
AutoContext: Instance-Level Context Learning for LLM Agentscs.AI updates on arXiv.org arXiv:2510.02369v3 Announce Type: replace-cross
Abstract: Current LLM agents typically lack instance-level context, which comprises concrete facts such as environment structure, system configurations, and local mechanics. Consequently, existing methods are forced to intertwine exploration with task execution. This coupling leads to redundant interactions and fragile decision-making, as agents must repeatedly rediscover the same information for every new task. To address this, we introduce AutoContext, a method that decouples exploration from task solving. AutoContext performs a systematic, one-off exploration to construct a reusable knowledge graph for each environment instance. This structured context allows off-the-shelf agents to access necessary facts directly, eliminating redundant exploration. Experiments across TextWorld, ALFWorld, Crafter, and InterCode-Bash demonstrate substantial gains: for example, the success rate of a ReAct agent on TextWorld improves from 37% to 95%, highlighting the critical role of structured instance context in efficient agentic systems.
arXiv:2510.02369v3 Announce Type: replace-cross
Abstract: Current LLM agents typically lack instance-level context, which comprises concrete facts such as environment structure, system configurations, and local mechanics. Consequently, existing methods are forced to intertwine exploration with task execution. This coupling leads to redundant interactions and fragile decision-making, as agents must repeatedly rediscover the same information for every new task. To address this, we introduce AutoContext, a method that decouples exploration from task solving. AutoContext performs a systematic, one-off exploration to construct a reusable knowledge graph for each environment instance. This structured context allows off-the-shelf agents to access necessary facts directly, eliminating redundant exploration. Experiments across TextWorld, ALFWorld, Crafter, and InterCode-Bash demonstrate substantial gains: for example, the success rate of a ReAct agent on TextWorld improves from 37% to 95%, highlighting the critical role of structured instance context in efficient agentic systems. Read More
Glitches in the Attention MatrixTowards Data Science A history of Transformer artifacts and the latest research on how to fix them
The post Glitches in the Attention Matrix appeared first on Towards Data Science.
A history of Transformer artifacts and the latest research on how to fix them
The post Glitches in the Attention Matrix appeared first on Towards Data Science. Read More

Research shows UK young adults would use AI for financial guidanceAI News Research from Cleo AI indicates that young adults are turning to artificial intelligence for financial advice to help them manage their money and develop more sustainable financial habits. The study surveyed 5,000 UK adults aged 28 to 40 and found that the majority are saving significantly less than they would like. In this context, interest
The post Research shows UK young adults would use AI for financial guidance appeared first on AI News.
Research from Cleo AI indicates that young adults are turning to artificial intelligence for financial advice to help them manage their money and develop more sustainable financial habits. The study surveyed 5,000 UK adults aged 28 to 40 and found that the majority are saving significantly less than they would like. In this context, interest
The post Research shows UK young adults would use AI for financial guidance appeared first on AI News. Read More
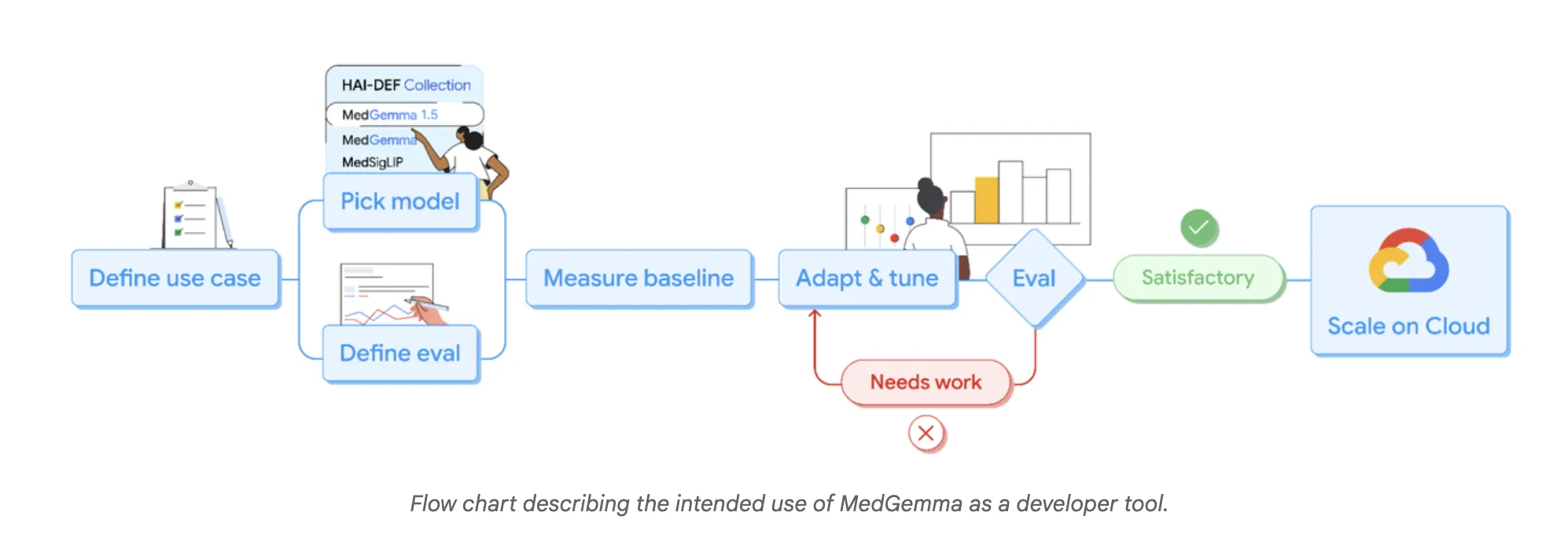
Google AI Releases MedGemma-1.5: The Latest Update to their Open Medical AI Models for DevelopersMarkTechPost Google Research has expanded its Health AI Developer Foundations program (HAI-DEF) with the release of MedGemma-1.5. The model is released as open starting points for developers who want to build medical imaging, text and speech systems and then adapt them to local workflows and regulations. MedGemma 1.5, small multimodal model for real clinical data MedGemma
The post Google AI Releases MedGemma-1.5: The Latest Update to their Open Medical AI Models for Developers appeared first on MarkTechPost.
Google Research has expanded its Health AI Developer Foundations program (HAI-DEF) with the release of MedGemma-1.5. The model is released as open starting points for developers who want to build medical imaging, text and speech systems and then adapt them to local workflows and regulations. MedGemma 1.5, small multimodal model for real clinical data MedGemma
The post Google AI Releases MedGemma-1.5: The Latest Update to their Open Medical AI Models for Developers appeared first on MarkTechPost. Read More
How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using GarakMarkTechPost In this tutorial, we build an advanced, multi-turn crescendo-style red-teaming harness using Garak to evaluate how large language models behave under gradual conversational pressure. We implement a custom iterative probe and a lightweight detector to simulate realistic escalation patterns in which benign prompts slowly pivot toward sensitive requests, and we assess whether the model maintains
The post How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using Garak appeared first on MarkTechPost.
In this tutorial, we build an advanced, multi-turn crescendo-style red-teaming harness using Garak to evaluate how large language models behave under gradual conversational pressure. We implement a custom iterative probe and a lightweight detector to simulate realistic escalation patterns in which benign prompts slowly pivot toward sensitive requests, and we assess whether the model maintains
The post How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using Garak appeared first on MarkTechPost. Read More
This AI spots dangerous blood cells doctors often missArtificial Intelligence News — ScienceDaily A generative AI system can now analyze blood cells with greater accuracy and confidence than human experts, detecting subtle signs of diseases like leukemia. It not only spots rare abnormalities but also recognizes its own uncertainty, making it a powerful support tool for clinicians.
A generative AI system can now analyze blood cells with greater accuracy and confidence than human experts, detecting subtle signs of diseases like leukemia. It not only spots rare abnormalities but also recognizes its own uncertainty, making it a powerful support tool for clinicians. Read More

Allister Frost: Tackling workforce anxiety for AI integration successAI News Navigating workforce anxiety remains a primary challenge for leaders as AI integration defines modern enterprise success. For enterprise leaders, deploying AI is less a technical hurdle than a complex exercise in change management. The reality for many organisations is that, while algorithms offer efficiency, the human element dictates the speed of adoption. Data from the
The post Allister Frost: Tackling workforce anxiety for AI integration success appeared first on AI News.
Navigating workforce anxiety remains a primary challenge for leaders as AI integration defines modern enterprise success. For enterprise leaders, deploying AI is less a technical hurdle than a complex exercise in change management. The reality for many organisations is that, while algorithms offer efficiency, the human element dictates the speed of adoption. Data from the
The post Allister Frost: Tackling workforce anxiety for AI integration success appeared first on AI News. Read More
Why Your ML Model Works in Training But Fails in ProductionTowards Data Science Hard lessons from building production ML systems where data leaks, defaults lie, populations shift, and time does not behave the way we expect.
The post Why Your ML Model Works in Training But Fails in Production appeared first on Towards Data Science.
Hard lessons from building production ML systems where data leaks, defaults lie, populations shift, and time does not behave the way we expect.
The post Why Your ML Model Works in Training But Fails in Production appeared first on Towards Data Science. Read More

5 Useful Python Scripts for Effective Feature EngineeringKDnuggets Feature engineering doesn’t have to be complex. These 5 Python scripts help you create meaningful features that improve model performance.
Feature engineering doesn’t have to be complex. These 5 Python scripts help you create meaningful features that improve model performance. Read More

Securing Amazon Bedrock cross-Region inference: Geographic and globalArtificial Intelligence In this post, we explore the security considerations and best practices for implementing Amazon Bedrock cross-Region inference profiles. Whether you’re building a generative AI application or need to meet specific regional compliance requirements, this guide will help you understand the secure architecture of Amazon Bedrock CRIS and how to properly configure your implementation.
In this post, we explore the security considerations and best practices for implementing Amazon Bedrock cross-Region inference profiles. Whether you’re building a generative AI application or need to meet specific regional compliance requirements, this guide will help you understand the secure architecture of Amazon Bedrock CRIS and how to properly configure your implementation. Read More