
Efficient Sequential Recommendation for Long Term User Interest Via Personalizationcs.AI updates on arXiv.org arXiv:2601.03479v1 Announce Type: cross
Abstract: Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
arXiv:2601.03479v1 Announce Type: cross
Abstract: Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}. Read More
Bootstrapping Code Translation with Weighted Multilanguage Explorationcs.AI updates on arXiv.org arXiv:2601.03512v1 Announce Type: cross
Abstract: Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components.
arXiv:2601.03512v1 Announce Type: cross
Abstract: Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components. Read More
Microeconomic Foundations of Multi-Agent Learningcs.AI updates on arXiv.org arXiv:2601.03451v1 Announce Type: cross
Abstract: Modern AI systems increasingly operate inside markets and institutions where data, behavior, and incentives are endogenous. This paper develops an economic foundation for multi-agent learning by studying a principal-agent interaction in a Markov decision process with strategic externalities, where both the principal and the agent learn over time. We propose a two-phase incentive mechanism that first estimates implementable transfers and then uses them to steer long-run dynamics; under mild regret-based rationality and exploration conditions, the mechanism achieves sublinear social-welfare regret and thus asymptotically optimal welfare. Simulations illustrate how even coarse incentives can correct inefficient learning under stateful externalities, highlighting the necessity of incentive-aware design for safe and welfare-aligned AI in markets and insurance.
arXiv:2601.03451v1 Announce Type: cross
Abstract: Modern AI systems increasingly operate inside markets and institutions where data, behavior, and incentives are endogenous. This paper develops an economic foundation for multi-agent learning by studying a principal-agent interaction in a Markov decision process with strategic externalities, where both the principal and the agent learn over time. We propose a two-phase incentive mechanism that first estimates implementable transfers and then uses them to steer long-run dynamics; under mild regret-based rationality and exploration conditions, the mechanism achieves sublinear social-welfare regret and thus asymptotically optimal welfare. Simulations illustrate how even coarse incentives can correct inefficient learning under stateful externalities, highlighting the necessity of incentive-aware design for safe and welfare-aligned AI in markets and insurance. Read More
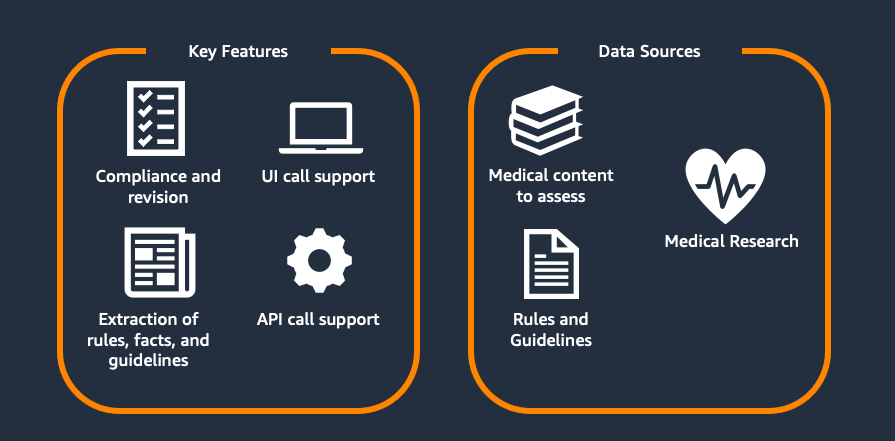
Scaling medical content review at Flo Health using Amazon Bedrock (Part 1)Artificial Intelligence This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.
This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale. Read More
Beyond Prompting: The Power of Context EngineeringTowards Data Science Using ACE to create self-improving LLM workflows and structured playbooks
The post Beyond Prompting: The Power of Context Engineering appeared first on Towards Data Science.
Using ACE to create self-improving LLM workflows and structured playbooks
The post Beyond Prompting: The Power of Context Engineering appeared first on Towards Data Science. Read More

Detect and redact personally identifiable information using Amazon Bedrock Data Automation and GuardrailsArtificial Intelligence This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability.
This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability. Read More
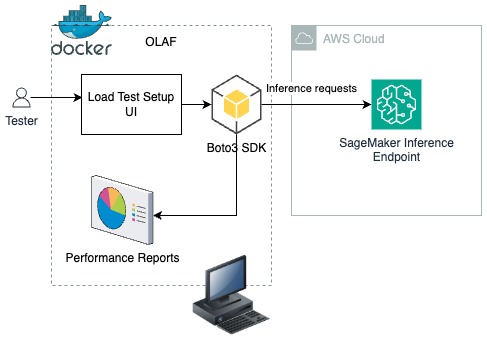
Speed meets scale: Load testing SageMakerAI endpoints with Observe.AI’s testing toolArtificial Intelligence Observe.ai developed the One Load Audit Framework (OLAF), which integrates with SageMaker to identify bottlenecks and performance issues in ML services, offering latency and throughput measurements under both static and dynamic data loads. In this blog post, you will learn how to use the OLAF utility to test and validate your SageMaker endpoint.
Observe.ai developed the One Load Audit Framework (OLAF), which integrates with SageMaker to identify bottlenecks and performance issues in ML services, offering latency and throughput measurements under both static and dynamic data loads. In this blog post, you will learn how to use the OLAF utility to test and validate your SageMaker endpoint. Read More
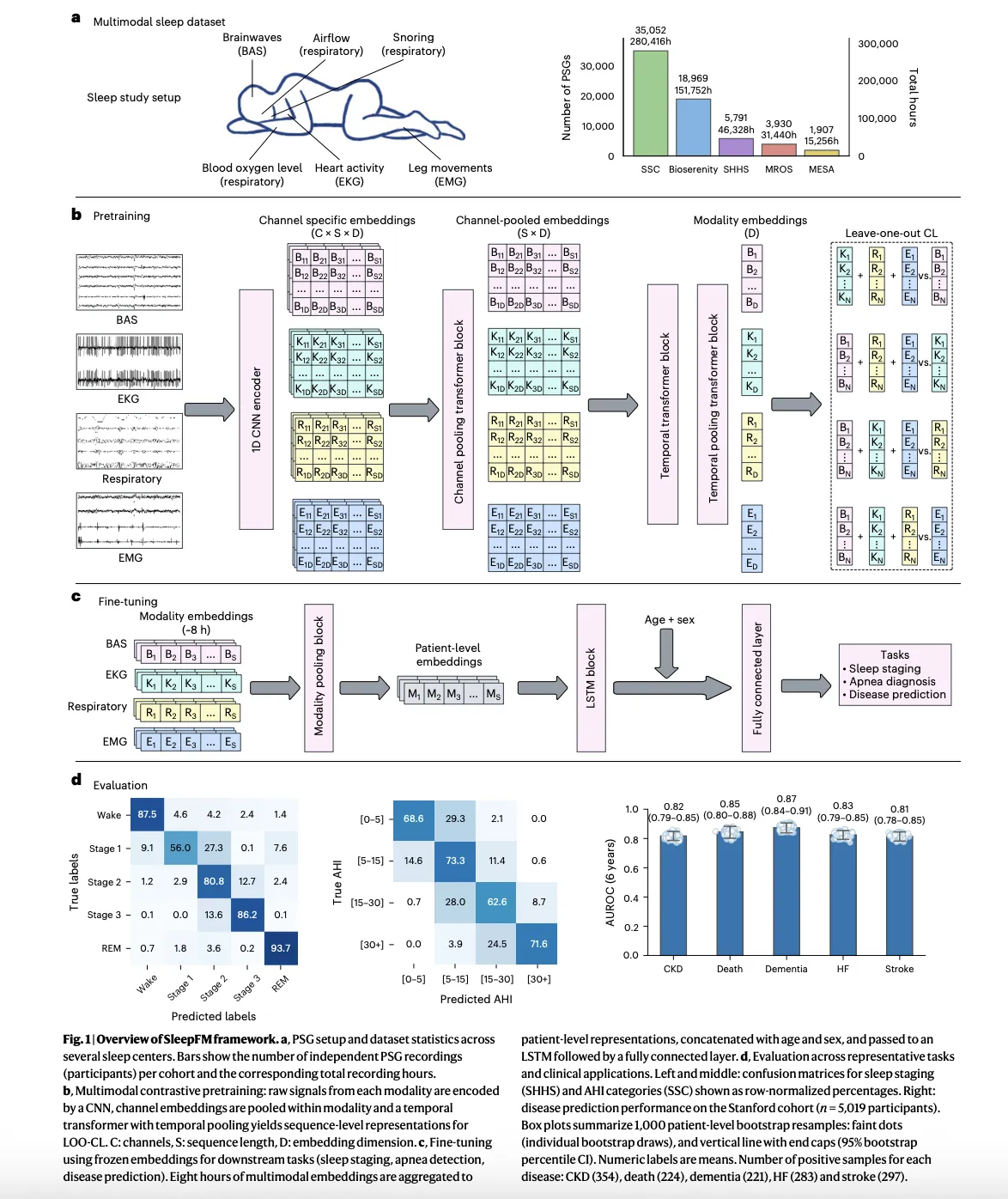
Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease PredictionMarkTechPost A team of Stanford Medicine researchers have introduced SleepFM Clinical, a multimodal sleep foundation model that learns from clinical polysomnography and predicts long term disease risk from a single night of sleep. The research work is published in Nature Medicine and the team has released the clinical code as the open source sleepfm-clinical repository on
The post Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease Prediction appeared first on MarkTechPost.
A team of Stanford Medicine researchers have introduced SleepFM Clinical, a multimodal sleep foundation model that learns from clinical polysomnography and predicts long term disease risk from a single night of sleep. The research work is published in Nature Medicine and the team has released the clinical code as the open source sleepfm-clinical repository on
The post Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease Prediction appeared first on MarkTechPost. Read More
Powerful Local AI Automations with n8n, MCP and OllamaKDnuggets The ultimate goal is to run these automations on a single workstation or small server, replacing fragile scripts and expensive API-based systems.
The ultimate goal is to run these automations on a single workstation or small server, replacing fragile scripts and expensive API-based systems. Read More
Retrieval for Time-Series: How Looking Back Improves ForecastsTowards Data Science Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science.
Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science. Read More