
AutoMetrics: Approximate Human Judgements with Automatically Generated Evaluatorscs.AI updates on arXiv.org arXiv:2512.17267v1 Announce Type: cross
Abstract: Evaluating user-facing AI applications remains a central challenge, especially in open-ended domains such as travel planning, clinical note generation, or dialogue. The gold standard is user feedback (e.g., thumbs up/down) or behavioral signals (e.g., retention), but these are often scarce in prototypes and research projects, or too-slow to use for system optimization. We present AutoMetrics, a framework for synthesizing evaluation metrics under low-data constraints. AutoMetrics combines retrieval from MetricBank, a collection of 48 metrics we curate, with automatically generated LLM-as-a-Judge criteria informed by lightweight human feedback. These metrics are composed via regression to maximize correlation with human signal. AutoMetrics takes you from expensive measures to interpretable automatic metrics. Across 5 diverse tasks, AutoMetrics improves Kendall correlation with human ratings by up to 33.4% over LLM-as-a-Judge while requiring fewer than 100 feedback points. We show that AutoMetrics can be used as a proxy reward to equal effect as a verifiable reward. We release the full AutoMetrics toolkit and MetricBank to accelerate adaptive evaluation of LLM applications.
arXiv:2512.17267v1 Announce Type: cross
Abstract: Evaluating user-facing AI applications remains a central challenge, especially in open-ended domains such as travel planning, clinical note generation, or dialogue. The gold standard is user feedback (e.g., thumbs up/down) or behavioral signals (e.g., retention), but these are often scarce in prototypes and research projects, or too-slow to use for system optimization. We present AutoMetrics, a framework for synthesizing evaluation metrics under low-data constraints. AutoMetrics combines retrieval from MetricBank, a collection of 48 metrics we curate, with automatically generated LLM-as-a-Judge criteria informed by lightweight human feedback. These metrics are composed via regression to maximize correlation with human signal. AutoMetrics takes you from expensive measures to interpretable automatic metrics. Across 5 diverse tasks, AutoMetrics improves Kendall correlation with human ratings by up to 33.4% over LLM-as-a-Judge while requiring fewer than 100 feedback points. We show that AutoMetrics can be used as a proxy reward to equal effect as a verifiable reward. We release the full AutoMetrics toolkit and MetricBank to accelerate adaptive evaluation of LLM applications. Read More
Robust TTS Training via Self-Purifying Flow Matching for the WildSpoof 2026 TTS Trackcs.AI updates on arXiv.org arXiv:2512.17293v1 Announce Type: cross
Abstract: This paper presents a lightweight text-to-speech (TTS) system developed for the WildSpoof Challenge TTS Track. Our approach fine-tunes the recently released open-weight TTS model, textit{Supertonic}footnote{url{https://github.com/supertone-inc/supertonic}}, with Self-Purifying Flow Matching (SPFM) to enable robust adaptation to in-the-wild speech. SPFM mitigates label noise by comparing conditional and unconditional flow matching losses on each sample, routing suspicious text–speech pairs to unconditional training while still leveraging their acoustic information. The resulting model achieves the lowest Word Error Rate (WER) among all participating teams, while ranking second in perceptual metrics such as UTMOS and DNSMOS. These findings demonstrate that efficient, open-weight architectures like Supertonic can be effectively adapted to diverse real-world speech conditions when combined with explicit noise-handling mechanisms such as SPFM.
arXiv:2512.17293v1 Announce Type: cross
Abstract: This paper presents a lightweight text-to-speech (TTS) system developed for the WildSpoof Challenge TTS Track. Our approach fine-tunes the recently released open-weight TTS model, textit{Supertonic}footnote{url{https://github.com/supertone-inc/supertonic}}, with Self-Purifying Flow Matching (SPFM) to enable robust adaptation to in-the-wild speech. SPFM mitigates label noise by comparing conditional and unconditional flow matching losses on each sample, routing suspicious text–speech pairs to unconditional training while still leveraging their acoustic information. The resulting model achieves the lowest Word Error Rate (WER) among all participating teams, while ranking second in perceptual metrics such as UTMOS and DNSMOS. These findings demonstrate that efficient, open-weight architectures like Supertonic can be effectively adapted to diverse real-world speech conditions when combined with explicit noise-handling mechanisms such as SPFM. Read More
SCOPE: Sequential Causal Optimization of Process Interventionscs.AI updates on arXiv.org arXiv:2512.17629v1 Announce Type: cross
Abstract: Prescriptive Process Monitoring (PresPM) recommends interventions during business processes to optimize key performance indicators (KPIs). In realistic settings, interventions are rarely isolated: organizations need to align sequences of interventions to jointly steer the outcome of a case. Existing PresPM approaches fall short in this respect. Many focus on a single intervention decision, while others treat multiple interventions independently, ignoring how they interact over time. Methods that do address these dependencies depend either on simulation or data augmentation to approximate the process to train a Reinforcement Learning (RL) agent, which can create a reality gap and introduce bias. We introduce SCOPE, a PresPM approach that learns aligned sequential intervention recommendations. SCOPE employs backward induction to estimate the effect of each candidate intervention action, propagating its impact from the final decision point back to the first. By leveraging causal learners, our method can utilize observational data directly, unlike methods that require constructing process approximations for reinforcement learning. Experiments on both an existing synthetic dataset and a new semi-synthetic dataset show that SCOPE consistently outperforms state-of-the-art PresPM techniques in optimizing the KPI. The novel semi-synthetic setup, based on a real-life event log, is provided as a reusable benchmark for future work on sequential PresPM.
arXiv:2512.17629v1 Announce Type: cross
Abstract: Prescriptive Process Monitoring (PresPM) recommends interventions during business processes to optimize key performance indicators (KPIs). In realistic settings, interventions are rarely isolated: organizations need to align sequences of interventions to jointly steer the outcome of a case. Existing PresPM approaches fall short in this respect. Many focus on a single intervention decision, while others treat multiple interventions independently, ignoring how they interact over time. Methods that do address these dependencies depend either on simulation or data augmentation to approximate the process to train a Reinforcement Learning (RL) agent, which can create a reality gap and introduce bias. We introduce SCOPE, a PresPM approach that learns aligned sequential intervention recommendations. SCOPE employs backward induction to estimate the effect of each candidate intervention action, propagating its impact from the final decision point back to the first. By leveraging causal learners, our method can utilize observational data directly, unlike methods that require constructing process approximations for reinforcement learning. Experiments on both an existing synthetic dataset and a new semi-synthetic dataset show that SCOPE consistently outperforms state-of-the-art PresPM techniques in optimizing the KPI. The novel semi-synthetic setup, based on a real-life event log, is provided as a reusable benchmark for future work on sequential PresPM. Read More
Realistic threat perception drives intergroup conflict: A causal, dynamic analysis using generative-agent simulationscs.AI updates on arXiv.org arXiv:2512.17066v1 Announce Type: new
Abstract: Human conflict is often attributed to threats against material conditions and symbolic values, yet it remains unclear how they interact and which dominates. Progress is limited by weak causal control, ethical constraints, and scarce temporal data. We address these barriers using simulations of large language model (LLM)-driven agents in virtual societies, independently varying realistic and symbolic threat while tracking actions, language, and attitudes. Representational analyses show that the underlying LLM encodes realistic threat, symbolic threat, and hostility as distinct internal states, that our manipulations map onto them, and that steering these states causally shifts behavior. Our simulations provide a causal account of threat-driven conflict over time: realistic threat directly increases hostility, whereas symbolic threat effects are weaker, fully mediated by ingroup bias, and increase hostility only when realistic threat is absent. Non-hostile intergroup contact buffers escalation, and structural asymmetries concentrate hostility among majority groups.
arXiv:2512.17066v1 Announce Type: new
Abstract: Human conflict is often attributed to threats against material conditions and symbolic values, yet it remains unclear how they interact and which dominates. Progress is limited by weak causal control, ethical constraints, and scarce temporal data. We address these barriers using simulations of large language model (LLM)-driven agents in virtual societies, independently varying realistic and symbolic threat while tracking actions, language, and attitudes. Representational analyses show that the underlying LLM encodes realistic threat, symbolic threat, and hostility as distinct internal states, that our manipulations map onto them, and that steering these states causally shifts behavior. Our simulations provide a causal account of threat-driven conflict over time: realistic threat directly increases hostility, whereas symbolic threat effects are weaker, fully mediated by ingroup bias, and increase hostility only when realistic threat is absent. Non-hostile intergroup contact buffers escalation, and structural asymmetries concentrate hostility among majority groups. Read More
Solomonoff-Inspired Hypothesis Ranking with LLMs for Prediction Under Uncertaintycs.AI updates on arXiv.org arXiv:2512.17145v1 Announce Type: new
Abstract: Reasoning under uncertainty is a key challenge in AI, especially for real-world tasks, where problems with sparse data demands systematic generalisation. Existing approaches struggle to balance accuracy and simplicity when evaluating multiple candidate solutions. We propose a Solomonoff-inspired method that weights LLM-generated hypotheses by simplicity and predictive fit. Applied to benchmark (Mini-ARC) tasks, our method produces Solomonoff-weighted mixtures for per-cell predictions, yielding conservative, uncertainty-aware outputs even when hypotheses are noisy or partially incorrect. Compared to Bayesian Model Averaging (BMA), Solomonoff scoring spreads probability more evenly across competing hypotheses, while BMA concentrates weight on the most likely but potentially flawed candidates. Across tasks, this highlights the value of algorithmic information-theoretic priors for interpretable, reliable multi-hypothesis reasoning under uncertainty.
arXiv:2512.17145v1 Announce Type: new
Abstract: Reasoning under uncertainty is a key challenge in AI, especially for real-world tasks, where problems with sparse data demands systematic generalisation. Existing approaches struggle to balance accuracy and simplicity when evaluating multiple candidate solutions. We propose a Solomonoff-inspired method that weights LLM-generated hypotheses by simplicity and predictive fit. Applied to benchmark (Mini-ARC) tasks, our method produces Solomonoff-weighted mixtures for per-cell predictions, yielding conservative, uncertainty-aware outputs even when hypotheses are noisy or partially incorrect. Compared to Bayesian Model Averaging (BMA), Solomonoff scoring spreads probability more evenly across competing hypotheses, while BMA concentrates weight on the most likely but potentially flawed candidates. Across tasks, this highlights the value of algorithmic information-theoretic priors for interpretable, reliable multi-hypothesis reasoning under uncertainty. Read More
The Machine Learning “Advent Calendar” Day 21: Gradient Boosted Decision Tree Regressor in ExcelTowards Data Science Gradient descent in function space with decision trees
The post The Machine Learning “Advent Calendar” Day 21: Gradient Boosted Decision Tree Regressor in Excel appeared first on Towards Data Science.
Gradient descent in function space with decision trees
The post The Machine Learning “Advent Calendar” Day 21: Gradient Boosted Decision Tree Regressor in Excel appeared first on Towards Data Science. Read More

NVIDIA AI Releases Nemotron 3: A Hybrid Mamba Transformer MoE Stack for Long Context Agentic AIMarkTechPost NVIDIA has released the Nemotron 3 family of open models as part of a full stack for agentic AI, including model weights, datasets and reinforcement learning tools. The family has three sizes, Nano, Super and Ultra, and targets multi agent systems that need long context reasoning with tight control over inference cost. Nano has about
The post NVIDIA AI Releases Nemotron 3: A Hybrid Mamba Transformer MoE Stack for Long Context Agentic AI appeared first on MarkTechPost.
NVIDIA has released the Nemotron 3 family of open models as part of a full stack for agentic AI, including model weights, datasets and reinforcement learning tools. The family has three sizes, Nano, Super and Ultra, and targets multi agent systems that need long context reasoning with tight control over inference cost. Nano has about
The post NVIDIA AI Releases Nemotron 3: A Hybrid Mamba Transformer MoE Stack for Long Context Agentic AI appeared first on MarkTechPost. Read More
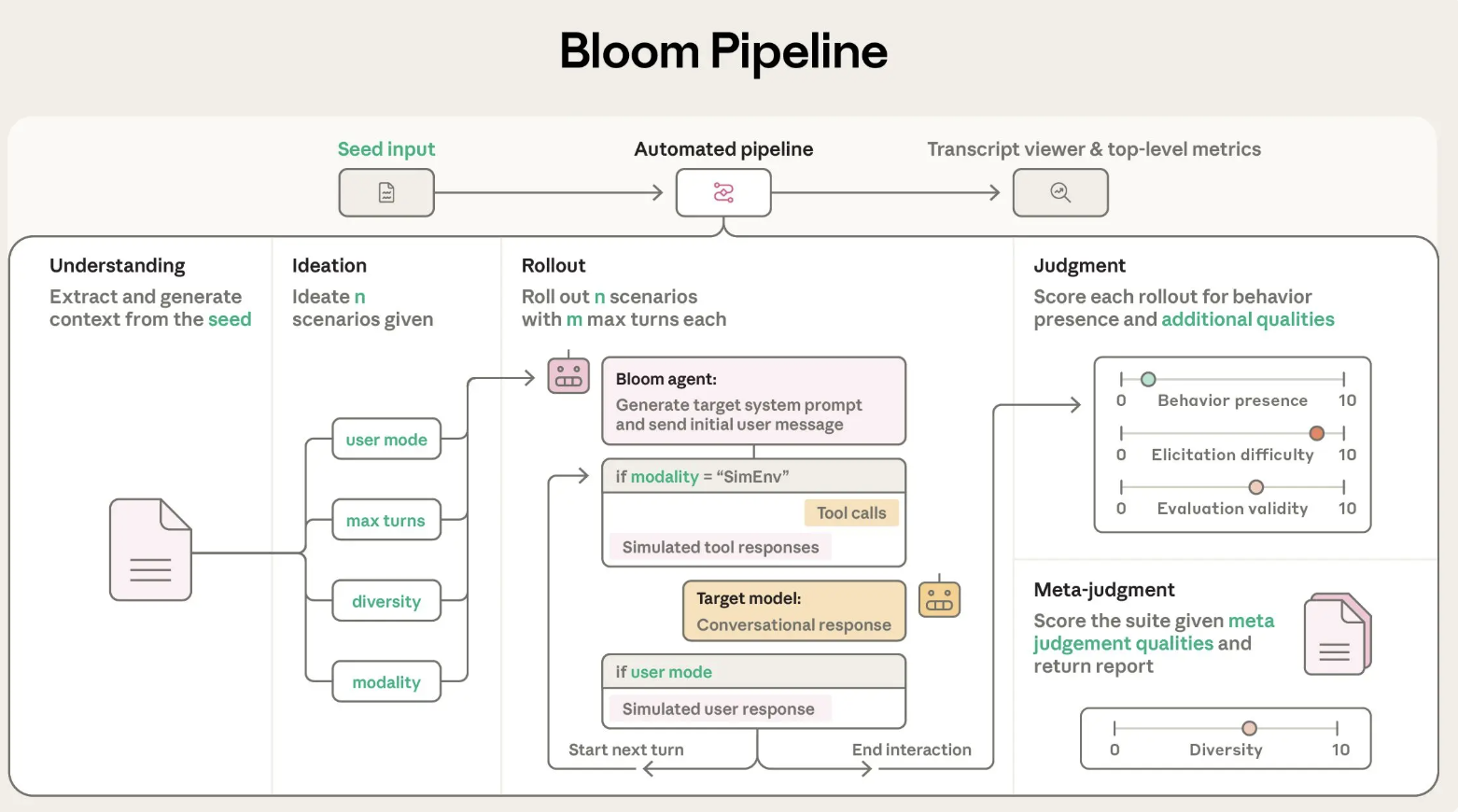
Anthropic AI Releases Bloom: An Open-Source Agentic Framework for Automated Behavioral Evaluations of Frontier AI ModelsMarkTechPost Anthropic has released Bloom, an open source agentic framework that automates behavioral evaluations for frontier AI models. The system takes a researcher specified behavior and builds targeted evaluations that measure how often and how strongly that behavior appears in realistic scenarios. Why Bloom? Behavioral evaluations for safety and alignment are expensive to design and maintain.
The post Anthropic AI Releases Bloom: An Open-Source Agentic Framework for Automated Behavioral Evaluations of Frontier AI Models appeared first on MarkTechPost.
Anthropic has released Bloom, an open source agentic framework that automates behavioral evaluations for frontier AI models. The system takes a researcher specified behavior and builds targeted evaluations that measure how often and how strongly that behavior appears in realistic scenarios. Why Bloom? Behavioral evaluations for safety and alignment are expensive to design and maintain.
The post Anthropic AI Releases Bloom: An Open-Source Agentic Framework for Automated Behavioral Evaluations of Frontier AI Models appeared first on MarkTechPost. Read More
Understanding the Generative AI UserTowards Data Science What do regular technology users think (and know) about AI?
The post Understanding the Generative AI User appeared first on Towards Data Science.
What do regular technology users think (and know) about AI?
The post Understanding the Generative AI User appeared first on Towards Data Science. Read More
Tools for Your LLM: a Deep Dive into MCPTowards Data Science MCP is a key enabler into turning your LLM into an agent by providing it with tools to retrieve real-time information or perform actions.
In this deep dive we cover how MCP works, when to use it, and what to watch out for.
The post Tools for Your LLM: a Deep Dive into MCP appeared first on Towards Data Science.
MCP is a key enabler into turning your LLM into an agent by providing it with tools to retrieve real-time information or perform actions.
In this deep dive we cover how MCP works, when to use it, and what to watch out for.
The post Tools for Your LLM: a Deep Dive into MCP appeared first on Towards Data Science. Read More