large-language model (LLM) inference engine with a cryptoeconomically secured optimistic re-execution protocol so that every inference result can be publicly audited, reproduced, and, if necessary, economically enforced. An untrusted operator runs inference on a fixed GPU architecture, signs and encrypts the request and response, and publishes the encrypted log to EigenDA. During a challenge window, any watcher may request re-execution through EigenVerify; the result is then deterministically recomputed inside a trusted execution environment (TEE) with a threshold-released decryption key, allowing a public challenge with private data. Because inference itself is bit-exact, verification reduces to a byte-equality check, and a single honest replica suffices to detect fraud. We show how this architecture yields sovereign agents — prediction-market judges, trading bots, and scientific assistants — that enjoy state-of-the-art performance while inheriting security from Ethereum’s validator base.
arXiv:2602.00182v1 Announce Type: cross
Abstract: EigenAI is a verifiable AI platform built on top of the EigenLayer restaking ecosystem. At a high level, it combines a deterministic large-language model (LLM) inference engine with a cryptoeconomically secured optimistic re-execution protocol so that every inference result can be publicly audited, reproduced, and, if necessary, economically enforced. An untrusted operator runs inference on a fixed GPU architecture, signs and encrypts the request and response, and publishes the encrypted log to EigenDA. During a challenge window, any watcher may request re-execution through EigenVerify; the result is then deterministically recomputed inside a trusted execution environment (TEE) with a threshold-released decryption key, allowing a public challenge with private data. Because inference itself is bit-exact, verification reduces to a byte-equality check, and a single honest replica suffices to detect fraud. We show how this architecture yields sovereign agents — prediction-market judges, trading bots, and scientific assistants — that enjoy state-of-the-art performance while inheriting security from Ethereum’s validator base. Read More

Working with Billion-Row Datasets in Python (Using Vaex)KDnuggets Analyze billion-row datasets in Python using Vaex. Learn how out-of-core processing, lazy evaluation, and memory mapping enable fast analytics at scale.
Analyze billion-row datasets in Python using Vaex. Learn how out-of-core processing, lazy evaluation, and memory mapping enable fast analytics at scale. Read More
Building Systems That Survive Real LifeTowards Data Science Sara Nobrega on the transition from data science to AI engineering, using LLMs as a bridge to DevOps, and the one engineering skill junior data scientists need to stay competitive.
The post Building Systems That Survive Real Life appeared first on Towards Data Science.
Sara Nobrega on the transition from data science to AI engineering, using LLMs as a bridge to DevOps, and the one engineering skill junior data scientists need to stay competitive.
The post Building Systems That Survive Real Life appeared first on Towards Data Science. Read More
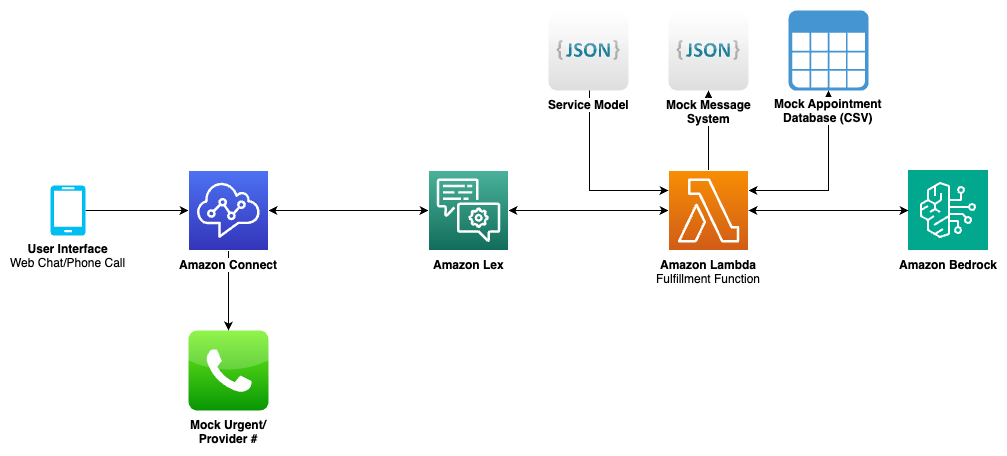
How Clarus Care uses Amazon Bedrock to deliver conversational contact center interactionsArtificial Intelligence In this post, we illustrate how Clarus Care, a healthcare contact center solutions provider, worked with the AWS Generative AI Innovation Center (GenAIIC) team to develop a generative AI-powered contact center prototype. This solution enables conversational interaction and multi-intent resolution through an automated voicebot and chat interface. It also incorporates a scalable service model to support growth, human transfer capabilities–when requested or for urgent cases–and an analytics pipeline for performance insights.
In this post, we illustrate how Clarus Care, a healthcare contact center solutions provider, worked with the AWS Generative AI Innovation Center (GenAIIC) team to develop a generative AI-powered contact center prototype. This solution enables conversational interaction and multi-intent resolution through an automated voicebot and chat interface. It also incorporates a scalable service model to support growth, human transfer capabilities–when requested or for urgent cases–and an analytics pipeline for performance insights. Read More