
Cryptocurrency markets a testbed for AI forecasting modelsAI News Cryptocurrency markets have become a high-speed playground where developers optimise the next generation of predictive software. Using real-time data flows and decentralised platforms, scientists develop prediction models that can extend the scope of traditional finance. The digital asset landscape offers an unparalleled environment for machine learning. When you track cryptocurrency prices today, you are observing
The post Cryptocurrency markets a testbed for AI forecasting models appeared first on AI News.
Cryptocurrency markets have become a high-speed playground where developers optimise the next generation of predictive software. Using real-time data flows and decentralised platforms, scientists develop prediction models that can extend the scope of traditional finance. The digital asset landscape offers an unparalleled environment for machine learning. When you track cryptocurrency prices today, you are observing
The post Cryptocurrency markets a testbed for AI forecasting models appeared first on AI News. Read More
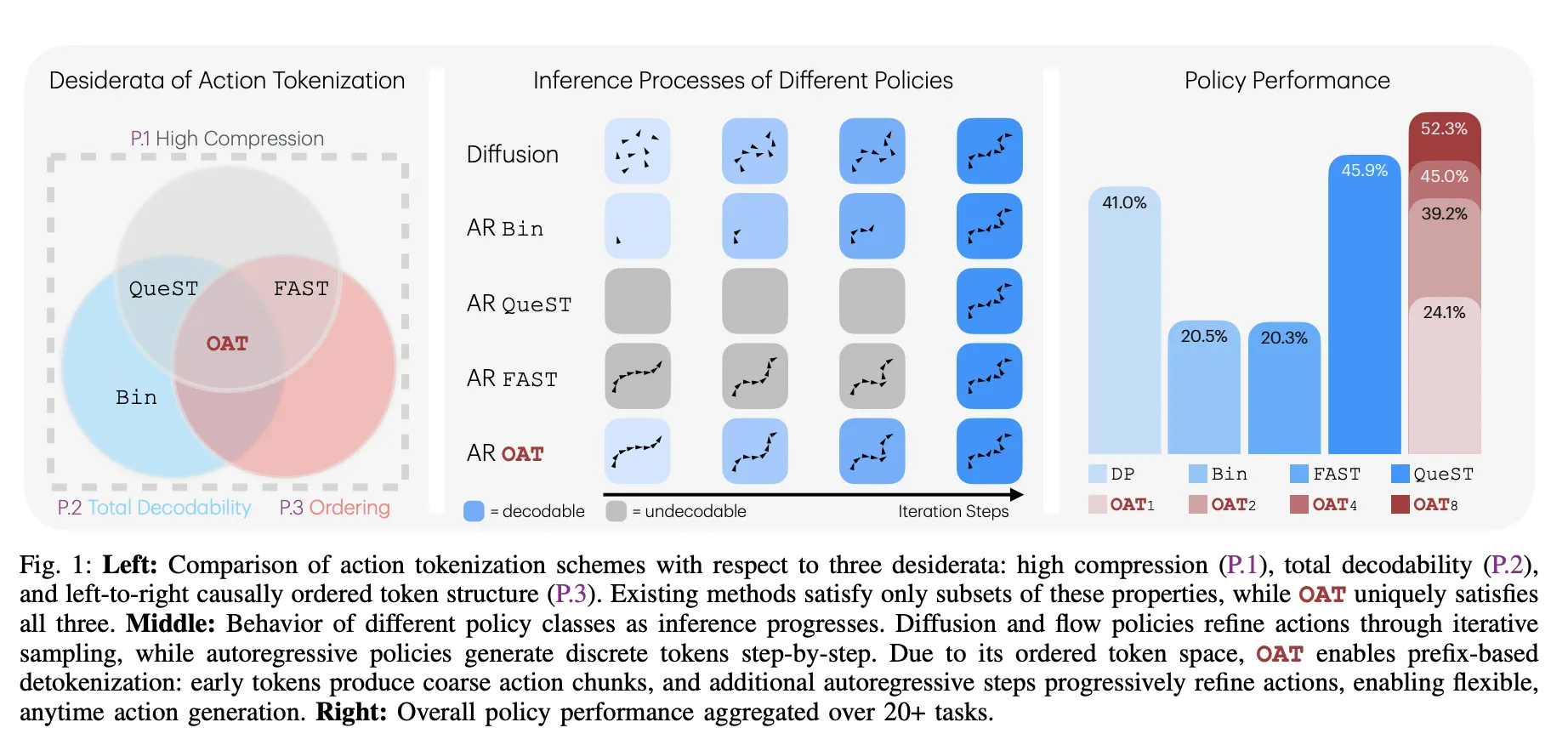
Meet OAT: The New Action Tokenizer Bringing LLM-Style Scaling and Flexible, Anytime Inference to the Robotics WorldMarkTechPost Robots are entering their GPT-3 era. For years, researchers have tried to train robots using the same autoregressive (AR) models that power large language models (LLMs). If a model can predict the next word in a sentence, it should be able to predict the next move for a robotic arm. However, a technical wall has
The post Meet OAT: The New Action Tokenizer Bringing LLM-Style Scaling and Flexible, Anytime Inference to the Robotics World appeared first on MarkTechPost.
Robots are entering their GPT-3 era. For years, researchers have tried to train robots using the same autoregressive (AR) models that power large language models (LLMs). If a model can predict the next word in a sentence, it should be able to predict the next move for a robotic arm. However, a technical wall has
The post Meet OAT: The New Action Tokenizer Bringing LLM-Style Scaling and Flexible, Anytime Inference to the Robotics World appeared first on MarkTechPost. Read More
Bridging 6G IoT and AI: LLM-Based Efficient Approach for Physical Layer’s Optimization Taskscs.AI updates on arXiv.org arXiv:2602.06819v1 Announce Type: cross
Abstract: This paper investigates the role of large language models (LLMs) in sixth-generation (6G) Internet of Things (IoT) networks and proposes a prompt-engineering-based real-time feedback and verification (PE-RTFV) framework that perform physical-layer’s optimization tasks through an iteratively process. By leveraging the naturally available closed-loop feedback inherent in wireless communication systems, PE-RTFV enables real-time physical-layer optimization without requiring model retraining. The proposed framework employs an optimization LLM (O-LLM) to generate task-specific structured prompts, which are provided to an agent LLM (A-LLM) to produce task-specific solutions. Utilizing real-time system feedback, the O-LLM iteratively refines the prompts to guide the A-LLM toward improved solutions in a gradient-descent-like optimization process. We test PE-RTFV approach on wireless-powered IoT testbed case study on user-goal-driven constellation design through semantically solving rate-energy (RE)-region optimization problem which demonstrates that PE-RTFV achieves near-genetic-algorithm performance within only a few iterations, validating its effectiveness for complex physical-layer optimization tasks in resource-constrained IoT networks.
arXiv:2602.06819v1 Announce Type: cross
Abstract: This paper investigates the role of large language models (LLMs) in sixth-generation (6G) Internet of Things (IoT) networks and proposes a prompt-engineering-based real-time feedback and verification (PE-RTFV) framework that perform physical-layer’s optimization tasks through an iteratively process. By leveraging the naturally available closed-loop feedback inherent in wireless communication systems, PE-RTFV enables real-time physical-layer optimization without requiring model retraining. The proposed framework employs an optimization LLM (O-LLM) to generate task-specific structured prompts, which are provided to an agent LLM (A-LLM) to produce task-specific solutions. Utilizing real-time system feedback, the O-LLM iteratively refines the prompts to guide the A-LLM toward improved solutions in a gradient-descent-like optimization process. We test PE-RTFV approach on wireless-powered IoT testbed case study on user-goal-driven constellation design through semantically solving rate-energy (RE)-region optimization problem which demonstrates that PE-RTFV achieves near-genetic-algorithm performance within only a few iterations, validating its effectiveness for complex physical-layer optimization tasks in resource-constrained IoT networks. Read More
Optimal Abstractions for Verifying Properties of Kolmogorov-Arnold Networks (KANs)cs.AI updates on arXiv.org arXiv:2602.06737v1 Announce Type: cross
Abstract: We present a novel approach for verifying properties of Kolmogorov-Arnold Networks (KANs), a class of neural networks characterized by nonlinear, univariate activation functions typically implemented as piecewise polynomial splines or Gaussian processes. Our method creates mathematical “abstractions” by replacing each KAN unit with a piecewise affine (PWA) function, providing both local and global error estimates between the original network and its approximation. These abstractions enable property verification by encoding the problem as a Mixed Integer Linear Program (MILP), determining whether outputs satisfy specified properties when inputs belong to a given set. A critical challenge lies in balancing the number of pieces in the PWA approximation: too many pieces add binary variables that make verification computationally intractable, while too few pieces create excessive error margins that yield uninformative bounds. Our key contribution is a systematic framework that exploits KAN structure to find optimal abstractions. By combining dynamic programming at the unit level with a knapsack optimization across the network, we minimize the total number of pieces while guaranteeing specified error bounds. This approach determines the optimal approximation strategy for each unit while maintaining overall accuracy requirements. Empirical evaluation across multiple KAN benchmarks demonstrates that the upfront analysis costs of our method are justified by superior verification results.
arXiv:2602.06737v1 Announce Type: cross
Abstract: We present a novel approach for verifying properties of Kolmogorov-Arnold Networks (KANs), a class of neural networks characterized by nonlinear, univariate activation functions typically implemented as piecewise polynomial splines or Gaussian processes. Our method creates mathematical “abstractions” by replacing each KAN unit with a piecewise affine (PWA) function, providing both local and global error estimates between the original network and its approximation. These abstractions enable property verification by encoding the problem as a Mixed Integer Linear Program (MILP), determining whether outputs satisfy specified properties when inputs belong to a given set. A critical challenge lies in balancing the number of pieces in the PWA approximation: too many pieces add binary variables that make verification computationally intractable, while too few pieces create excessive error margins that yield uninformative bounds. Our key contribution is a systematic framework that exploits KAN structure to find optimal abstractions. By combining dynamic programming at the unit level with a knapsack optimization across the network, we minimize the total number of pieces while guaranteeing specified error bounds. This approach determines the optimal approximation strategy for each unit while maintaining overall accuracy requirements. Empirical evaluation across multiple KAN benchmarks demonstrates that the upfront analysis costs of our method are justified by superior verification results. Read More
RAPID: Reconfigurable, Adaptive Platform for Iterative Designcs.AI updates on arXiv.org arXiv:2602.06653v1 Announce Type: cross
Abstract: Developing robotic manipulation policies is iterative and hypothesis-driven: researchers test tactile sensing, gripper geometries, and sensor placements through real-world data collection and training. Yet even minor end-effector changes often require mechanical refitting and system re-integration, slowing iteration. We present RAPID, a full-stack reconfigurable platform designed to reduce this friction. RAPID is built around a tool-free, modular hardware architecture that unifies handheld data collection and robot deployment, and a matching software stack that maintains real-time awareness of the underlying hardware configuration through a driver-level Physical Mask derived from USB events. This modular hardware architecture reduces reconfiguration to seconds and makes systematic multi-modal ablation studies practical, allowing researchers to sweep diverse gripper and sensing configurations without repeated system bring-up. The Physical Mask exposes modality presence as an explicit runtime signal, enabling auto-configuration and graceful degradation under sensor hot-plug events, so policies can continue executing when sensors are physically added or removed. System-centric experiments show that RAPID reduces the setup time for multi-modal configurations by two orders of magnitude compared to traditional workflows and preserves policy execution under runtime sensor hot-unplug events. The hardware designs, drivers, and software stack are open-sourced at https://rapid-kit.github.io/ .
arXiv:2602.06653v1 Announce Type: cross
Abstract: Developing robotic manipulation policies is iterative and hypothesis-driven: researchers test tactile sensing, gripper geometries, and sensor placements through real-world data collection and training. Yet even minor end-effector changes often require mechanical refitting and system re-integration, slowing iteration. We present RAPID, a full-stack reconfigurable platform designed to reduce this friction. RAPID is built around a tool-free, modular hardware architecture that unifies handheld data collection and robot deployment, and a matching software stack that maintains real-time awareness of the underlying hardware configuration through a driver-level Physical Mask derived from USB events. This modular hardware architecture reduces reconfiguration to seconds and makes systematic multi-modal ablation studies practical, allowing researchers to sweep diverse gripper and sensing configurations without repeated system bring-up. The Physical Mask exposes modality presence as an explicit runtime signal, enabling auto-configuration and graceful degradation under sensor hot-plug events, so policies can continue executing when sensors are physically added or removed. System-centric experiments show that RAPID reduces the setup time for multi-modal configurations by two orders of magnitude compared to traditional workflows and preserves policy execution under runtime sensor hot-unplug events. The hardware designs, drivers, and software stack are open-sourced at https://rapid-kit.github.io/ . Read More
Which Graph Shift Operator? A Spectral Answer to an Empirical Questioncs.AI updates on arXiv.org arXiv:2602.06557v1 Announce Type: cross
Abstract: Graph Neural Networks (GNNs) have established themselves as the leading models for learning on graph-structured data, generally categorized into spatial and spectral approaches. Central to these architectures is the Graph Shift Operator (GSO), a matrix representation of the graph structure used to filter node signals. However, selecting the optimal GSO, whether fixed or learnable, remains largely empirical. In this paper, we introduce a novel alignment gain metric that quantifies the geometric distortion between the input signal and label subspaces. Crucially, our theoretical analysis connects this alignment directly to generalization bounds via a spectral proxy for the Lipschitz constant. This yields a principled, computation-efficient criterion to rank and select the optimal GSO for any prediction task prior to training, eliminating the need for extensive search.
arXiv:2602.06557v1 Announce Type: cross
Abstract: Graph Neural Networks (GNNs) have established themselves as the leading models for learning on graph-structured data, generally categorized into spatial and spectral approaches. Central to these architectures is the Graph Shift Operator (GSO), a matrix representation of the graph structure used to filter node signals. However, selecting the optimal GSO, whether fixed or learnable, remains largely empirical. In this paper, we introduce a novel alignment gain metric that quantifies the geometric distortion between the input signal and label subspaces. Crucially, our theoretical analysis connects this alignment directly to generalization bounds via a spectral proxy for the Lipschitz constant. This yields a principled, computation-efficient criterion to rank and select the optimal GSO for any prediction task prior to training, eliminating the need for extensive search. Read More
Revisiting the Shape Convention of Transformer Language Modelscs.AI updates on arXiv.org arXiv:2602.06471v1 Announce Type: cross
Abstract: Dense Transformer language models have largely adhered to one consistent architectural shape: each layer consists of an attention module followed by a feed-forward network (FFN) with a narrow-wide-narrow MLP, allocating most parameters to the MLP at expansion ratios between 2 and 4. Motivated by recent results that residual wide-narrow-wide (hourglass) MLPs offer superior function approximation capabilities, we revisit the long-standing MLP shape convention in Transformer, challenging the necessity of the narrow-wide-narrow design. To study this, we develop a Transformer variant that replaces the conventional FFN with a deeper hourglass-shaped FFN, comprising a stack of hourglass sub-MLPs connected by residual pathways. We posit that a deeper but lighter hourglass FFN can serve as a competitive alternative to the conventional FFN, and that parameters saved by using a lighter hourglass FFN can be more effectively utilized, such as by enlarging model hidden dimensions under fixed budgets. We confirm these through empirical validations across model scales: hourglass FFNs outperform conventional FFNs up to 400M and achieve comparable performance at larger scales to 1B parameters; hourglass FFN variants with reduced FFN and increased attention parameters show consistent improvements over conventional configurations at matched budgets. Together, these findings shed new light on recent work and prompt a rethinking of the narrow-wide-narrow MLP convention and the balance between attention and FFN towards efficient and expressive modern language models.
arXiv:2602.06471v1 Announce Type: cross
Abstract: Dense Transformer language models have largely adhered to one consistent architectural shape: each layer consists of an attention module followed by a feed-forward network (FFN) with a narrow-wide-narrow MLP, allocating most parameters to the MLP at expansion ratios between 2 and 4. Motivated by recent results that residual wide-narrow-wide (hourglass) MLPs offer superior function approximation capabilities, we revisit the long-standing MLP shape convention in Transformer, challenging the necessity of the narrow-wide-narrow design. To study this, we develop a Transformer variant that replaces the conventional FFN with a deeper hourglass-shaped FFN, comprising a stack of hourglass sub-MLPs connected by residual pathways. We posit that a deeper but lighter hourglass FFN can serve as a competitive alternative to the conventional FFN, and that parameters saved by using a lighter hourglass FFN can be more effectively utilized, such as by enlarging model hidden dimensions under fixed budgets. We confirm these through empirical validations across model scales: hourglass FFNs outperform conventional FFNs up to 400M and achieve comparable performance at larger scales to 1B parameters; hourglass FFN variants with reduced FFN and increased attention parameters show consistent improvements over conventional configurations at matched budgets. Together, these findings shed new light on recent work and prompt a rethinking of the narrow-wide-narrow MLP convention and the balance between attention and FFN towards efficient and expressive modern language models. Read More
Efficient Perplexity Bound and Ratio Matching in Discrete Diffusion Language Modelscs.AI updates on arXiv.org arXiv:2507.04341v2 Announce Type: replace-cross
Abstract: While continuous diffusion models excel in modeling continuous distributions, their application to categorical data has been less effective. Recent work has shown that ratio-matching through score-entropy within a continuous-time discrete Markov chain (CTMC) framework serves as a competitive alternative to autoregressive models in language modeling. To enhance this framework, we first introduce three new theorems concerning the KL divergence between the data and learned distribution. Our results serve as the discrete counterpart to those established for continuous diffusion models and allow us to derive an improved upper bound of the perplexity. Second, we empirically show that ratio-matching performed by minimizing the denoising cross-entropy between the clean and corrupted data enables models to outperform those utilizing score-entropy with up to 10% lower perplexity/generative-perplexity, and 15% faster training steps. To further support our findings, we introduce and evaluate a novel CTMC transition-rate matrix that allows prediction refinement, and derive the analytic expression for its matrix exponential which facilitates the computation of conditional ratios thus enabling efficient training and generation.
arXiv:2507.04341v2 Announce Type: replace-cross
Abstract: While continuous diffusion models excel in modeling continuous distributions, their application to categorical data has been less effective. Recent work has shown that ratio-matching through score-entropy within a continuous-time discrete Markov chain (CTMC) framework serves as a competitive alternative to autoregressive models in language modeling. To enhance this framework, we first introduce three new theorems concerning the KL divergence between the data and learned distribution. Our results serve as the discrete counterpart to those established for continuous diffusion models and allow us to derive an improved upper bound of the perplexity. Second, we empirically show that ratio-matching performed by minimizing the denoising cross-entropy between the clean and corrupted data enables models to outperform those utilizing score-entropy with up to 10% lower perplexity/generative-perplexity, and 15% faster training steps. To further support our findings, we introduce and evaluate a novel CTMC transition-rate matrix that allows prediction refinement, and derive the analytic expression for its matrix exponential which facilitates the computation of conditional ratios thus enabling efficient training and generation. Read More
Unlocking Noisy Real-World Corpora for Foundation Model Pre-Training via Quality-Aware Tokenizationcs.AI updates on arXiv.org arXiv:2602.06394v1 Announce Type: new
Abstract: Current tokenization methods process sequential data without accounting for signal quality, limiting their effectiveness on noisy real-world corpora. We present QA-Token (Quality-Aware Tokenization), which incorporates data reliability directly into vocabulary construction. We make three key contributions: (i) a bilevel optimization formulation that jointly optimizes vocabulary construction and downstream performance, (ii) a reinforcement learning approach that learns merge policies through quality-aware rewards with convergence guarantees, and (iii) an adaptive parameter learning mechanism via Gumbel-Softmax relaxation for end-to-end optimization. Our experimental evaluation demonstrates consistent improvements: genomics (6.7 percentage point F1 gain in variant calling over BPE), finance (30% Sharpe ratio improvement). At foundation scale, we tokenize a pretraining corpus comprising 1.7 trillion base-pairs and achieve state-of-the-art pathogen detection (94.53 MCC) while reducing token count by 15%. We unlock noisy real-world corpora, spanning petabases of genomic sequences and terabytes of financial time series, for foundation model training with zero inference overhead.
arXiv:2602.06394v1 Announce Type: new
Abstract: Current tokenization methods process sequential data without accounting for signal quality, limiting their effectiveness on noisy real-world corpora. We present QA-Token (Quality-Aware Tokenization), which incorporates data reliability directly into vocabulary construction. We make three key contributions: (i) a bilevel optimization formulation that jointly optimizes vocabulary construction and downstream performance, (ii) a reinforcement learning approach that learns merge policies through quality-aware rewards with convergence guarantees, and (iii) an adaptive parameter learning mechanism via Gumbel-Softmax relaxation for end-to-end optimization. Our experimental evaluation demonstrates consistent improvements: genomics (6.7 percentage point F1 gain in variant calling over BPE), finance (30% Sharpe ratio improvement). At foundation scale, we tokenize a pretraining corpus comprising 1.7 trillion base-pairs and achieve state-of-the-art pathogen detection (94.53 MCC) while reducing token count by 15%. We unlock noisy real-world corpora, spanning petabases of genomic sequences and terabytes of financial time series, for foundation model training with zero inference overhead. Read More
Malicious Agent Skills in the Wild: A Large-Scale Security Empirical Studycs.AI updates on arXiv.org arXiv:2602.06547v1 Announce Type: cross
Abstract: Third-party agent skills extend LLM-based agents with instruction files and executable code that run on users’ machines. Skills execute with user privileges and are distributed through community registries with minimal vetting, but no ground-truth dataset exists to characterize the resulting threats. We construct the first labeled dataset of malicious agent skills by behaviorally verifying 98,380 skills from two community registries, confirming 157 malicious skills with 632 vulnerabilities. These attacks are not incidental. Malicious skills average 4.03 vulnerabilities across a median of three kill chain phases, and the ecosystem has split into two archetypes: Data Thieves that exfiltrate credentials through supply chain techniques, and Agent Hijackers that subvert agent decision-making through instruction manipulation. A single actor accounts for 54.1% of confirmed cases through templated brand impersonation. Shadow features, capabilities absent from public documentation, appear in 0% of basic attacks but 100% of advanced ones; several skills go further by exploiting the AI platform’s own hook system and permission flags. Responsible disclosure led to 93.6% removal within 30 days. We release the dataset and analysis pipeline to support future work on agent skill security.
arXiv:2602.06547v1 Announce Type: cross
Abstract: Third-party agent skills extend LLM-based agents with instruction files and executable code that run on users’ machines. Skills execute with user privileges and are distributed through community registries with minimal vetting, but no ground-truth dataset exists to characterize the resulting threats. We construct the first labeled dataset of malicious agent skills by behaviorally verifying 98,380 skills from two community registries, confirming 157 malicious skills with 632 vulnerabilities. These attacks are not incidental. Malicious skills average 4.03 vulnerabilities across a median of three kill chain phases, and the ecosystem has split into two archetypes: Data Thieves that exfiltrate credentials through supply chain techniques, and Agent Hijackers that subvert agent decision-making through instruction manipulation. A single actor accounts for 54.1% of confirmed cases through templated brand impersonation. Shadow features, capabilities absent from public documentation, appear in 0% of basic attacks but 100% of advanced ones; several skills go further by exploiting the AI platform’s own hook system and permission flags. Responsible disclosure led to 93.6% removal within 30 days. We release the dataset and analysis pipeline to support future work on agent skill security. Read More