Build a serverless conversational AI agent using Claude with LangGraph and managed MLflow on Amazon SageMaker AIArtificial Intelligence This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.
This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI. Read More

Vibe Researching as Wolf Coming: Can AI Agents with Skills Replace or Augment Social Scientists?cs.AI updates on arXiv.org arXiv:2602.22401v2 Announce Type: replace
Abstract: AI agents — systems that execute multi-step reasoning workflows with persistent state, tool access, and specialist skills — represent a qualitative shift from prior automation technologies in social science. Unlike chatbots that respond to isolated queries, AI agents can now read files, run code, query databases, search the web, and invoke domain-specific skills to execute entire research pipelines autonomously. This paper introduces the concept of vibe researching — the AI-era parallel to vibe coding (Karpathy, 2025) — and uses scholar-skill, a 23-skill plugin for Claude Code covering the full research pipeline from idea to submission, as an illustrative case. I develop a cognitive task framework that classifies research activities along two dimensions — codifiability and tacit knowledge requirement — to identify a delegation boundary that is cognitive, not sequential: it cuts through every stage of the research pipeline, not between stages. I argue that AI agents excel at speed, coverage, and methodological scaffolding but struggle with theoretical originality and tacit field knowledge. The paper concludes with an analysis of three implications for the profession — augmentation with fragile conditions, stratification risk, and a pedagogical crisis — and proposes five principles for responsible vibe researching.
arXiv:2602.22401v2 Announce Type: replace
Abstract: AI agents — systems that execute multi-step reasoning workflows with persistent state, tool access, and specialist skills — represent a qualitative shift from prior automation technologies in social science. Unlike chatbots that respond to isolated queries, AI agents can now read files, run code, query databases, search the web, and invoke domain-specific skills to execute entire research pipelines autonomously. This paper introduces the concept of vibe researching — the AI-era parallel to vibe coding (Karpathy, 2025) — and uses scholar-skill, a 23-skill plugin for Claude Code covering the full research pipeline from idea to submission, as an illustrative case. I develop a cognitive task framework that classifies research activities along two dimensions — codifiability and tacit knowledge requirement — to identify a delegation boundary that is cognitive, not sequential: it cuts through every stage of the research pipeline, not between stages. I argue that AI agents excel at speed, coverage, and methodological scaffolding but struggle with theoretical originality and tacit field knowledge. The paper concludes with an analysis of three implications for the profession — augmentation with fragile conditions, stratification risk, and a pedagogical crisis — and proposes five principles for responsible vibe researching. Read More
How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State ArchitectureMarkTechPost In this tutorial, we build an advanced multi-agent communication system using a structured message bus architecture powered by LangGraph and Pydantic. We define a strict ACP-style message schema that allows agents to communicate via a shared state rather than calling each other directly, enabling modularity, traceability, and production-grade orchestration. We implement three specialized agents, a
The post How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State Architecture appeared first on MarkTechPost.
In this tutorial, we build an advanced multi-agent communication system using a structured message bus architecture powered by LangGraph and Pydantic. We define a strict ACP-style message schema that allows agents to communicate via a shared state rather than calling each other directly, enabling modularity, traceability, and production-grade orchestration. We implement three specialized agents, a
The post How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State Architecture appeared first on MarkTechPost. Read More
Zero-Waste Agentic RAG: Designing Caching Architectures to Minimize Latency and LLM Costs at ScaleTowards Data Science Reducing LLM costs by 30% with validation-aware, multi-tier caching
The post Zero-Waste Agentic RAG: Designing Caching Architectures to Minimize Latency and LLM Costs at Scale appeared first on Towards Data Science.
Reducing LLM costs by 30% with validation-aware, multi-tier caching
The post Zero-Waste Agentic RAG: Designing Caching Architectures to Minimize Latency and LLM Costs at Scale appeared first on Towards Data Science. Read More
Context Engineering as Your Competitive EdgeTowards Data Science If you have both unique domain expertise and know how to make it usable to your AI systems, you’ll be hard to beat.
The post Context Engineering as Your Competitive Edge appeared first on Towards Data Science.
If you have both unique domain expertise and know how to make it usable to your AI systems, you’ll be hard to beat.
The post Context Engineering as Your Competitive Edge appeared first on Towards Data Science. Read More
Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and MemoryMarkTechPost As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost.
As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost. Read More
A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model DeploymentMarkTechPost In this tutorial, we build a complete, production-grade ML experimentation and deployment workflow using MLflow. We start by launching a dedicated MLflow Tracking Server with a structured backend and artifact store, enabling us to track experiments in a scalable, reproducible manner. We then train multiple machine learning models using a nested hyperparameter sweep while automatically
The post A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model Deployment appeared first on MarkTechPost.
In this tutorial, we build a complete, production-grade ML experimentation and deployment workflow using MLflow. We start by launching a dedicated MLflow Tracking Server with a structured backend and artifact store, enabling us to track experiments in a scalable, reproducible manner. We then train multiple machine learning models using a nested hyperparameter sweep while automatically
The post A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model Deployment appeared first on MarkTechPost. Read More
MovieTeller: Tool-augmented Movie Synopsis with ID Consistent Progressive Abstractioncs.AI updates on arXiv.org arXiv:2602.23228v1 Announce Type: cross
Abstract: With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external “tool” to establish Factual Groundings–precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM’s reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines.
arXiv:2602.23228v1 Announce Type: cross
Abstract: With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external “tool” to establish Factual Groundings–precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM’s reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines. Read More
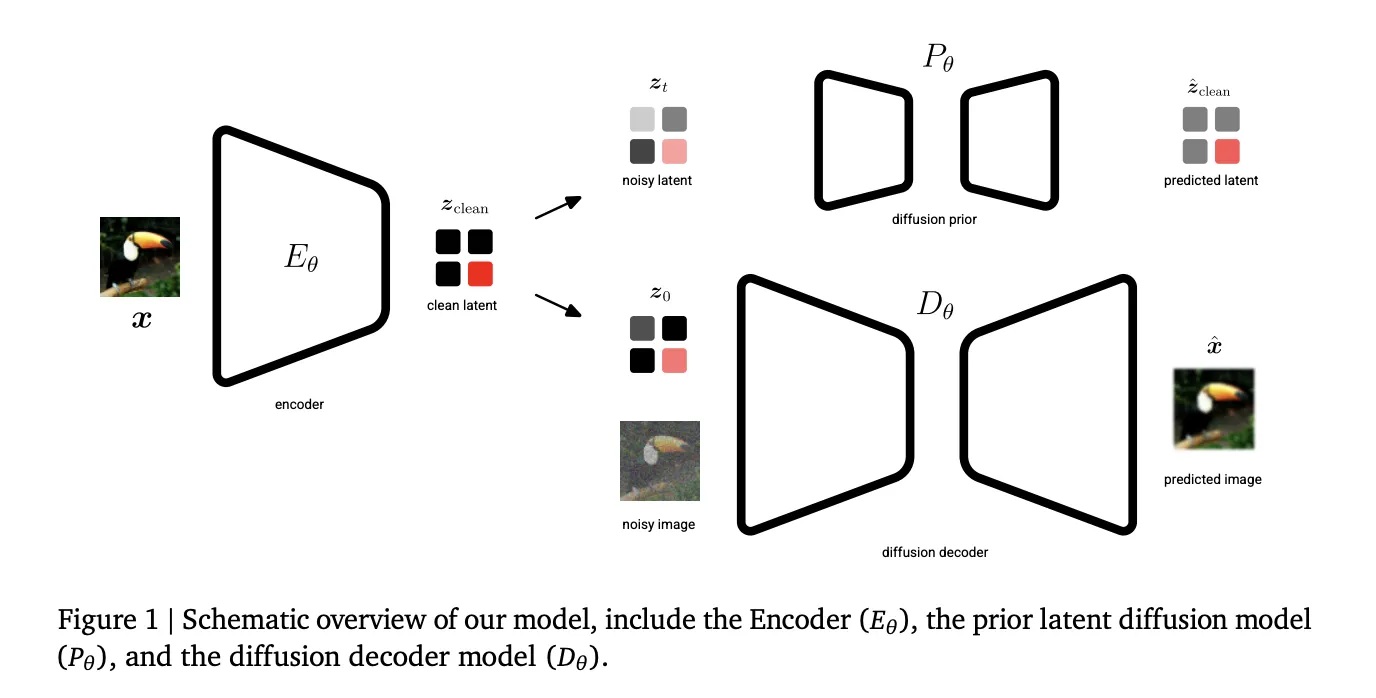
Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and DecoderMarkTechPost Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By compressing data into a lower-dimensional latent space, models can scale effectively. However, a fundamental trade-off persists: lower information density makes latents easier to learn but sacrifices reconstruction quality, while higher density enables near-perfect reconstruction but
The post Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder appeared first on MarkTechPost.
Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By compressing data into a lower-dimensional latent space, models can scale effectively. However, a fundamental trade-off persists: lower information density makes latents easier to learn but sacrifices reconstruction quality, while higher density enables near-perfect reconstruction but
The post Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder appeared first on MarkTechPost. Read More
Claude Skills and Subagents: Escaping the Prompt Engineering Hamster WheelTowards Data Science How reusable, lazy-loaded instructions solve the context bloat problem in AI-assisted development.
The post Claude Skills and Subagents: Escaping the Prompt Engineering Hamster Wheel appeared first on Towards Data Science.
How reusable, lazy-loaded instructions solve the context bloat problem in AI-assisted development.
The post Claude Skills and Subagents: Escaping the Prompt Engineering Hamster Wheel appeared first on Towards Data Science. Read More