
Cold snap highlight’s airlines’ proactive use of AIAI News The severe weather experienced at present in the US has placed significant strain on the airline industry in the country, with knock-on effects of changes to schedules and routes affecting the rest of the world. It’s at times like this that companies have to respond to queries from customers at a much greater rate than
The post Cold snap highlight’s airlines’ proactive use of AI appeared first on AI News.
The severe weather experienced at present in the US has placed significant strain on the airline industry in the country, with knock-on effects of changes to schedules and routes affecting the rest of the world. It’s at times like this that companies have to respond to queries from customers at a much greater rate than
The post Cold snap highlight’s airlines’ proactive use of AI appeared first on AI News. Read More

Layered Architecture for Building Readable, Robust, and Extensible AppsTowards Data Science If adding a feature feels like open-heart surgery on your codebase, the problem isn’t bugs, it’s structure. This article shows how better architecture reduces risk, speeds up change, and keeps teams moving.
The post Layered Architecture for Building Readable, Robust, and Extensible Apps appeared first on Towards Data Science.
If adding a feature feels like open-heart surgery on your codebase, the problem isn’t bugs, it’s structure. This article shows how better architecture reduces risk, speeds up change, and keeps teams moving.
The post Layered Architecture for Building Readable, Robust, and Extensible Apps appeared first on Towards Data Science. Read More

Lowering the barriers databases place in the way of strategy, with RavenDBAI News If database technologies offered performance, flexibility and security, most professionals would be happy to get two of the three, and they might have to expect to accept some compromises, too. Systems optimised for speed demand manual tuning, while flexible platforms can impose costs when early designs become constraints. Security is, sadly, sometimes, a bolt-on, with
The post Lowering the barriers databases place in the way of strategy, with RavenDB appeared first on AI News.
If database technologies offered performance, flexibility and security, most professionals would be happy to get two of the three, and they might have to expect to accept some compromises, too. Systems optimised for speed demand manual tuning, while flexible platforms can impose costs when early designs become constraints. Security is, sadly, sometimes, a bolt-on, with
The post Lowering the barriers databases place in the way of strategy, with RavenDB appeared first on AI News. Read More
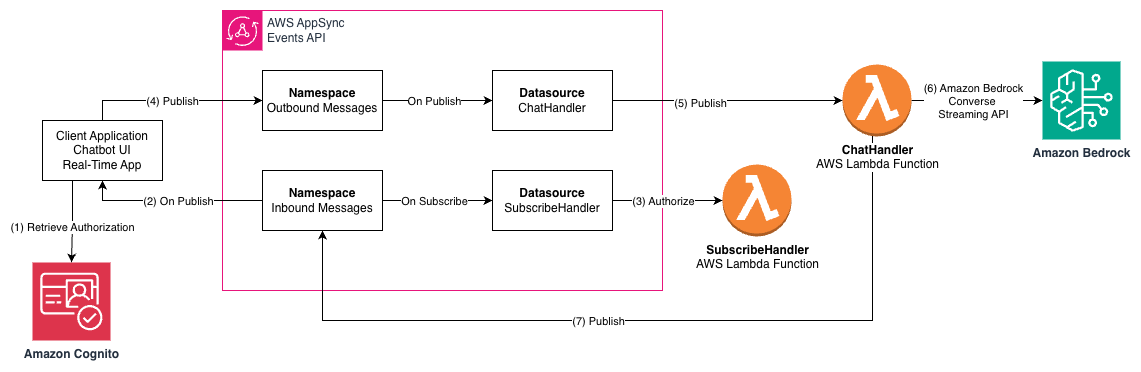
Build a serverless AI Gateway architecture with AWS AppSync EventsArtificial Intelligence In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.
In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building. Read More

5 Useful DIY Python Functions for Parsing Dates and TimesKDnuggets Dates and times shouldn’t break your code, but they often do. These five DIY Python functions help turn real-world dates and times into clean, usable data.
Dates and times shouldn’t break your code, but they often do. These five DIY Python functions help turn real-world dates and times into clean, usable data. Read More
How Convolutional Neural Networks Learn Musical SimilarityTowards Data Science Learning audio embeddings with contrastive learning and deploying them in a real music recommendation app
The post How Convolutional Neural Networks Learn Musical Similarity appeared first on Towards Data Science.
Learning audio embeddings with contrastive learning and deploying them in a real music recommendation app
The post How Convolutional Neural Networks Learn Musical Similarity appeared first on Towards Data Science. Read More
Ray: Distributed Computing For All, Part 2Towards Data Science Deploying and running Python code on cloud-based clusters
The post Ray: Distributed Computing For All, Part 2 appeared first on Towards Data Science.
Deploying and running Python code on cloud-based clusters
The post Ray: Distributed Computing For All, Part 2 appeared first on Towards Data Science. Read More

How Formula E uses Google Cloud AI to meet net zero targetsAI News Formula E is using Google Cloud AI to meet its net zero targets by driving efficiency across its global logistics and commercial operations. As part of an expanded multi-year agreement, the electric racing series will integrate Gemini models into its ecosystem to support performance analysis, back-office workflows, and event logistics. The collaboration demonstrates how sports
The post How Formula E uses Google Cloud AI to meet net zero targets appeared first on AI News.
Formula E is using Google Cloud AI to meet its net zero targets by driving efficiency across its global logistics and commercial operations. As part of an expanded multi-year agreement, the electric racing series will integrate Gemini models into its ecosystem to support performance analysis, back-office workflows, and event logistics. The collaboration demonstrates how sports
The post How Formula E uses Google Cloud AI to meet net zero targets appeared first on AI News. Read More

The KDnuggets ComfyUI Crash CourseKDnuggets This crash course will take you from a complete beginner to a confident ComfyUI user, walking you through every essential concept, feature, and practical example you need to master this powerful tool.
This crash course will take you from a complete beginner to a confident ComfyUI user, walking you through every essential concept, feature, and practical example you need to master this powerful tool. Read More
Retailers examine options for on-AI retailAI News Big retailers are committing more heavily to agentic AI-led commerce, and accepting some loss of customer proximity and data control in the process. As reported by Retail Dive, the opening weeks of 2026 have seen Etsy, Target and Walmart push product ranges onto third-party AI platforms, forming new partnerships with Google’s Gemini and Microsoft’s Copilot,
The post Retailers examine options for on-AI retail appeared first on AI News.
Big retailers are committing more heavily to agentic AI-led commerce, and accepting some loss of customer proximity and data control in the process. As reported by Retail Dive, the opening weeks of 2026 have seen Etsy, Target and Walmart push product ranges onto third-party AI platforms, forming new partnerships with Google’s Gemini and Microsoft’s Copilot,
The post Retailers examine options for on-AI retail appeared first on AI News. Read More