
Hitachi bets on industrial expertise to win the physical AI raceAI News Physical AI–the branch of artificial intelligence that controls robots and industrial machinery in the real world–has a hierarchy problem. At the top, OpenAI and Google are scaling multimodal foundation models. In the middle, Nvidia is building the platforms and tools for physical AI development. And then there is a third camp: industrial manufacturers like Hitachi
The post Hitachi bets on industrial expertise to win the physical AI race appeared first on AI News.
Physical AI–the branch of artificial intelligence that controls robots and industrial machinery in the real world–has a hierarchy problem. At the top, OpenAI and Google are scaling multimodal foundation models. In the middle, Nvidia is building the platforms and tools for physical AI development. And then there is a third camp: industrial manufacturers like Hitachi
The post Hitachi bets on industrial expertise to win the physical AI race appeared first on AI News. Read More

Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inferenceMarkTechPost In the high-stakes world of AI infrastructure, the industry has operated under a singular assumption: flexibility is king. We build general-purpose GPUs because AI models change every week, and we need programmable silicon that can adapt to the next research breakthrough. But Taalas, the Toronto-based startup thinks that flexibility is exactly what’s holding AI back.
The post Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inference appeared first on MarkTechPost.
In the high-stakes world of AI infrastructure, the industry has operated under a singular assumption: flexibility is king. We build general-purpose GPUs because AI models change every week, and we need programmable silicon that can adapt to the next research breakthrough. But Taalas, the Toronto-based startup thinks that flexibility is exactly what’s holding AI back.
The post Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inference appeared first on MarkTechPost. Read More

The Reality of Vibe Coding: AI Agents and the Security Debt CrisisTowards Data Science Why optimizing for speed over safety is leaving applications vulnerable, and how to fix it.
The post The Reality of Vibe Coding: AI Agents and the Security Debt Crisis appeared first on Towards Data Science.
Why optimizing for speed over safety is leaving applications vulnerable, and how to fix it.
The post The Reality of Vibe Coding: AI Agents and the Security Debt Crisis appeared first on Towards Data Science. Read More

Role Intelligence Chief AI Officer — At a Glance IBM IBV 2025 CAIO Study IAPP AIGP Tech Jacks 20-Role Table 60-Posting Doc C Analysis Chief AI Officer ▲ Very High Demand The CAIO sets enterprise AI strategy, governs adoption, and answers to the board. 26% of organizations globally now have one, up from 11% two […]

Role Intelligence AI Risk Manager — At a Glance IAPP 2025-26 ZipRecruiter NIST AI RMF AI Risk Manager ⬆ Very High Identifies, measures, and manages technical and operational AI vulnerabilities using model risk management frameworks. Financial services is the dominant employer. Very high demand driven by SR 11-7 expansion to AI/ML and EU AI Act […]
Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use CasesMarkTechPost The balance of power in the digital age is shifting. While governments and large corporations have long used data to track individuals, a new open-source project called OpenPlanter is giving that power back to the public. Created by a developer ‘Shin Megami Boson‘, OpenPlanter is a recursive-language-model investigation agent. Its goal is simple: help you
The post Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use Cases appeared first on MarkTechPost.
The balance of power in the digital age is shifting. While governments and large corporations have long used data to track individuals, a new open-source project called OpenPlanter is giving that power back to the public. Created by a developer ‘Shin Megami Boson‘, OpenPlanter is a recursive-language-model investigation agent. Its goal is simple: help you
The post Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use Cases appeared first on MarkTechPost. Read More
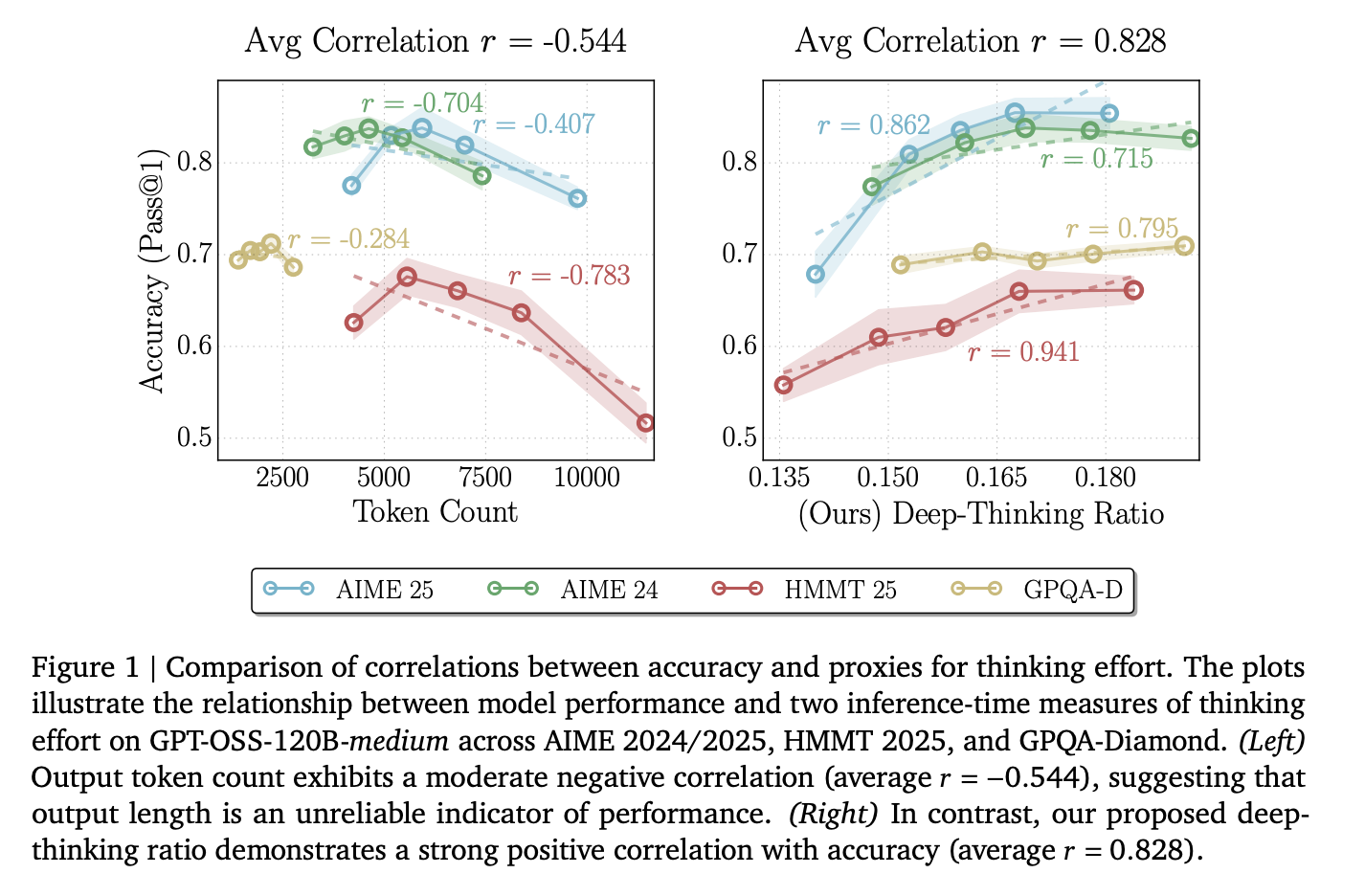
A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by HalfMarkTechPost For the last few years, the AI world has followed a simple rule: if you want a Large Language Model (LLM) to solve a harder problem, make its Chain-of-Thought (CoT) longer. But new research from the University of Virginia and Google proves that ‘thinking long’ is not the same as ‘thinking hard’. The research team
The post A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half appeared first on MarkTechPost.
For the last few years, the AI world has followed a simple rule: if you want a Large Language Model (LLM) to solve a harder problem, make its Chain-of-Thought (CoT) longer. But new research from the University of Virginia and Google proves that ‘thinking long’ is not the same as ‘thinking hard’. The research team
The post A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half appeared first on MarkTechPost. Read More
How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured OutputsMarkTechPost In this tutorial, we build a production-style Route Optimizer Agent for a logistics dispatch center using the latest LangChain agent APIs. We design a tool-driven workflow in which the agent reliably computes distances, ETAs, and optimal routes rather than guessing, and we enforce structured outputs to make the results directly usable in downstream systems. We
The post How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured Outputs appeared first on MarkTechPost.
In this tutorial, we build a production-style Route Optimizer Agent for a logistics dispatch center using the latest LangChain agent APIs. We design a tool-driven workflow in which the agent reliably computes distances, ETAs, and optimal routes rather than guessing, and we enforce structured outputs to make the results directly usable in downstream systems. We
The post How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured Outputs appeared first on MarkTechPost. Read More

Role Intelligence AI Ethics Officer — At a Glance IAPP 2025-26 ZipRecruiter EU AI Act AI Ethics Officer ⬆ Very High Designs and enforces ethical guardrails around AI systems, from bias audits to fairness assessments. Entry-level accessible with philosophy, law, or data science backgrounds. Very high demand driven by EU AI Act enforcement, with qualified […]

Role Intelligence AI Compliance Manager — At a Glance IAPP 2025-26 ZipRecruiter EU AI Act AI Compliance Manager ⬆ Very High Builds governance frameworks and ensures AI systems meet regulatory requirements across the enterprise. Mid-level entry from compliance, legal, or risk backgrounds. Very high demand driven by EU AI Act enforcement and a severe talent […]