
Meta Context Engineering via Agentic Skill Evolutioncs.AI updates on arXiv.org arXiv:2601.21557v2 Announce Type: replace
Abstract: The operational efficacy of large language models relies heavily on their inference-time context. This has established Context Engineering (CE) as a formal discipline for optimizing these inputs. Current CE methods rely on manually crafted harnesses, such as rigid generation-reflection workflows and predefined context schemas. They impose structural biases and restrict context optimization to a narrow, intuition-bound design space. To address this, we introduce Meta Context Engineering (MCE), a bi-level framework that supersedes static CE heuristics by co-evolving CE skills and context artifacts. In MCE iterations, a meta-level agent refines engineering skills via agentic crossover, a deliberative search over the history of skills, their executions, and evaluations. A base-level agent executes these skills, learns from training rollouts, and optimizes context as flexible files and code. We evaluate MCE across five disparate domains under offline and online settings. MCE demonstrates consistent performance gains, achieving 5.6–53.8% relative improvement over state-of-the-art agentic CE methods (mean of 16.9%), while maintaining superior context adaptability, transferability, and efficiency in both context usage and training.
arXiv:2601.21557v2 Announce Type: replace
Abstract: The operational efficacy of large language models relies heavily on their inference-time context. This has established Context Engineering (CE) as a formal discipline for optimizing these inputs. Current CE methods rely on manually crafted harnesses, such as rigid generation-reflection workflows and predefined context schemas. They impose structural biases and restrict context optimization to a narrow, intuition-bound design space. To address this, we introduce Meta Context Engineering (MCE), a bi-level framework that supersedes static CE heuristics by co-evolving CE skills and context artifacts. In MCE iterations, a meta-level agent refines engineering skills via agentic crossover, a deliberative search over the history of skills, their executions, and evaluations. A base-level agent executes these skills, learns from training rollouts, and optimizes context as flexible files and code. We evaluate MCE across five disparate domains under offline and online settings. MCE demonstrates consistent performance gains, achieving 5.6–53.8% relative improvement over state-of-the-art agentic CE methods (mean of 16.9%), while maintaining superior context adaptability, transferability, and efficiency in both context usage and training. Read More
Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shufflecs.AI updates on arXiv.org arXiv:2508.05612v4 Announce Type: replace-cross
Abstract: Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM.
arXiv:2508.05612v4 Announce Type: replace-cross
Abstract: Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM. Read More
Structured Sentiment Analysis as Transition-based Dependency Graph Parsingcs.AI updates on arXiv.org arXiv:2305.05311v2 Announce Type: replace-cross
Abstract: Structured sentiment analysis (SSA) aims to automatically extract people’s opinions from a text in natural language and adequately represent that information in a graph structure. One of the most accurate methods for performing SSA was recently proposed and consists of approaching it as a dependency graph parsing task. Although we can find in the literature how transition-based algorithms excel in different dependency graph parsing tasks in terms of accuracy and efficiency, all proposed attempts to tackle SSA following that approach were based on graph-based models. In this article, we present the first transition-based method to address SSA as dependency graph parsing. Specifically, we design a transition system that processes the input text in a left-to-right pass, incrementally generating the graph structure containing all identified opinions. To effectively implement our final transition-based model, we resort to a Pointer Network architecture as a backbone. From an extensive evaluation, we demonstrate that our model offers the best performance to date in practically all cases among prior dependency-based methods, and surpasses recent task-specific techniques on the most challenging datasets. We additionally include an in-depth analysis and empirically prove that the average-case time complexity of our approach is quadratic in the sentence length, being more efficient than top-performing graph-based parsers.
arXiv:2305.05311v2 Announce Type: replace-cross
Abstract: Structured sentiment analysis (SSA) aims to automatically extract people’s opinions from a text in natural language and adequately represent that information in a graph structure. One of the most accurate methods for performing SSA was recently proposed and consists of approaching it as a dependency graph parsing task. Although we can find in the literature how transition-based algorithms excel in different dependency graph parsing tasks in terms of accuracy and efficiency, all proposed attempts to tackle SSA following that approach were based on graph-based models. In this article, we present the first transition-based method to address SSA as dependency graph parsing. Specifically, we design a transition system that processes the input text in a left-to-right pass, incrementally generating the graph structure containing all identified opinions. To effectively implement our final transition-based model, we resort to a Pointer Network architecture as a backbone. From an extensive evaluation, we demonstrate that our model offers the best performance to date in practically all cases among prior dependency-based methods, and surpasses recent task-specific techniques on the most challenging datasets. We additionally include an in-depth analysis and empirically prove that the average-case time complexity of our approach is quadratic in the sentence length, being more efficient than top-performing graph-based parsers. Read More
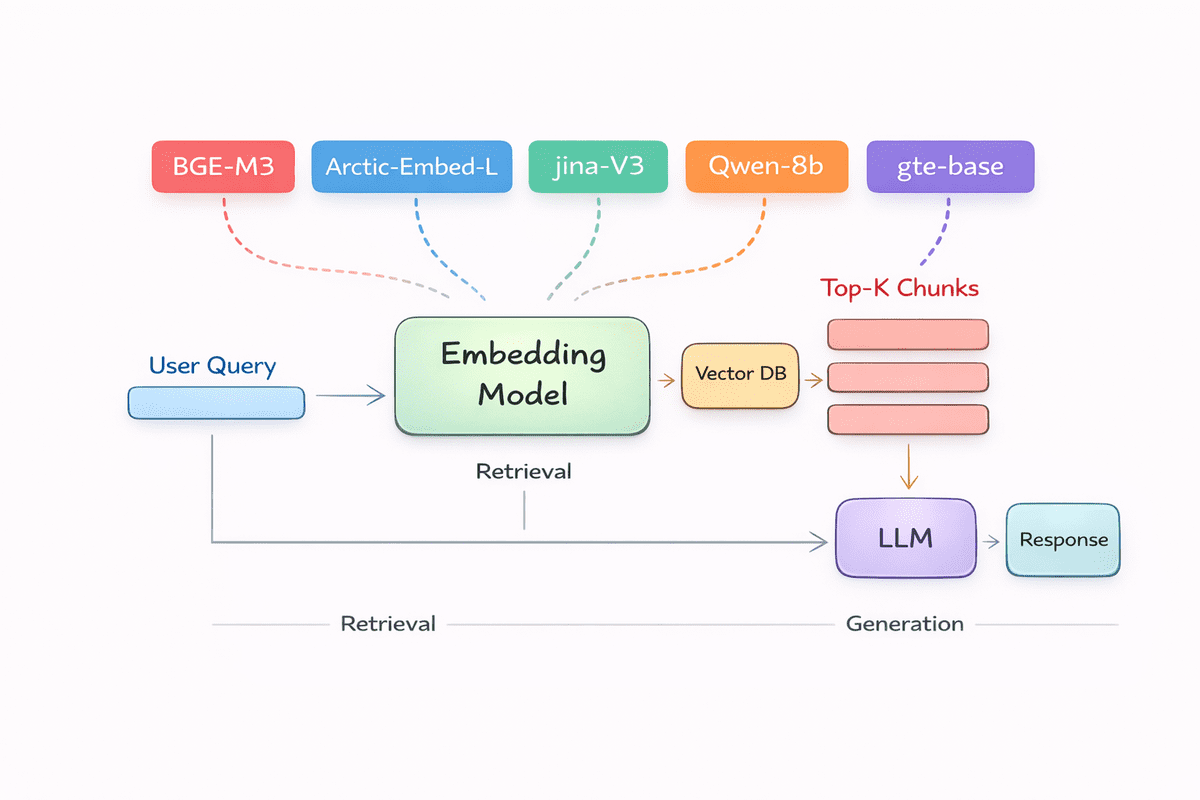
Top 5 Embedding Models for Your RAG PipelineKDnuggets Natural Language Processing
Natural Language Processing Read More
AI in Multiple GPUs: Understanding the Host and Device ParadigmTowards Data Science Learn how CPU and GPUs interact in the host-device paradigm
The post AI in Multiple GPUs: Understanding the Host and Device Paradigm appeared first on Towards Data Science.
Learn how CPU and GPUs interact in the host-device paradigm
The post AI in Multiple GPUs: Understanding the Host and Device Paradigm appeared first on Towards Data Science. Read More

State-sponsored hackers exploit AI for advanced cyberattacksAI News State-sponsored hackers are exploiting AI to accelerate cyberattacks, with threat actors from Iran, North Korea, China, and Russia weaponising models like Google’s Gemini to craft sophisticated phishing campaigns and develop malware, according to a new report from Google’s Threat Intelligence Group (GTIG). The quarterly AI Threat Tracker report, released today, reveals how government-backed attackers have
The post State-sponsored hackers exploit AI for advanced cyberattacks appeared first on AI News.
State-sponsored hackers are exploiting AI to accelerate cyberattacks, with threat actors from Iran, North Korea, China, and Russia weaponising models like Google’s Gemini to craft sophisticated phishing campaigns and develop malware, according to a new report from Google’s Threat Intelligence Group (GTIG). The quarterly AI Threat Tracker report, released today, reveals how government-backed attackers have
The post State-sponsored hackers exploit AI for advanced cyberattacks appeared first on AI News. Read More
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transformscs.AI updates on arXiv.org arXiv:2509.09679v3 Announce Type: replace-cross
Abstract: Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $mathbf{y} = mathbf{Wx} = (mathbf{WQ}^T)(mathbf{Qx})$ for orthogonal $mathbf{Q}$. However, these methods use fixed transforms–Hadamard matrices achieving optimal worst-case coherence $mu = 1/sqrt{n}$–that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. In this work, we propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard’s discrete ${+1, -1}$ entries that are non-differentiable and thus prohibit gradient-based learning, butterfly transforms’ continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n log n)$ computational complexity with only $frac{n log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU.
arXiv:2509.09679v3 Announce Type: replace-cross
Abstract: Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $mathbf{y} = mathbf{Wx} = (mathbf{WQ}^T)(mathbf{Qx})$ for orthogonal $mathbf{Q}$. However, these methods use fixed transforms–Hadamard matrices achieving optimal worst-case coherence $mu = 1/sqrt{n}$–that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. In this work, we propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard’s discrete ${+1, -1}$ entries that are non-differentiable and thus prohibit gradient-based learning, butterfly transforms’ continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n log n)$ computational complexity with only $frac{n log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU. Read More
ZebraPose: Zebra Detection and Pose Estimation using only Synthetic Datacs.AI updates on arXiv.org arXiv:2408.10831v2 Announce Type: replace-cross
Abstract: Collecting and labeling large real-world wild animal datasets is impractical, costly, error-prone, and labor-intensive. For animal monitoring tasks, as detection, tracking, and pose estimation, out-of-distribution viewpoints (e.g. aerial) are also typically needed but rarely found in publicly available datasets. To solve this, existing approaches synthesize data with simplistic techniques that then necessitate strategies to bridge the synthetic-to-real gap. Therefore, real images, style constraints, complex animal models, or pre-trained networks are often leveraged. In contrast, we generate a fully synthetic dataset using a 3D photorealistic simulator and demonstrate that it can eliminate such needs for detecting and estimating 2D poses of wild zebras. Moreover, existing top-down 2D pose estimation approaches using synthetic data assume reliable detection models. However, these often fail in out-of-distribution scenarios, e.g. those that include wildlife or aerial imagery. Our method overcomes this by enabling the training of both tasks using the same synthetic dataset. Through extensive benchmarks, we show that models trained from scratch exclusively on our synthetic data generalize well to real images. We perform these using multiple real-world and synthetic datasets, pre-trained and randomly initialized backbones, and different image resolutions. Code, results, models, and data can be found athttps://zebrapose.is.tue.mpg.de/.
arXiv:2408.10831v2 Announce Type: replace-cross
Abstract: Collecting and labeling large real-world wild animal datasets is impractical, costly, error-prone, and labor-intensive. For animal monitoring tasks, as detection, tracking, and pose estimation, out-of-distribution viewpoints (e.g. aerial) are also typically needed but rarely found in publicly available datasets. To solve this, existing approaches synthesize data with simplistic techniques that then necessitate strategies to bridge the synthetic-to-real gap. Therefore, real images, style constraints, complex animal models, or pre-trained networks are often leveraged. In contrast, we generate a fully synthetic dataset using a 3D photorealistic simulator and demonstrate that it can eliminate such needs for detecting and estimating 2D poses of wild zebras. Moreover, existing top-down 2D pose estimation approaches using synthetic data assume reliable detection models. However, these often fail in out-of-distribution scenarios, e.g. those that include wildlife or aerial imagery. Our method overcomes this by enabling the training of both tasks using the same synthetic dataset. Through extensive benchmarks, we show that models trained from scratch exclusively on our synthetic data generalize well to real images. We perform these using multiple real-world and synthetic datasets, pre-trained and randomly initialized backbones, and different image resolutions. Code, results, models, and data can be found athttps://zebrapose.is.tue.mpg.de/. Read More
Intrinsic Self-Correction in LLMs: Towards Explainable Prompting via Mechanistic Interpretabilitycs.AI updates on arXiv.org arXiv:2505.11924v3 Announce Type: replace-cross
Abstract: Intrinsic self-correction refers to the phenomenon where a language model refines its own outputs purely through prompting, without external feedback or parameter updates. While this approach improves performance across diverse tasks, its mechanism remains unclear. We show that intrinsic self-correction functions by steering hidden representations along interpretable latent directions, as evidenced by both alignment analysis and activation interventions. To achieve this, we analyze intrinsic self-correction via the representation shift induced by prompting. In parallel, we construct interpretable latent directions with contrastive pairs and verify the causal effect of these directions via activation addition. Evaluating six open-source LLMs, our results demonstrate that prompt-induced representation shifts in text detoxification and text toxification consistently align with latent directions constructed from contrastive pairs. In detoxification, the shifts align with the non-toxic direction; in toxification, they align with the toxic direction. These findings suggest that representation steering is the mechanistic driver of intrinsic self-correction. Our analysis highlights that understanding model internals offers a direct route to analyzing the mechanisms of prompt-driven LLM behaviors.
arXiv:2505.11924v3 Announce Type: replace-cross
Abstract: Intrinsic self-correction refers to the phenomenon where a language model refines its own outputs purely through prompting, without external feedback or parameter updates. While this approach improves performance across diverse tasks, its mechanism remains unclear. We show that intrinsic self-correction functions by steering hidden representations along interpretable latent directions, as evidenced by both alignment analysis and activation interventions. To achieve this, we analyze intrinsic self-correction via the representation shift induced by prompting. In parallel, we construct interpretable latent directions with contrastive pairs and verify the causal effect of these directions via activation addition. Evaluating six open-source LLMs, our results demonstrate that prompt-induced representation shifts in text detoxification and text toxification consistently align with latent directions constructed from contrastive pairs. In detoxification, the shifts align with the non-toxic direction; in toxification, they align with the toxic direction. These findings suggest that representation steering is the mechanistic driver of intrinsic self-correction. Our analysis highlights that understanding model internals offers a direct route to analyzing the mechanisms of prompt-driven LLM behaviors. Read More
AI Driven Discovery of Bio Ecological Mediation in Cascading Heatwave Riskscs.AI updates on arXiv.org arXiv:2509.25112v2 Announce Type: replace
Abstract: Compound heatwaves increasingly trigger complex cascading failures that propagate through interconnected physical and human systems, yet the fragmentation of disciplinary knowledge hinders the comprehensive mapping of these systemic risk topologies. This study introduces the Heatwave Discovery Agent HeDA as an autonomous scientific synthesis framework designed to bridge cognitive gaps by constructing a high fidelity knowledge graph from 8,111 academic publications. By structuring 70,297 evidence nodes, the system exhibits enhanced inferential fidelity in capturing long tail risk mechanisms and achieves a significant accuracy margin compared to standard foundation models including GPT 5.2 and Claude Sonnet 4.5 in complex reasoning tasks. The resulting topological analysis reveals a critical bio ecological mediation effect where biological systems function as the primary non linear amplifiers of thermal stress that transform physical meteorological hazards into systemic socioeconomic losses. We further identify latent functional couplings between theoretically distinct sectors such as the heat induced synchronization of power grid failures and emergency medical capacity saturation. These findings elucidate the dynamics of compound climate risks and provide an empirical basis for shifting adaptation strategies from static sectoral defense to dynamic cross system resilience.
arXiv:2509.25112v2 Announce Type: replace
Abstract: Compound heatwaves increasingly trigger complex cascading failures that propagate through interconnected physical and human systems, yet the fragmentation of disciplinary knowledge hinders the comprehensive mapping of these systemic risk topologies. This study introduces the Heatwave Discovery Agent HeDA as an autonomous scientific synthesis framework designed to bridge cognitive gaps by constructing a high fidelity knowledge graph from 8,111 academic publications. By structuring 70,297 evidence nodes, the system exhibits enhanced inferential fidelity in capturing long tail risk mechanisms and achieves a significant accuracy margin compared to standard foundation models including GPT 5.2 and Claude Sonnet 4.5 in complex reasoning tasks. The resulting topological analysis reveals a critical bio ecological mediation effect where biological systems function as the primary non linear amplifiers of thermal stress that transform physical meteorological hazards into systemic socioeconomic losses. We further identify latent functional couplings between theoretically distinct sectors such as the heat induced synchronization of power grid failures and emergency medical capacity saturation. These findings elucidate the dynamics of compound climate risks and provide an empirical basis for shifting adaptation strategies from static sectoral defense to dynamic cross system resilience. Read More