
Datasets for machine learning and for assessing the intelligence level of automatic patent search systemscs.AI updates on arXiv.org arXiv:2512.18384v1 Announce Type: cross
Abstract: The key to success in automating prior art search in patent research using artificial intelligence lies in developing large datasets for machine learning and ensuring their availability. This work is dedicated to providing a comprehensive solution to the problem of creating infrastructure for research in this field, including datasets and tools for calculating search quality criteria. The paper discusses the concept of semantic clusters of patent documents that determine the state of the art in a given subject, as proposed by the authors. A definition of such semantic clusters is also provided. Prior art search is presented as the task of identifying elements within a semantic cluster of patent documents in the subject area specified by the document under consideration. A generator of user-configurable datasets for machine learning, based on collections of U.S. and Russian patent documents, is described. The dataset generator creates a database of links to documents in semantic clusters. Then, based on user-defined parameters, it forms a dataset of semantic clusters in JSON format for machine learning. To evaluate machine learning outcomes, it is proposed to calculate search quality scores that account for semantic clusters of the documents being searched. To automate the evaluation process, the paper describes a utility developed by the authors for assessing the quality of prior art document search.
arXiv:2512.18384v1 Announce Type: cross
Abstract: The key to success in automating prior art search in patent research using artificial intelligence lies in developing large datasets for machine learning and ensuring their availability. This work is dedicated to providing a comprehensive solution to the problem of creating infrastructure for research in this field, including datasets and tools for calculating search quality criteria. The paper discusses the concept of semantic clusters of patent documents that determine the state of the art in a given subject, as proposed by the authors. A definition of such semantic clusters is also provided. Prior art search is presented as the task of identifying elements within a semantic cluster of patent documents in the subject area specified by the document under consideration. A generator of user-configurable datasets for machine learning, based on collections of U.S. and Russian patent documents, is described. The dataset generator creates a database of links to documents in semantic clusters. Then, based on user-defined parameters, it forms a dataset of semantic clusters in JSON format for machine learning. To evaluate machine learning outcomes, it is proposed to calculate search quality scores that account for semantic clusters of the documents being searched. To automate the evaluation process, the paper describes a utility developed by the authors for assessing the quality of prior art document search. Read More

Gistr: The Smart AI Notebook for Organizing KnowledgeKDnuggets This article explains how Gistr transforms the way data professionals interact with their most valuable asset: their accumulated knowledge.
This article explains how Gistr transforms the way data professionals interact with their most valuable asset: their accumulated knowledge. Read More
The Geometry of Laziness: What Angles Reveal About AI HallucinationsTowards Data Science A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science.
A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science. Read More
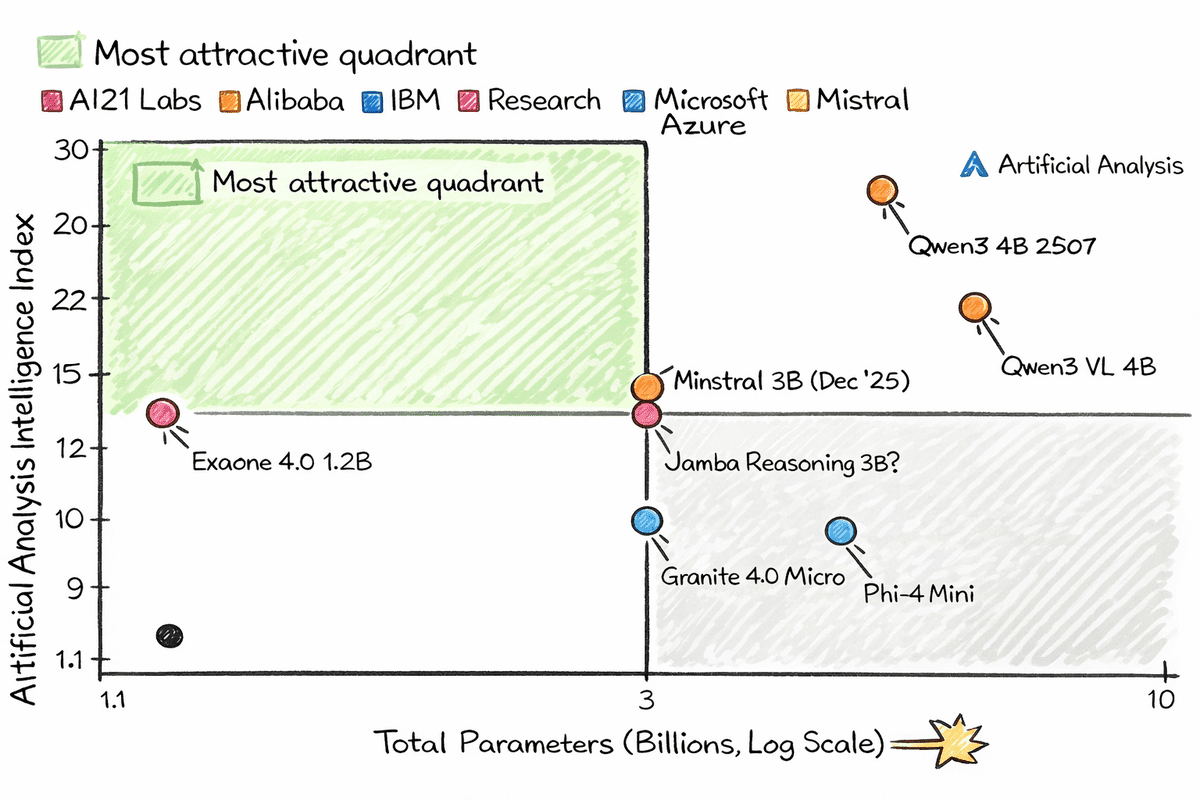
7 Tiny AI Models for Raspberry PiKDnuggets This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge.
This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge. Read More
The Machine Learning “Advent Calendar” Day 22: Embeddings in ExcelTowards Data Science Understanding text embeddings through simple models and Excel
The post The Machine Learning “Advent Calendar” Day 22: Embeddings in Excel appeared first on Towards Data Science.
Understanding text embeddings through simple models and Excel
The post The Machine Learning “Advent Calendar” Day 22: Embeddings in Excel appeared first on Towards Data Science. Read More
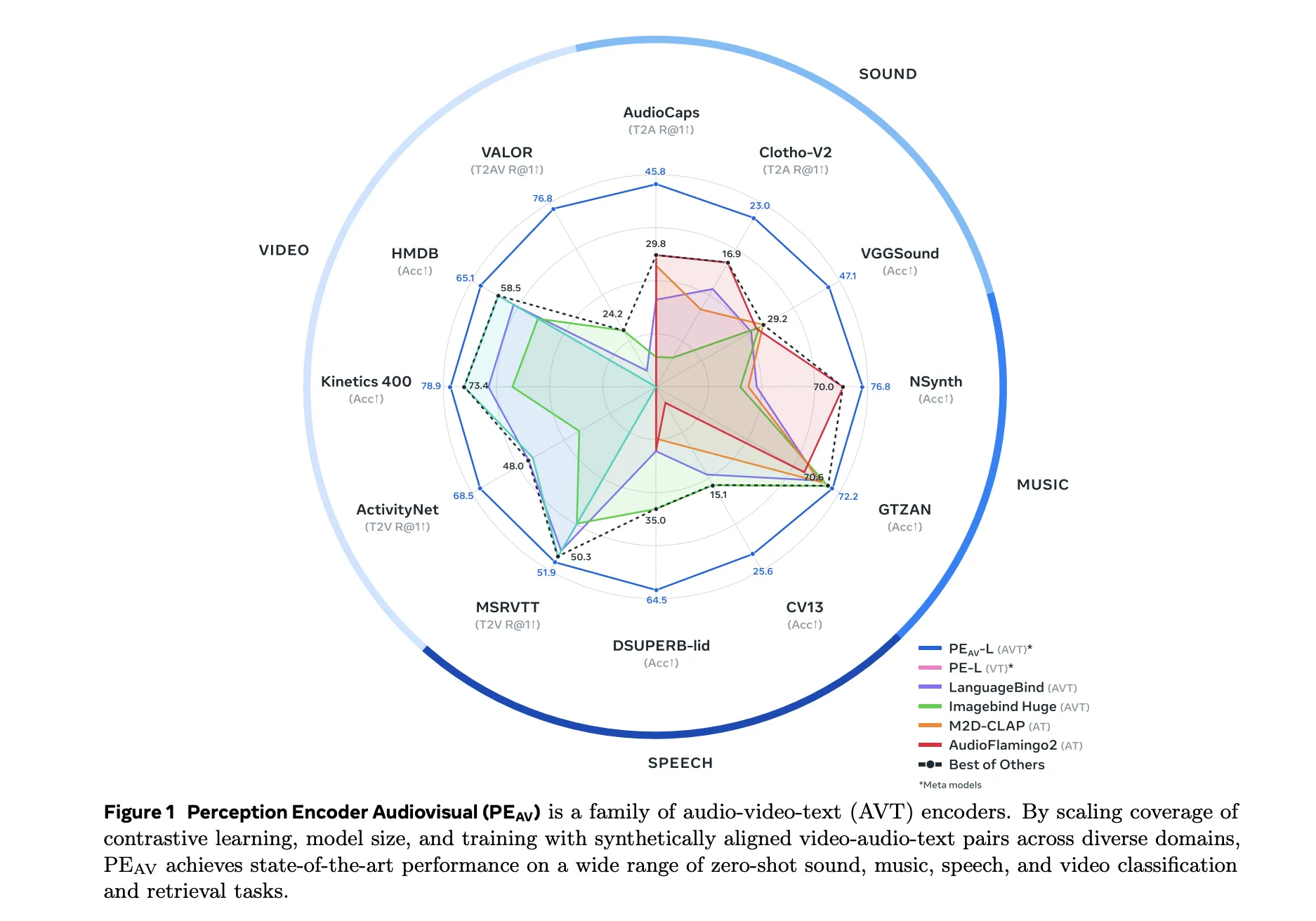
Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal RetrievalMarkTechPost Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions. From Perception Encoder to PEAV Perception Encoder,
The post Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval appeared first on MarkTechPost.
Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions. From Perception Encoder to PEAV Perception Encoder,
The post Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval appeared first on MarkTechPost. Read More
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI Towards Data Science
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AITowards Data Science For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science.
For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science. Read More
Move Beyond Chain-of-Thought with Chain-of-Draft on Amazon BedrockArtificial Intelligence This post explores Chain-of-Draft (CoD), an innovative prompting technique introduced in a Zoom AI Research paper Chain of Draft: Thinking Faster by Writing Less, that revolutionizes how models approach reasoning tasks. While Chain-of-Thought (CoT) prompting has been the go-to method for enhancing model reasoning, CoD offers a more efficient alternative that mirrors human problem-solving patterns—using concise, high-signal thinking steps rather than verbose explanations.
This post explores Chain-of-Draft (CoD), an innovative prompting technique introduced in a Zoom AI Research paper Chain of Draft: Thinking Faster by Writing Less, that revolutionizes how models approach reasoning tasks. While Chain-of-Thought (CoT) prompting has been the go-to method for enhancing model reasoning, CoD offers a more efficient alternative that mirrors human problem-solving patterns—using concise, high-signal thinking steps rather than verbose explanations. Read More
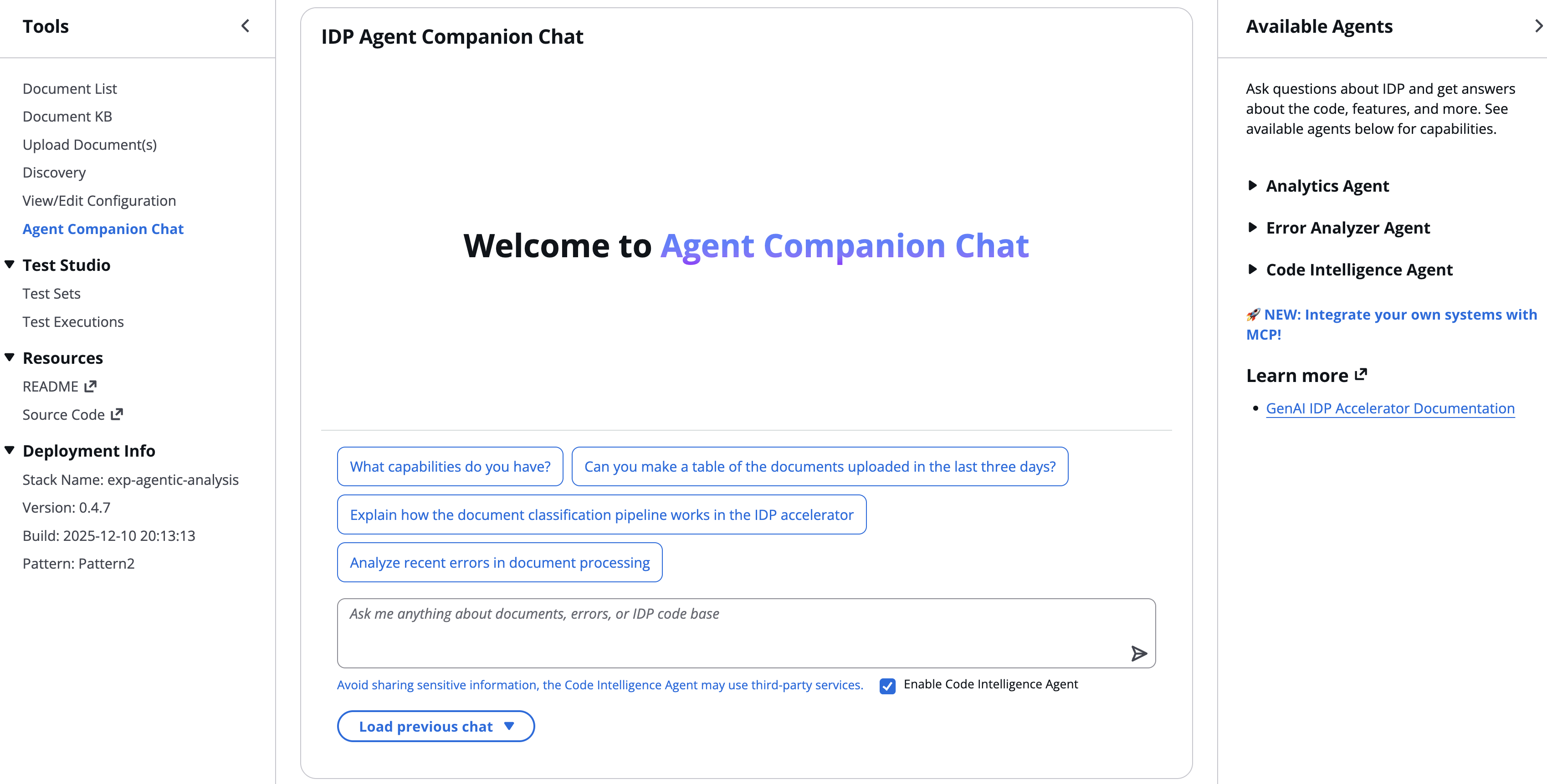
Enhance document analytics with Strands AI Agents for the GenAI IDP AcceleratorArtificial Intelligence To address the need for businesses to quickly analyze information and unlock actionable insights, we are announcing Analytics Agent, a new feature that is seamlessly integrated into the GenAI IDP Accelerator. With this feature, users can perform advanced searches and complex analyses using natural language queries without SQL or data analysis expertise. In this post, we discuss how non-technical users can use this tool to analyze and understand the documents they have processed at scale with natural language.
To address the need for businesses to quickly analyze information and unlock actionable insights, we are announcing Analytics Agent, a new feature that is seamlessly integrated into the GenAI IDP Accelerator. With this feature, users can perform advanced searches and complex analyses using natural language queries without SQL or data analysis expertise. In this post, we discuss how non-technical users can use this tool to analyze and understand the documents they have processed at scale with natural language. Read More

Build a multimodal generative AI assistant for root cause diagnosis in predictive maintenance using Amazon BedrockArtificial Intelligence In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare.
In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare. Read More