
Tech Stack for Vibe Coding Modern ApplicationsKDnuggets Stop fighting AI. Use a tech stack AI understands and can build a paid SaaS within minutes.
Stop fighting AI. Use a tech stack AI understands and can build a paid SaaS within minutes. Read More

Mechanistic Interpretability: Peeking Inside an LLMTowards Data Science Are the human-like cognitive abilities of LLMs real or fake? How does information travel through the neural network? Is there hidden knowledge inside an LLM?
The post Mechanistic Interpretability: Peeking Inside an LLM appeared first on Towards Data Science.
Are the human-like cognitive abilities of LLMs real or fake? How does information travel through the neural network? Is there hidden knowledge inside an LLM?
The post Mechanistic Interpretability: Peeking Inside an LLM appeared first on Towards Data Science. Read More
Why Is My Code So Slow? A Guide to Py-Spy Python ProfilingTowards Data Science Stop guessing and start diagnosing performance issues using Py-Spy
The post Why Is My Code So Slow? A Guide to Py-Spy Python Profiling appeared first on Towards Data Science.
Stop guessing and start diagnosing performance issues using Py-Spy
The post Why Is My Code So Slow? A Guide to Py-Spy Python Profiling appeared first on Towards Data Science. Read More
AWS vs. Azure: A Deep Dive into Model Training – Part 2Towards Data Science This article covers how Azure ML’s persistent, workspace-centric compute resources differ from AWS SageMaker’s on-demand, job-specific approach. Additionally, we explored environment customization options, from Azure’s curated environments and custom environments to SageMaker’s three level of customizations.
The post AWS vs. Azure: A Deep Dive into Model Training – Part 2 appeared first on Towards Data Science.
This article covers how Azure ML’s persistent, workspace-centric compute resources differ from AWS SageMaker’s on-demand, job-specific approach. Additionally, we explored environment customization options, from Azure’s curated environments and custom environments to SageMaker’s three level of customizations.
The post AWS vs. Azure: A Deep Dive into Model Training – Part 2 appeared first on Towards Data Science. Read More
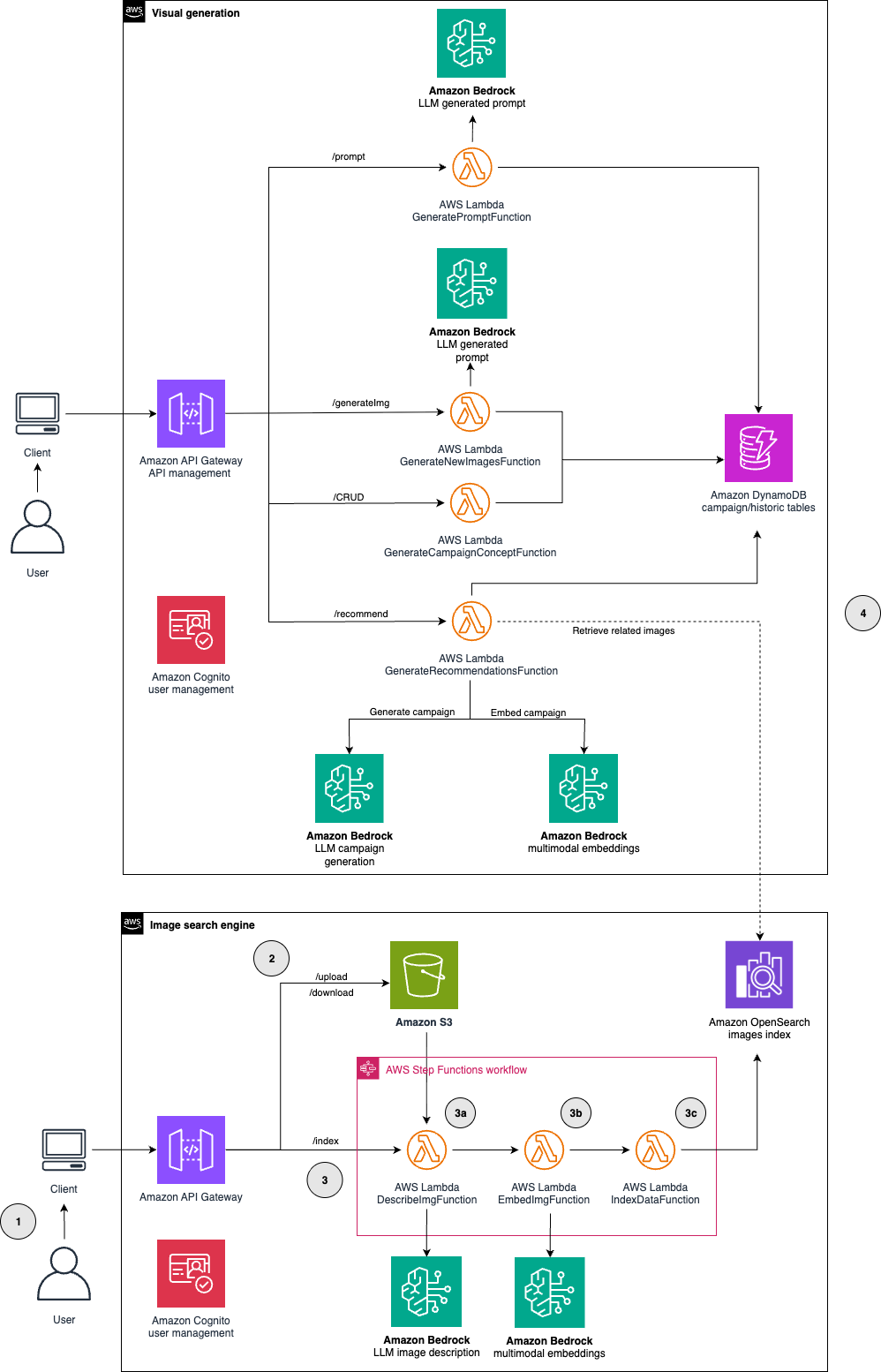
Accelerating your marketing ideation with generative AI – Part 2: Generate custom marketing images from historical referencesArtificial Intelligence Building upon our earlier work of marketing campaign image generation using Amazon Nova foundation models, in this post, we demonstrate how to enhance image generation by learning from previous marketing campaigns. We explore how to integrate Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create an advanced image generation system that uses reference campaigns to maintain brand guidelines, deliver consistent content, and enhance the effectiveness and efficiency of new campaign creation.
Building upon our earlier work of marketing campaign image generation using Amazon Nova foundation models, in this post, we demonstrate how to enhance image generation by learning from previous marketing campaigns. We explore how to integrate Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create an advanced image generation system that uses reference campaigns to maintain brand guidelines, deliver consistent content, and enhance the effectiveness and efficiency of new campaign creation. Read More
How to Work Effectively with Frontend and Backend CodeTowards Data Science Learn how to be an effective full-stack engineer with Claude Code
The post How to Work Effectively with Frontend and Backend Code appeared first on Towards Data Science.
Learn how to be an effective full-stack engineer with Claude Code
The post How to Work Effectively with Frontend and Backend Code appeared first on Towards Data Science. Read More
Rank-and-Reason: Multi-Agent Collaboration Accelerates Zero-Shot Protein Mutation Predictioncs.AI updates on arXiv.org arXiv:2602.00197v2 Announce Type: cross
Abstract: Zero-shot mutation prediction is vital for low-resource protein engineering, yet existing protein language models (PLMs) often yield statistically confident results that ignore fundamental biophysical constraints. Currently, selecting candidates for wet-lab validation relies on manual expert auditing of PLM outputs, a process that is inefficient, subjective, and highly dependent on domain expertise. To address this, we propose Rank-and-Reason (VenusRAR), a two-stage agentic framework to automate this workflow and maximize expected wet-lab fitness. In the Rank-Stage, a Computational Expert and Virtual Biologist aggregate a context-aware multi-modal ensemble, establishing a new Spearman correlation record of 0.551 (vs. 0.518) on ProteinGym. In the Reason-Stage, an agentic Expert Panel employs chain-of-thought reasoning to audit candidates against geometric and structural constraints, improving the Top-5 Hit Rate by up to 367% on ProteinGym-DMS99. The wet-lab validation on Cas12i3 nuclease further confirms the framework’s efficacy, achieving a 46.7% positive rate and identifying two novel mutants with 4.23-fold and 5.05-fold activity improvements. Code and datasets are released on GitHub (https://github.com/ai4protein/VenusRAR/).
arXiv:2602.00197v2 Announce Type: cross
Abstract: Zero-shot mutation prediction is vital for low-resource protein engineering, yet existing protein language models (PLMs) often yield statistically confident results that ignore fundamental biophysical constraints. Currently, selecting candidates for wet-lab validation relies on manual expert auditing of PLM outputs, a process that is inefficient, subjective, and highly dependent on domain expertise. To address this, we propose Rank-and-Reason (VenusRAR), a two-stage agentic framework to automate this workflow and maximize expected wet-lab fitness. In the Rank-Stage, a Computational Expert and Virtual Biologist aggregate a context-aware multi-modal ensemble, establishing a new Spearman correlation record of 0.551 (vs. 0.518) on ProteinGym. In the Reason-Stage, an agentic Expert Panel employs chain-of-thought reasoning to audit candidates against geometric and structural constraints, improving the Top-5 Hit Rate by up to 367% on ProteinGym-DMS99. The wet-lab validation on Cas12i3 nuclease further confirms the framework’s efficacy, achieving a 46.7% positive rate and identifying two novel mutants with 4.23-fold and 5.05-fold activity improvements. Code and datasets are released on GitHub (https://github.com/ai4protein/VenusRAR/). Read More
How to Become an AI Engineer in 2026: A Self-Study RoadmapKDnuggets Want to become an AI engineer in 2026? This step-by-step roadmap breaks down the skills, tools, and projects you need.
Want to become an AI engineer in 2026? This step-by-step roadmap breaks down the skills, tools, and projects you need. Read More

AI Expo 2026 Day 1: Governance and data readiness enable the agentic enterpriseAI News While the prospect of AI acting as a digital co-worker dominated the day one agenda at the co-located AI & Big Data Expo and Intelligent Automation Conference, the technical sessions focused on the infrastructure to make it work. A primary topic on the exhibition floor was the progression from passive automation to “agentic” systems. These
The post AI Expo 2026 Day 1: Governance and data readiness enable the agentic enterprise appeared first on AI News.
While the prospect of AI acting as a digital co-worker dominated the day one agenda at the co-located AI & Big Data Expo and Intelligent Automation Conference, the technical sessions focused on the infrastructure to make it work. A primary topic on the exhibition floor was the progression from passive automation to “agentic” systems. These
The post AI Expo 2026 Day 1: Governance and data readiness enable the agentic enterprise appeared first on AI News. Read More
Navigating health questions with ChatGPTOpenAI News A family shares how ChatGPT helped them prepare for critical cancer treatment decisions for their son alongside expert guidance from his doctors.
A family shares how ChatGPT helped them prepare for critical cancer treatment decisions for their son alongside expert guidance from his doctors. Read More