
Overcoming Nonsmoothness and Control Chattering in Nonconvex Optimal Control ProblemsTowards Data Science With some hints for good numerics
The post Overcoming Nonsmoothness and Control Chattering in Nonconvex Optimal Control Problems appeared first on Towards Data Science.
With some hints for good numerics
The post Overcoming Nonsmoothness and Control Chattering in Nonconvex Optimal Control Problems appeared first on Towards Data Science. Read More
How to Build a Robust Multi-Agent Pipeline Using CAMEL with Planning, Web-Augmented Reasoning, Critique, and Persistent MemoryMarkTechPost In this tutorial, we build an advanced, end-to-end multi-agent research workflow using the CAMEL framework. We design a coordinated society of agents, Planner, Researcher, Writer, Critic, and Finalizer, that collaboratively transform a high-level topic into a polished, evidence-grounded research brief. We securely integrate the OpenAI API, orchestrate agent interactions programmatically, and add lightweight persistent memory
The post How to Build a Robust Multi-Agent Pipeline Using CAMEL with Planning, Web-Augmented Reasoning, Critique, and Persistent Memory appeared first on MarkTechPost.
In this tutorial, we build an advanced, end-to-end multi-agent research workflow using the CAMEL framework. We design a coordinated society of agents, Planner, Researcher, Writer, Critic, and Finalizer, that collaboratively transform a high-level topic into a polished, evidence-grounded research brief. We securely integrate the OpenAI API, orchestrate agent interactions programmatically, and add lightweight persistent memory
The post How to Build a Robust Multi-Agent Pipeline Using CAMEL with Planning, Web-Augmented Reasoning, Critique, and Persistent Memory appeared first on MarkTechPost. Read More
The Machine Learning “Advent Calendar” Bonus 1: AUC in ExcelTowards Data Science AUC measures how well a model ranks positives above negatives, independent of any chosen threshold.
The post The Machine Learning “Advent Calendar” Bonus 1: AUC in Excel appeared first on Towards Data Science.
AUC measures how well a model ranks positives above negatives, independent of any chosen threshold.
The post The Machine Learning “Advent Calendar” Bonus 1: AUC in Excel appeared first on Towards Data Science. Read More

7 High Paying Side Hustles for StudentsKDnuggets Make extra money between classes with beginner-friendly freelance platforms that fit your lifestyle.
Make extra money between classes with beginner-friendly freelance platforms that fit your lifestyle. Read More
Agents Under the Curve (AUC)Towards Data Science Towards understanding if your agentic solution is actually better
The post Agents Under the Curve (AUC) appeared first on Towards Data Science.
Towards understanding if your agentic solution is actually better
The post Agents Under the Curve (AUC) appeared first on Towards Data Science. Read More
Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each QueryMarkTechPost LLMRouter is an open source routing library from the U Lab at the University of Illinois Urbana Champaign that treats model selection as a first class system problem. It sits between applications and a pool of LLMs and chooses a model for each query based on task complexity, quality targets, and cost, all exposed through
The post Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each Query appeared first on MarkTechPost.
LLMRouter is an open source routing library from the U Lab at the University of Illinois Urbana Champaign that treats model selection as a first class system problem. It sits between applications and a pool of LLMs and chooses a model for each query based on task complexity, quality targets, and cost, all exposed through
The post Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each Query appeared first on MarkTechPost. Read More
DynaMix: Generalizable Person Re-identification via Dynamic Relabeling and Mixed Data Samplingcs.AI updates on arXiv.org arXiv:2511.19067v2 Announce Type: replace-cross
Abstract: Generalizable person re-identification (Re-ID) aims to recognize individuals across unseen cameras and environments. While existing methods rely heavily on limited labeled multi-camera data, we propose DynaMix, a novel method that effectively combines manually labeled multi-camera and large-scale pseudo-labeled single-camera data. Unlike prior works, DynaMix dynamically adapts to the structure and noise of the training data through three core components: (1) a Relabeling Module that refines pseudo-labels of single-camera identities on-the-fly; (2) an Efficient Centroids Module that maintains robust identity representations under a large identity space; and (3) a Data Sampling Module that carefully composes mixed data mini-batches to balance learning complexity and intra-batch diversity. All components are specifically designed to operate efficiently at scale, enabling effective training on millions of images and hundreds of thousands of identities. Extensive experiments demonstrate that DynaMix consistently outperforms state-of-the-art methods in generalizable person Re-ID.
arXiv:2511.19067v2 Announce Type: replace-cross
Abstract: Generalizable person re-identification (Re-ID) aims to recognize individuals across unseen cameras and environments. While existing methods rely heavily on limited labeled multi-camera data, we propose DynaMix, a novel method that effectively combines manually labeled multi-camera and large-scale pseudo-labeled single-camera data. Unlike prior works, DynaMix dynamically adapts to the structure and noise of the training data through three core components: (1) a Relabeling Module that refines pseudo-labels of single-camera identities on-the-fly; (2) an Efficient Centroids Module that maintains robust identity representations under a large identity space; and (3) a Data Sampling Module that carefully composes mixed data mini-batches to balance learning complexity and intra-batch diversity. All components are specifically designed to operate efficiently at scale, enabling effective training on millions of images and hundreds of thousands of identities. Extensive experiments demonstrate that DynaMix consistently outperforms state-of-the-art methods in generalizable person Re-ID. Read More
Feasible strategies in three-way conflict analysis with three-valued ratings AI updates on arXiv.org
Feasible strategies in three-way conflict analysis with three-valued ratingscs.AI updates on arXiv.org arXiv:2512.21420v2 Announce Type: new
Abstract: Most existing work on three-way conflict analysis has focused on trisecting agent pairs, agents, or issues, which contributes to understanding the nature of conflicts but falls short in addressing their resolution. Specifically, the formulation of feasible strategies, as an essential component of conflict resolution and mitigation, has received insufficient scholarly attention. Therefore, this paper aims to investigate feasible strategies from two perspectives of consistency and non-consistency. Particularly, we begin with computing the overall rating of a clique of agents based on positive and negative similarity degrees. Afterwards, considering the weights of both agents and issues, we propose weighted consistency and non-consistency measures, which are respectively used to identify the feasible strategies for a clique of agents. Algorithms are developed to identify feasible strategies, $L$-order feasible strategies, and the corresponding optimal ones. Finally, to demonstrate the practicality, effectiveness, and superiority of the proposed models, we apply them to two commonly used case studies on NBA labor negotiations and development plans for Gansu Province and conduct a sensitivity analysis on parameters and a comparative analysis with existing state-of-the-art conflict analysis approaches. The comparison results demonstrate that our conflict resolution models outperform the conventional approaches by unifying weighted agent-issue evaluation with consistency and non-consistency measures to enable the systematic identification of not only feasible strategies but also optimal solutions.
arXiv:2512.21420v2 Announce Type: new
Abstract: Most existing work on three-way conflict analysis has focused on trisecting agent pairs, agents, or issues, which contributes to understanding the nature of conflicts but falls short in addressing their resolution. Specifically, the formulation of feasible strategies, as an essential component of conflict resolution and mitigation, has received insufficient scholarly attention. Therefore, this paper aims to investigate feasible strategies from two perspectives of consistency and non-consistency. Particularly, we begin with computing the overall rating of a clique of agents based on positive and negative similarity degrees. Afterwards, considering the weights of both agents and issues, we propose weighted consistency and non-consistency measures, which are respectively used to identify the feasible strategies for a clique of agents. Algorithms are developed to identify feasible strategies, $L$-order feasible strategies, and the corresponding optimal ones. Finally, to demonstrate the practicality, effectiveness, and superiority of the proposed models, we apply them to two commonly used case studies on NBA labor negotiations and development plans for Gansu Province and conduct a sensitivity analysis on parameters and a comparative analysis with existing state-of-the-art conflict analysis approaches. The comparison results demonstrate that our conflict resolution models outperform the conventional approaches by unifying weighted agent-issue evaluation with consistency and non-consistency measures to enable the systematic identification of not only feasible strategies but also optimal solutions. Read More
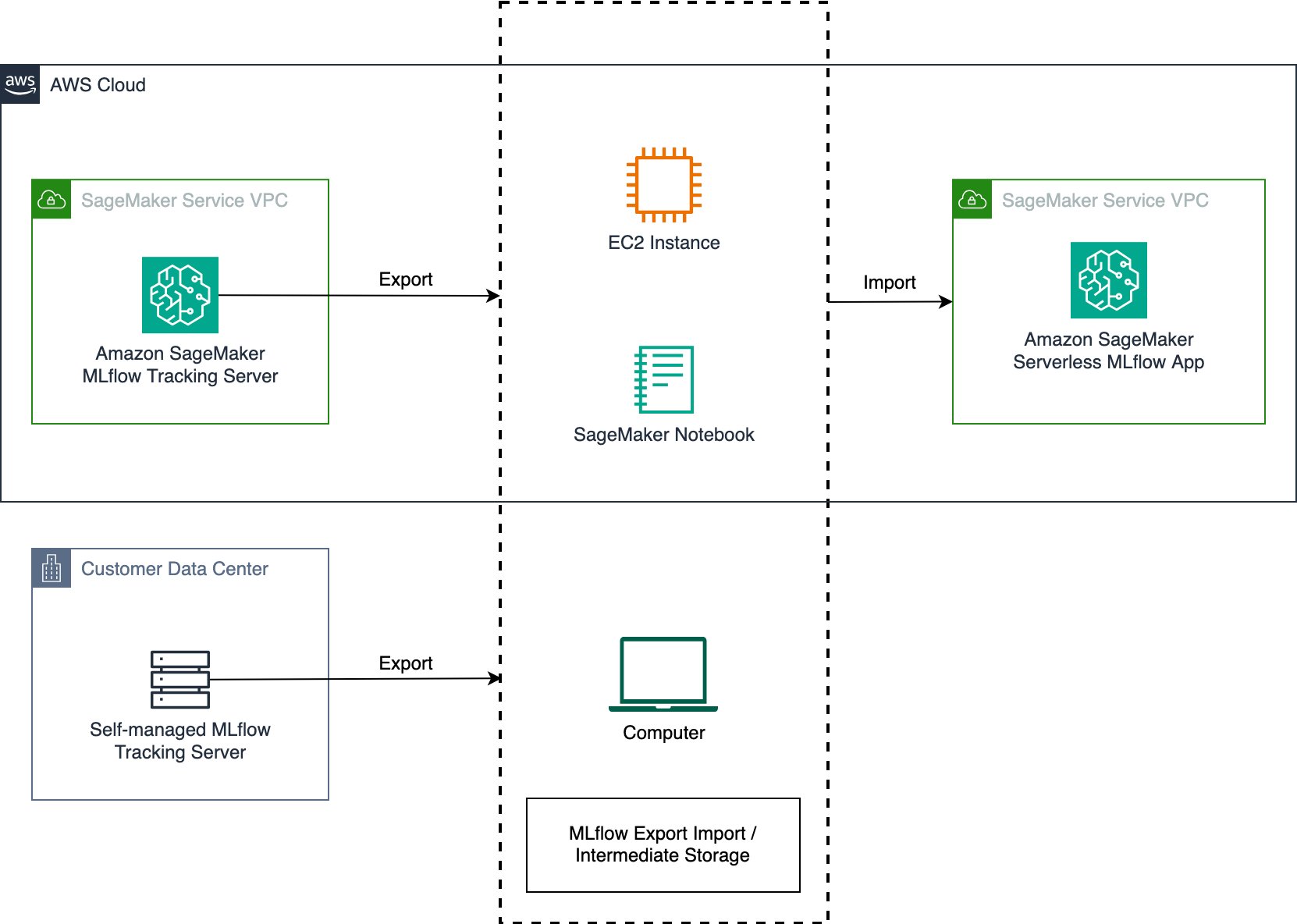
Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflowArtificial Intelligence
Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflowArtificial Intelligence This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success.
This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success. Read More
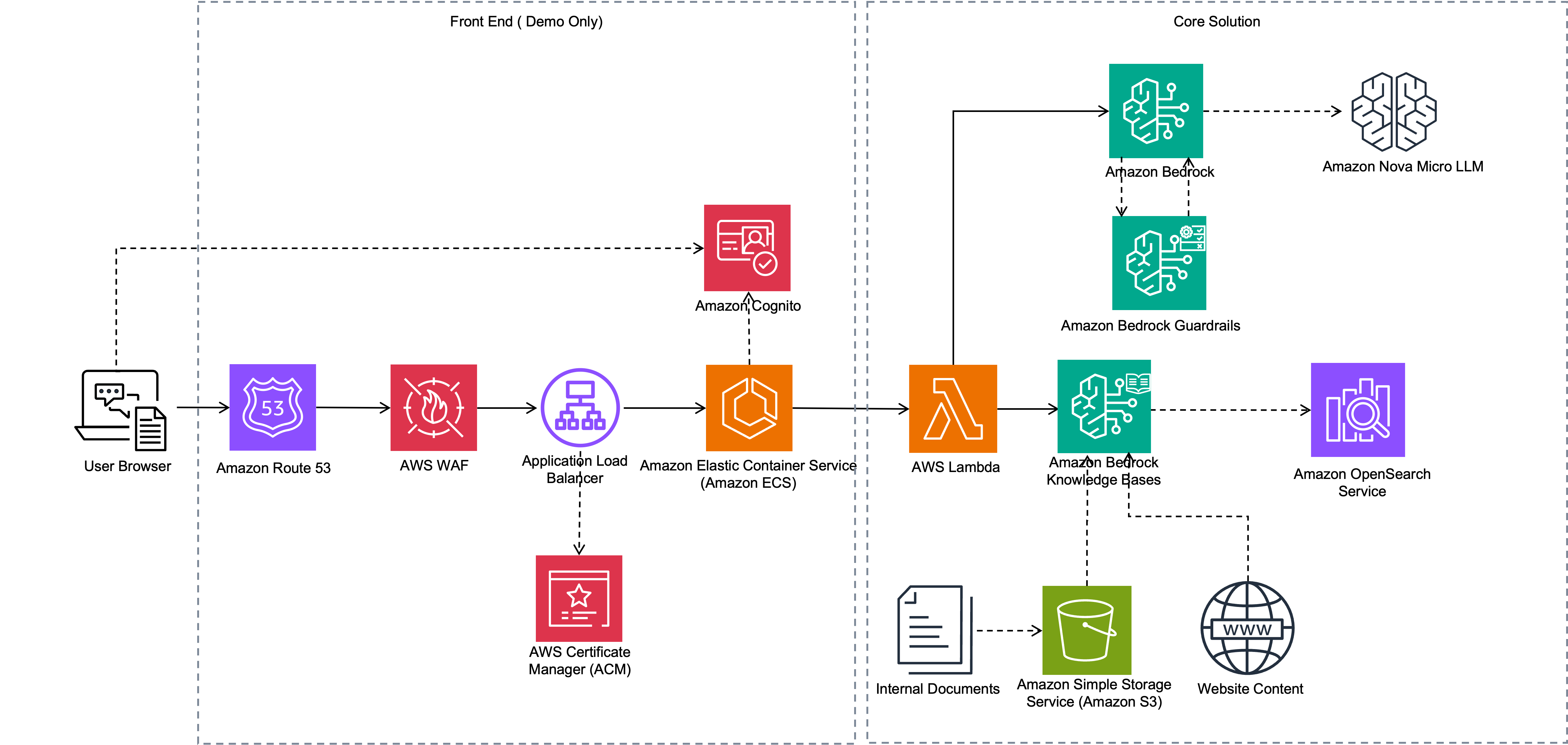
Build an AI-powered website assistant with Amazon BedrockArtificial Intelligence This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases.
This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases. Read More