
Multimodal Fact-Checking: An Agent-based Approachcs.AI updates on arXiv.org arXiv:2512.22933v3 Announce Type: replace
Abstract: The rapid spread of multimodal misinformation poses a growing challenge for automated fact-checking systems. Existing approaches, including large vision language models (LVLMs) and deep multimodal fusion methods, often fall short due to limited reasoning and shallow evidence utilization. A key bottleneck is the lack of dedicated datasets that provide complete real-world multimodal misinformation instances accompanied by annotated reasoning processes and verifiable evidence. To address this limitation, we introduce RW-Post, a high-quality and explainable dataset for real-world multimodal fact-checking. RW-Post aligns real-world multimodal claims with their original social media posts, preserving the rich contextual information in which the claims are made. In addition, the dataset includes detailed reasoning and explicitly linked evidence, which are derived from human written fact-checking articles via a large language model assisted extraction pipeline, enabling comprehensive verification and explanation. Building upon RW-Post, we propose AgentFact, an agent-based multimodal fact-checking framework designed to emulate the human verification workflow. AgentFact consists of five specialized agents that collaboratively handle key fact-checking subtasks, including strategy planning, high-quality evidence retrieval, visual analysis, reasoning, and explanation generation. These agents are orchestrated through an iterative workflow that alternates between evidence searching and task-aware evidence filtering and reasoning, facilitating strategic decision-making and systematic evidence analysis. Extensive experimental results demonstrate that the synergy between RW-Post and AgentFact substantially improves both the accuracy and interpretability of multimodal fact-checking.
arXiv:2512.22933v3 Announce Type: replace
Abstract: The rapid spread of multimodal misinformation poses a growing challenge for automated fact-checking systems. Existing approaches, including large vision language models (LVLMs) and deep multimodal fusion methods, often fall short due to limited reasoning and shallow evidence utilization. A key bottleneck is the lack of dedicated datasets that provide complete real-world multimodal misinformation instances accompanied by annotated reasoning processes and verifiable evidence. To address this limitation, we introduce RW-Post, a high-quality and explainable dataset for real-world multimodal fact-checking. RW-Post aligns real-world multimodal claims with their original social media posts, preserving the rich contextual information in which the claims are made. In addition, the dataset includes detailed reasoning and explicitly linked evidence, which are derived from human written fact-checking articles via a large language model assisted extraction pipeline, enabling comprehensive verification and explanation. Building upon RW-Post, we propose AgentFact, an agent-based multimodal fact-checking framework designed to emulate the human verification workflow. AgentFact consists of five specialized agents that collaboratively handle key fact-checking subtasks, including strategy planning, high-quality evidence retrieval, visual analysis, reasoning, and explanation generation. These agents are orchestrated through an iterative workflow that alternates between evidence searching and task-aware evidence filtering and reasoning, facilitating strategic decision-making and systematic evidence analysis. Extensive experimental results demonstrate that the synergy between RW-Post and AgentFact substantially improves both the accuracy and interpretability of multimodal fact-checking. Read More
On the Representation of Pairwise Causal Background Knowledge and Its Applications in Causal Inferencecs.AI updates on arXiv.org arXiv:2207.05067v2 Announce Type: replace
Abstract: Pairwise causal background knowledge about the existence or absence of causal edges and paths is frequently encountered in observational studies. Such constraints allow the shared directed and undirected edges in the constrained subclass of Markov equivalent DAGs to be represented as a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and introduce a minimal representation of a causal MPDAG. Then, we give a unified representation for three types of pairwise causal background knowledge, including direct, ancestral and non-ancestral causal knowledge, by introducing a novel concept called direct causal clause (DCC). Using DCCs, we study the consistency and equivalence of pairwise causal background knowledge and show that any pairwise causal background knowledge set can be uniquely and equivalently decomposed into the causal MPDAG representing the refined Markov equivalence class and a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking consistency and equivalence, as well as for finding the decomposed MPDAG and the residual DCCs. Finally, with pairwise causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that pairwise causal background knowledge can significantly improve the identifiability of causal effects.
arXiv:2207.05067v2 Announce Type: replace
Abstract: Pairwise causal background knowledge about the existence or absence of causal edges and paths is frequently encountered in observational studies. Such constraints allow the shared directed and undirected edges in the constrained subclass of Markov equivalent DAGs to be represented as a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and introduce a minimal representation of a causal MPDAG. Then, we give a unified representation for three types of pairwise causal background knowledge, including direct, ancestral and non-ancestral causal knowledge, by introducing a novel concept called direct causal clause (DCC). Using DCCs, we study the consistency and equivalence of pairwise causal background knowledge and show that any pairwise causal background knowledge set can be uniquely and equivalently decomposed into the causal MPDAG representing the refined Markov equivalence class and a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking consistency and equivalence, as well as for finding the decomposed MPDAG and the residual DCCs. Finally, with pairwise causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that pairwise causal background knowledge can significantly improve the identifiability of causal effects. Read More
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space AI updates on arXiv.org
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Spacecs.AI updates on arXiv.org arXiv:2512.24617v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $textbf{decoupled $mu$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $textbf{+2.69$%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
arXiv:2512.24617v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $textbf{decoupled $mu$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $textbf{+2.69$%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs. Read More
A data-driven framework for team selection in Fantasy Premier Leaguecs.AI updates on arXiv.org arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy.
arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy. Read More
How to make Medical AI Systems safer? Simulating Vulnerabilities, and Threats in Multimodal Medical RAG Systemcs.AI updates on arXiv.org arXiv:2508.17215v2 Announce Type: replace-cross
Abstract: Large Vision-Language Models (LVLMs) augmented with Retrieval-Augmented Generation (RAG) are increasingly employed in medical AI to enhance factual grounding through external clinical image-text retrieval. However, this reliance creates a significant attack surface. We propose MedThreatRAG, a novel multimodal poisoning framework that systematically probes vulnerabilities in medical RAG systems by injecting adversarial image-text pairs. A key innovation of our approach is the construction of a simulated semi-open attack environment, mimicking real-world medical systems that permit periodic knowledge base updates via user or pipeline contributions. Within this setting, we introduce and emphasize Cross-Modal Conflict Injection (CMCI), which embeds subtle semantic contradictions between medical images and their paired reports. These mismatches degrade retrieval and generation by disrupting cross-modal alignment while remaining sufficiently plausible to evade conventional filters. While basic textual and visual attacks are included for completeness, CMCI demonstrates the most severe degradation. Evaluations on IU-Xray and MIMIC-CXR QA tasks show that MedThreatRAG reduces answer F1 scores by up to 27.66% and lowers LLaVA-Med-1.5 F1 rates to as low as 51.36%. Our findings expose fundamental security gaps in clinical RAG systems and highlight the urgent need for threat-aware design and robust multimodal consistency checks. Finally, we conclude with a concise set of guidelines to inform the safe development of future multimodal medical RAG systems.
arXiv:2508.17215v2 Announce Type: replace-cross
Abstract: Large Vision-Language Models (LVLMs) augmented with Retrieval-Augmented Generation (RAG) are increasingly employed in medical AI to enhance factual grounding through external clinical image-text retrieval. However, this reliance creates a significant attack surface. We propose MedThreatRAG, a novel multimodal poisoning framework that systematically probes vulnerabilities in medical RAG systems by injecting adversarial image-text pairs. A key innovation of our approach is the construction of a simulated semi-open attack environment, mimicking real-world medical systems that permit periodic knowledge base updates via user or pipeline contributions. Within this setting, we introduce and emphasize Cross-Modal Conflict Injection (CMCI), which embeds subtle semantic contradictions between medical images and their paired reports. These mismatches degrade retrieval and generation by disrupting cross-modal alignment while remaining sufficiently plausible to evade conventional filters. While basic textual and visual attacks are included for completeness, CMCI demonstrates the most severe degradation. Evaluations on IU-Xray and MIMIC-CXR QA tasks show that MedThreatRAG reduces answer F1 scores by up to 27.66% and lowers LLaVA-Med-1.5 F1 rates to as low as 51.36%. Our findings expose fundamental security gaps in clinical RAG systems and highlight the urgent need for threat-aware design and robust multimodal consistency checks. Finally, we conclude with a concise set of guidelines to inform the safe development of future multimodal medical RAG systems. Read More
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Expertscs.AI updates on arXiv.org arXiv:2601.02144v1 Announce Type: cross
Abstract: Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric “router” to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
arXiv:2601.02144v1 Announce Type: cross
Abstract: Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric “router” to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning. Read More
How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion LoopsMarkTechPost In this tutorial, we build a genuinely advanced Agentic AI system using LangGraph and OpenAI models by going beyond simple planner, executor loops. We implement adaptive deliberation, where the agent dynamically decides between fast and deep reasoning; a Zettelkasten-style agentic memory graph that stores atomic knowledge and automatically links related experiences; and a governed tool-use
The post How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion Loops appeared first on MarkTechPost.
In this tutorial, we build a genuinely advanced Agentic AI system using LangGraph and OpenAI models by going beyond simple planner, executor loops. We implement adaptive deliberation, where the agent dynamically decides between fast and deep reasoning; a Zettelkasten-style agentic memory graph that stores atomic knowledge and automatically links related experiences; and a governed tool-use
The post How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion Loops appeared first on MarkTechPost. Read More

The 10 AI Developments That Defined 2025KDnuggets In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026.
In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026. Read More
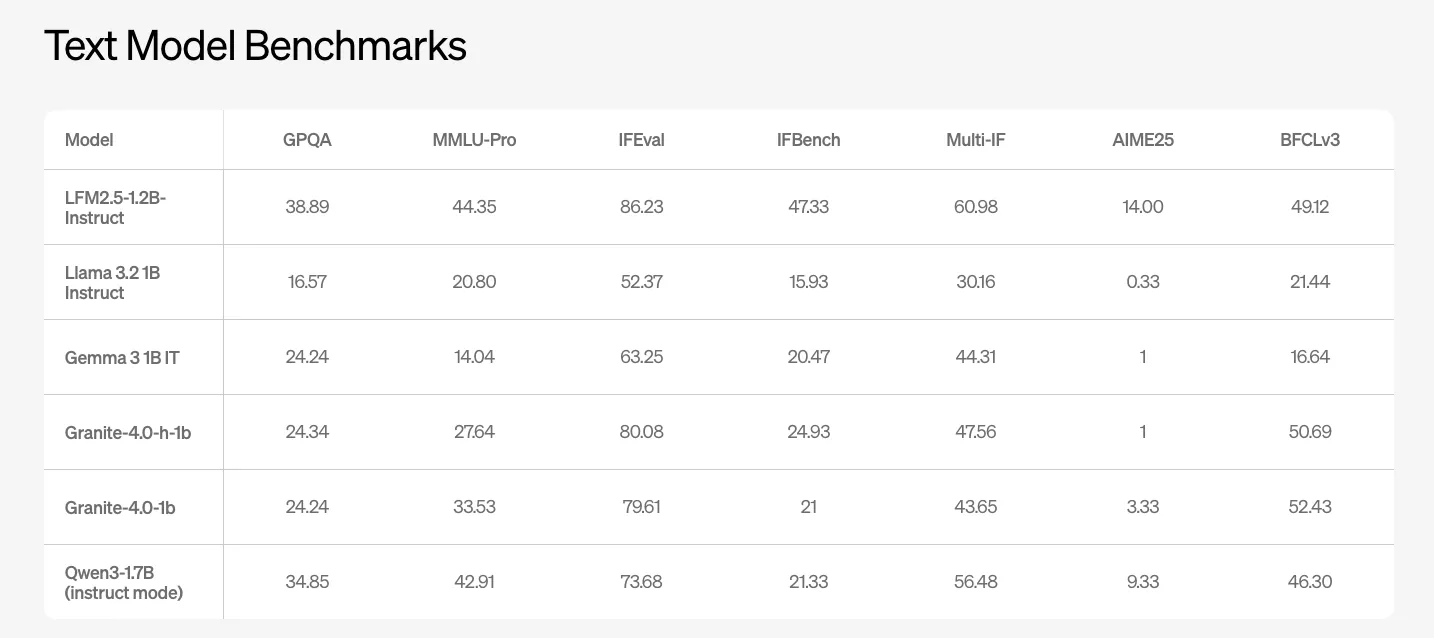
Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device AgentsMarkTechPost Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost.
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost. Read More
Measuring What Matters with NeMo Agent ToolkitTowards Data Science A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science.
A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science. Read More