
Symbolic Planning and Multi-Agent Path Finding in Extremely Dense Environments with Unassigned Agentscs.AI updates on arXiv.org arXiv:2509.01022v2 Announce Type: replace
Abstract: We introduce the Block Rearrangement Problem (BRaP), a challenging component of large warehouse management which involves rearranging storage blocks within dense grids to achieve a goal state. We formally define the BRaP as a graph search problem. Building on intuitions from sliding puzzle problems, we propose five search-based solution algorithms, leveraging joint configuration space search, classical planning, multi-agent pathfinding, and expert heuristics. We evaluate the five approaches empirically for plan quality and scalability. Despite the exponential relation between search space size and block number, our methods demonstrate efficiency in creating rearrangement plans for deeply buried blocks in up to 80×80 grids.
arXiv:2509.01022v2 Announce Type: replace
Abstract: We introduce the Block Rearrangement Problem (BRaP), a challenging component of large warehouse management which involves rearranging storage blocks within dense grids to achieve a goal state. We formally define the BRaP as a graph search problem. Building on intuitions from sliding puzzle problems, we propose five search-based solution algorithms, leveraging joint configuration space search, classical planning, multi-agent pathfinding, and expert heuristics. We evaluate the five approaches empirically for plan quality and scalability. Despite the exponential relation between search space size and block number, our methods demonstrate efficiency in creating rearrangement plans for deeply buried blocks in up to 80×80 grids. Read More
SPAN: Benchmarking and Improving Cross-Calendar Temporal Reasoning of Large Language Modelscs.AI updates on arXiv.org arXiv:2511.09993v2 Announce Type: replace
Abstract: We introduce SPAN, a cross-calendar temporal reasoning benchmark, which requires LLMs to perform intra-calendar temporal reasoning and inter-calendar temporal conversion. SPAN features ten cross-calendar temporal reasoning directions, two reasoning types, and two question formats across six calendars. To enable time-variant and contamination-free evaluation, we propose a template-driven protocol for dynamic instance generation that enables assessment on a user-specified Gregorian date. We conduct extensive experiments on both open- and closed-source state-of-the-art (SOTA) LLMs over a range of dates spanning 100 years from 1960 to 2060. Our evaluations show that these LLMs achieve an average accuracy of only 34.5%, with none exceeding 80%, indicating that this task remains challenging. Through in-depth analysis of reasoning types, question formats, and temporal reasoning directions, we identify two key obstacles for LLMs: Future-Date Degradation and Calendar Asymmetry Bias. To strengthen LLMs’ cross-calendar temporal reasoning capability, we further develop an LLM-powered Time Agent that leverages tool-augmented code generation. Empirical results show that Time Agent achieves an average accuracy of 95.31%, outperforming several competitive baselines, highlighting the potential of tool-augmented code generation to advance cross-calendar temporal reasoning. We hope this work will inspire further efforts toward more temporally and culturally adaptive LLMs.
arXiv:2511.09993v2 Announce Type: replace
Abstract: We introduce SPAN, a cross-calendar temporal reasoning benchmark, which requires LLMs to perform intra-calendar temporal reasoning and inter-calendar temporal conversion. SPAN features ten cross-calendar temporal reasoning directions, two reasoning types, and two question formats across six calendars. To enable time-variant and contamination-free evaluation, we propose a template-driven protocol for dynamic instance generation that enables assessment on a user-specified Gregorian date. We conduct extensive experiments on both open- and closed-source state-of-the-art (SOTA) LLMs over a range of dates spanning 100 years from 1960 to 2060. Our evaluations show that these LLMs achieve an average accuracy of only 34.5%, with none exceeding 80%, indicating that this task remains challenging. Through in-depth analysis of reasoning types, question formats, and temporal reasoning directions, we identify two key obstacles for LLMs: Future-Date Degradation and Calendar Asymmetry Bias. To strengthen LLMs’ cross-calendar temporal reasoning capability, we further develop an LLM-powered Time Agent that leverages tool-augmented code generation. Empirical results show that Time Agent achieves an average accuracy of 95.31%, outperforming several competitive baselines, highlighting the potential of tool-augmented code generation to advance cross-calendar temporal reasoning. We hope this work will inspire further efforts toward more temporally and culturally adaptive LLMs. Read More
A Coding Guide to Demonstrate Targeted Data Poisoning Attacks in Deep Learning by Label Flipping on CIFAR-10 with PyTorchMarkTechPost In this tutorial, we demonstrate a realistic data poisoning attack by manipulating labels in the CIFAR-10 dataset and observing its impact on model behavior. We construct a clean and a poisoned training pipeline side by side, using a ResNet-style convolutional network to ensure stable, comparable learning dynamics. By selectively flipping a fraction of samples from
The post A Coding Guide to Demonstrate Targeted Data Poisoning Attacks in Deep Learning by Label Flipping on CIFAR-10 with PyTorch appeared first on MarkTechPost.
In this tutorial, we demonstrate a realistic data poisoning attack by manipulating labels in the CIFAR-10 dataset and observing its impact on model behavior. We construct a clean and a poisoned training pipeline side by side, using a ResNet-style convolutional network to ensure stable, comparable learning dynamics. By selectively flipping a fraction of samples from
The post A Coding Guide to Demonstrate Targeted Data Poisoning Attacks in Deep Learning by Label Flipping on CIFAR-10 with PyTorch appeared first on MarkTechPost. Read More
Meet SETA: Open Source Training Reinforcement Learning Environments for Terminal Agents with 400 Tasks and CAMEL ToolkitMarkTechPost What does an end to end stack for terminal agents look like when you combine structured toolkits, synthetic RL environments, and benchmark aligned evaluation? A team of researchers from CAMEL AI, Eigent AI and other collaborators have released SETA, a toolkit and environment stack that focuses on reinforcement learning for terminal agents. The project targets
The post Meet SETA: Open Source Training Reinforcement Learning Environments for Terminal Agents with 400 Tasks and CAMEL Toolkit appeared first on MarkTechPost.
What does an end to end stack for terminal agents look like when you combine structured toolkits, synthetic RL environments, and benchmark aligned evaluation? A team of researchers from CAMEL AI, Eigent AI and other collaborators have released SETA, a toolkit and environment stack that focuses on reinforcement learning for terminal agents. The project targets
The post Meet SETA: Open Source Training Reinforcement Learning Environments for Terminal Agents with 400 Tasks and CAMEL Toolkit appeared first on MarkTechPost. Read More
Automatic Prompt Optimization for Multimodal Vision Agents: A Self-Driving Car ExampleTowards Data Science Walkthrough using open-source prompt optimization algorithms in Python to improve the accuracy of an autonomous vehicle car safety agent running on OpenAI’s GPT 5.2
The post Automatic Prompt Optimization for Multimodal Vision Agents: A Self-Driving Car Example appeared first on Towards Data Science.
Walkthrough using open-source prompt optimization algorithms in Python to improve the accuracy of an autonomous vehicle car safety agent running on OpenAI’s GPT 5.2
The post Automatic Prompt Optimization for Multimodal Vision Agents: A Self-Driving Car Example appeared first on Towards Data Science. Read More
Beyond the Flat Table: Building an Enterprise-Grade Financial Model in Power BI Towards Data Science
Beyond the Flat Table: Building an Enterprise-Grade Financial Model in Power BITowards Data Science A step-by-step journey through data transformation, star schema modeling, and DAX variance analysis with lessons learned along the way.
The post Beyond the Flat Table: Building an Enterprise-Grade Financial Model in Power BI appeared first on Towards Data Science.
A step-by-step journey through data transformation, star schema modeling, and DAX variance analysis with lessons learned along the way.
The post Beyond the Flat Table: Building an Enterprise-Grade Financial Model in Power BI appeared first on Towards Data Science. Read More
How to Leverage Slash Commands to Code EffectivelyTowards Data Science Learn how I utilize slash commands to be a more efficient engineer
The post How to Leverage Slash Commands to Code Effectively appeared first on Towards Data Science.
Learn how I utilize slash commands to be a more efficient engineer
The post How to Leverage Slash Commands to Code Effectively appeared first on Towards Data Science. Read More
Federated Learning, Part 1: The Basics of Training Models Where the Data LivesTowards Data Science Understanding the foundations of federated learning
The post Federated Learning, Part 1: The Basics of Training Models Where the Data Lives appeared first on Towards Data Science.
Understanding the foundations of federated learning
The post Federated Learning, Part 1: The Basics of Training Models Where the Data Lives appeared first on Towards Data Science. Read More
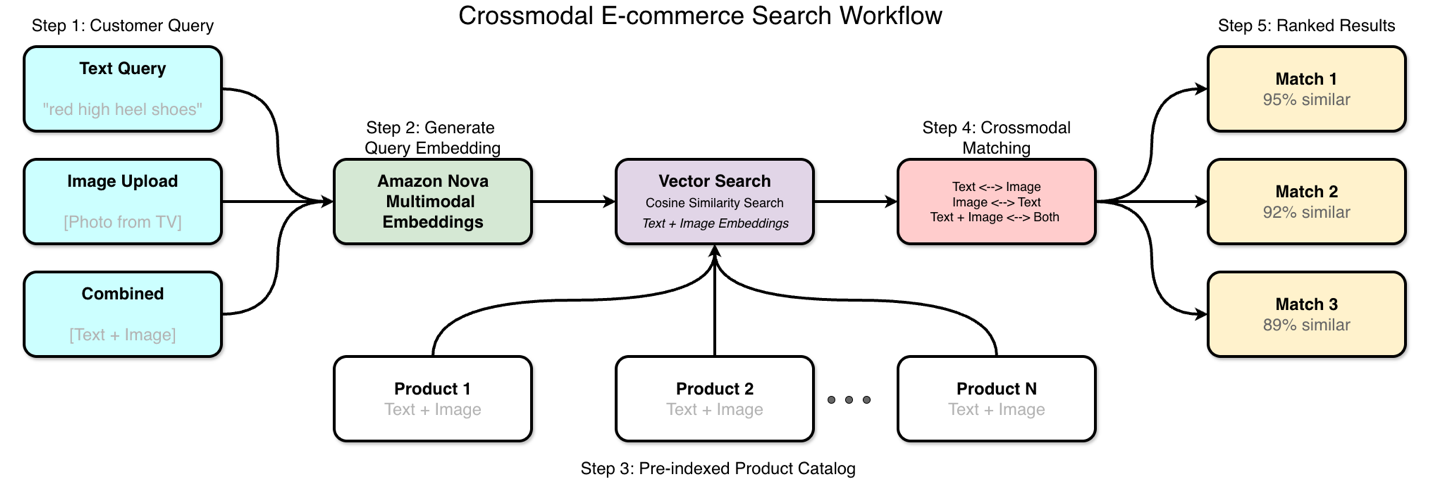
Crossmodal search with Amazon Nova Multimodal EmbeddingsArtificial Intelligence In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications.
In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications. Read More
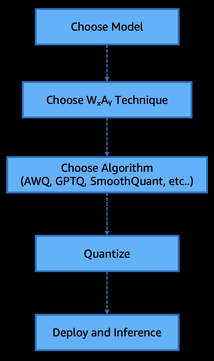
Accelerating LLM inference with post-training weight and activation using AWQ and GPTQ on Amazon SageMaker AIArtificial Intelligence Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker.
Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker. Read More