
Pandas vs. Polars: A Complete Comparison of Syntax, Speed, and MemoryKDnuggets Need help choosing the right Python dataframe library? This article compares Pandas and Polars to help you decide.
Need help choosing the right Python dataframe library? This article compares Pandas and Polars to help you decide. Read More
10 GitHub Repositories to Master System DesignKDnuggets Want to move beyond drawing boxes and arrows and actually understand how scalable systems are built? These GitHub repositories break down the concepts, patterns, and real-world trade-offs that make great system design possible.
Want to move beyond drawing boxes and arrows and actually understand how scalable systems are built? These GitHub repositories break down the concepts, patterns, and real-world trade-offs that make great system design possible. Read More

How Human Work Will Remain Valuable in an AI WorldTowards Data Science The Road to Reality — Episode 1
The post How Human Work Will Remain Valuable in an AI World appeared first on Towards Data Science.
The Road to Reality — Episode 1
The post How Human Work Will Remain Valuable in an AI World appeared first on Towards Data Science. Read More

OpenAI Releases Symphony: An Open Source Agentic Framework for Orchestrating Autonomous AI Agents through Structured, Scalable Implementation RunsMarkTechPost OpenAI has released Symphony, an open-source framework designed to manage autonomous AI coding agents through structured ‘implementation runs.’ The project provides a system for automating software development tasks by connecting issue trackers to LLM-based agents. System Architecture: Elixir and the BEAM Symphony is built using Elixir and the Erlang/BEAM runtime. The choice of stack focuses
The post OpenAI Releases Symphony: An Open Source Agentic Framework for Orchestrating Autonomous AI Agents through Structured, Scalable Implementation Runs appeared first on MarkTechPost.
OpenAI has released Symphony, an open-source framework designed to manage autonomous AI coding agents through structured ‘implementation runs.’ The project provides a system for automating software development tasks by connecting issue trackers to LLM-based agents. System Architecture: Elixir and the BEAM Symphony is built using Elixir and the Erlang/BEAM runtime. The choice of stack focuses
The post OpenAI Releases Symphony: An Open Source Agentic Framework for Orchestrating Autonomous AI Agents through Structured, Scalable Implementation Runs appeared first on MarkTechPost. Read More
How to Design an Advanced Tree-of-Thoughts Multi-Branch Reasoning Agent with Beam Search, Heuristic Scoring, and Depth-Limited PruningMarkTechPost In this tutorial, we build an advanced Tree-of-Thoughts (ToT) multi-branch reasoning agent from scratch. Instead of relying on linear chain-of-thought reasoning, we design a system that generates multiple reasoning branches, scores each branch using a heuristic evaluation function, prunes weak candidates, and continues expanding only the strongest paths. We combine an instruction-tuned transformer model with
The post How to Design an Advanced Tree-of-Thoughts Multi-Branch Reasoning Agent with Beam Search, Heuristic Scoring, and Depth-Limited Pruning appeared first on MarkTechPost.
In this tutorial, we build an advanced Tree-of-Thoughts (ToT) multi-branch reasoning agent from scratch. Instead of relying on linear chain-of-thought reasoning, we design a system that generates multiple reasoning branches, scores each branch using a heuristic evaluation function, prunes weak candidates, and continues expanding only the strongest paths. We combine an instruction-tuned transformer model with
The post How to Design an Advanced Tree-of-Thoughts Multi-Branch Reasoning Agent with Beam Search, Heuristic Scoring, and Depth-Limited Pruning appeared first on MarkTechPost. Read More
AI in Multiple GPUs: ZeRO & FSDPTowards Data Science Learn how Zero Redundancy Optimizer works, how to implement it from scratch, and how to use it in PyTorch
The post AI in Multiple GPUs: ZeRO & FSDP appeared first on Towards Data Science.
Learn how Zero Redundancy Optimizer works, how to implement it from scratch, and how to use it in PyTorch
The post AI in Multiple GPUs: ZeRO & FSDP appeared first on Towards Data Science. Read More
Reasoning models struggle to control their chains of thought, and that’s goodOpenAI News OpenAI introduces CoT-Control and finds reasoning models struggle to control their chains of thought, reinforcing monitorability as an AI safety safeguard.
OpenAI introduces CoT-Control and finds reasoning models struggle to control their chains of thought, reinforcing monitorability as an AI safety safeguard. Read More
JPMorgan expands AI investment as tech spending nears $20BAI News Artificial intelligence is moving from pilot projects to core business systems inside large companies. One example comes from JPMorgan Chase, where rising AI investment is helping push the bank’s technology budget toward about US$19.8 billion in 2026. The spending plan reflects a broader shift among large enterprises. AI is no longer treated as a small
The post JPMorgan expands AI investment as tech spending nears $20B appeared first on AI News.
Artificial intelligence is moving from pilot projects to core business systems inside large companies. One example comes from JPMorgan Chase, where rising AI investment is helping push the bank’s technology budget toward about US$19.8 billion in 2026. The spending plan reflects a broader shift among large enterprises. AI is no longer treated as a small
The post JPMorgan expands AI investment as tech spending nears $20B appeared first on AI News. Read More
Introducing GPT-5.4OpenAI News Introducing GPT-5.4, OpenAI’s most most capable and efficient frontier model for professional work, with state-of-the-art coding, computer use, tool search, and 1M-token context.
Introducing GPT-5.4, OpenAI’s most most capable and efficient frontier model for professional work, with state-of-the-art coding, computer use, tool search, and 1M-token context. Read More
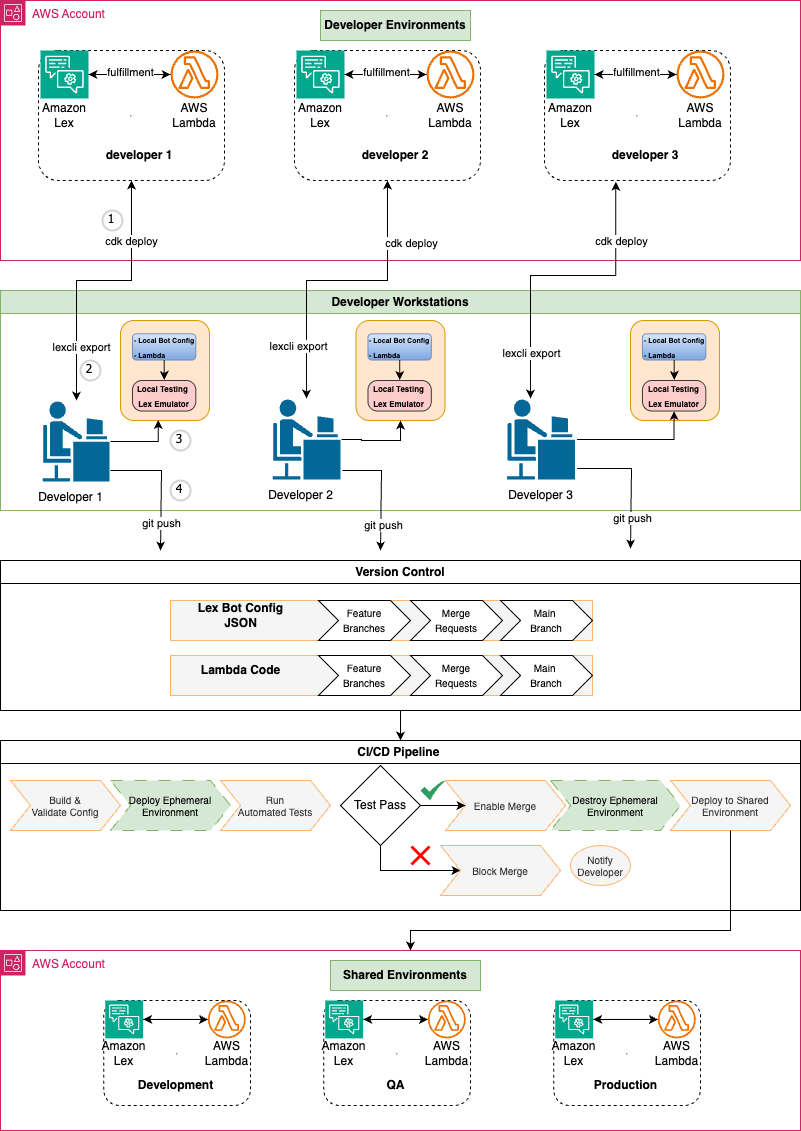
Drive organizational growth with Amazon Lex multi-developer CI/CD pipelineArtificial Intelligence In this post, we walk through a multi-developer CI/CD pipeline for Amazon Lex that enables isolated development environments, automated testing, and streamlined deployments. We show you how to set up the solution and share real-world results from teams using this approach.
In this post, we walk through a multi-developer CI/CD pipeline for Amazon Lex that enables isolated development environments, automated testing, and streamlined deployments. We show you how to set up the solution and share real-world results from teams using this approach. Read More