
Closing the Data-Efficiency Gap Between Autoregressive and Masked Diffusion LLMscs.AI updates on arXiv.org arXiv:2510.09885v3 Announce Type: replace-cross
Abstract: Large language models (LLMs) are often used in environments where facts evolve, yet factual knowledge updates via fine-tuning on unstructured text often suffers from 1) reliance on compute-heavy paraphrase augmentation and 2) the reversal curse. Recent studies show diffusion large language models (dLLMs) require fewer training samples to achieve lower loss in pre-training and are more resistant to the reversal curse, suggesting dLLMs may learn new knowledge more easily than autoregressive LLMs (arLLMs). We test this hypothesis in controlled knowledge fine-tuning experiments and find that while arLLMs rely on paraphrase augmentation to generalize knowledge text into question-answering (QA) capability, dLLMs do not require paraphrases to achieve high QA accuracy. To further investigate whether the demasking objective alone can induce such a knowledge injection advantage in dLLMs regardless of their diffusion denoising paradigm, we propose masked fine-tuning for arLLMs, which prompts an arLLM to reconstruct the original text given a masked version in context. The masked fine-tuning for arLLMs substantially improves the efficacy of knowledge injection, i.e. no paraphrase needed and resistant to the reversal curse, closing the gap between arLLMs and dLLMs. We also demonstrate that the same demasking objective improves supervised fine-tuning (SFT) on math tasks over standard SFT, suggesting broader applicability of the demasking objective.
arXiv:2510.09885v3 Announce Type: replace-cross
Abstract: Large language models (LLMs) are often used in environments where facts evolve, yet factual knowledge updates via fine-tuning on unstructured text often suffers from 1) reliance on compute-heavy paraphrase augmentation and 2) the reversal curse. Recent studies show diffusion large language models (dLLMs) require fewer training samples to achieve lower loss in pre-training and are more resistant to the reversal curse, suggesting dLLMs may learn new knowledge more easily than autoregressive LLMs (arLLMs). We test this hypothesis in controlled knowledge fine-tuning experiments and find that while arLLMs rely on paraphrase augmentation to generalize knowledge text into question-answering (QA) capability, dLLMs do not require paraphrases to achieve high QA accuracy. To further investigate whether the demasking objective alone can induce such a knowledge injection advantage in dLLMs regardless of their diffusion denoising paradigm, we propose masked fine-tuning for arLLMs, which prompts an arLLM to reconstruct the original text given a masked version in context. The masked fine-tuning for arLLMs substantially improves the efficacy of knowledge injection, i.e. no paraphrase needed and resistant to the reversal curse, closing the gap between arLLMs and dLLMs. We also demonstrate that the same demasking objective improves supervised fine-tuning (SFT) on math tasks over standard SFT, suggesting broader applicability of the demasking objective. Read More
Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformerscs.AI updates on arXiv.org arXiv:2601.17367v2 Announce Type: replace-cross
Abstract: The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for large language models (LLMs) in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method.
arXiv:2601.17367v2 Announce Type: replace-cross
Abstract: The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for large language models (LLMs) in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method. Read More
Diffusion Generative Recommendation with Continuous Tokenscs.AI updates on arXiv.org arXiv:2504.12007v4 Announce Type: replace-cross
Abstract: Recent advances in generative artificial intelligence, particularly large language models (LLMs), have opened new opportunities for enhancing recommender systems (RecSys). Most existing LLM-based RecSys approaches operate in a discrete space, using vector-quantized tokenizers to align with the inherent discrete nature of language models. However, these quantization methods often result in lossy tokenization and suboptimal learning, primarily due to inaccurate gradient propagation caused by the non-differentiable argmin operation in standard vector quantization. Inspired by the emerging trend of embracing continuous tokens in language models, we propose ContRec, a novel framework that seamlessly integrates continuous tokens into LLM-based RecSys. Specifically, ContRec consists of two key modules: a sigma-VAE Tokenizer, which encodes users/items with continuous tokens; and a Dispersive Diffusion module, which captures implicit user preference. The tokenizer is trained with a continuous Variational Auto-Encoder (VAE) objective, where three effective techniques are adopted to avoid representation collapse. By conditioning on the previously generated tokens of the LLM backbone during user modeling, the Dispersive Diffusion module performs a conditional diffusion process with a novel Dispersive Loss, enabling high-quality user preference generation through next-token diffusion. Finally, ContRec leverages both the textual reasoning output from the LLM and the latent representations produced by the diffusion model for Top-K item retrieval, thereby delivering comprehensive recommendation results. Extensive experiments on four datasets demonstrate that ContRec consistently outperforms both traditional and SOTA LLM-based recommender systems. Our results highlight the potential of continuous tokenization and generative modeling for advancing the next generation of recommender systems.
arXiv:2504.12007v4 Announce Type: replace-cross
Abstract: Recent advances in generative artificial intelligence, particularly large language models (LLMs), have opened new opportunities for enhancing recommender systems (RecSys). Most existing LLM-based RecSys approaches operate in a discrete space, using vector-quantized tokenizers to align with the inherent discrete nature of language models. However, these quantization methods often result in lossy tokenization and suboptimal learning, primarily due to inaccurate gradient propagation caused by the non-differentiable argmin operation in standard vector quantization. Inspired by the emerging trend of embracing continuous tokens in language models, we propose ContRec, a novel framework that seamlessly integrates continuous tokens into LLM-based RecSys. Specifically, ContRec consists of two key modules: a sigma-VAE Tokenizer, which encodes users/items with continuous tokens; and a Dispersive Diffusion module, which captures implicit user preference. The tokenizer is trained with a continuous Variational Auto-Encoder (VAE) objective, where three effective techniques are adopted to avoid representation collapse. By conditioning on the previously generated tokens of the LLM backbone during user modeling, the Dispersive Diffusion module performs a conditional diffusion process with a novel Dispersive Loss, enabling high-quality user preference generation through next-token diffusion. Finally, ContRec leverages both the textual reasoning output from the LLM and the latent representations produced by the diffusion model for Top-K item retrieval, thereby delivering comprehensive recommendation results. Extensive experiments on four datasets demonstrate that ContRec consistently outperforms both traditional and SOTA LLM-based recommender systems. Our results highlight the potential of continuous tokenization and generative modeling for advancing the next generation of recommender systems. Read More
ECG-Agent: On-Device Tool-Calling Agent for ECG Multi-Turn Dialoguecs.AI updates on arXiv.org arXiv:2601.20323v1 Announce Type: new
Abstract: Recent advances in Multimodal Large Language Models have rapidly expanded to electrocardiograms, focusing on classification, report generation, and single-turn QA tasks. However, these models fall short in real-world scenarios, lacking multi-turn conversational ability, on-device efficiency, and precise understanding of ECG measurements such as the PQRST intervals. To address these limitations, we introduce ECG-Agent, the first LLM-based tool-calling agent for multi-turn ECG dialogue. To facilitate its development and evaluation, we also present ECG-Multi-Turn-Dialogue (ECG-MTD) dataset, a collection of realistic user-assistant multi-turn dialogues for diverse ECG lead configurations. We develop ECG-Agents in various sizes, from on-device capable to larger agents. Experimental results show that ECG-Agents outperform baseline ECG-LLMs in response accuracy. Furthermore, on-device agents achieve comparable performance to larger agents in various evaluations that assess response accuracy, tool-calling ability, and hallucinations, demonstrating their viability for real-world applications.
arXiv:2601.20323v1 Announce Type: new
Abstract: Recent advances in Multimodal Large Language Models have rapidly expanded to electrocardiograms, focusing on classification, report generation, and single-turn QA tasks. However, these models fall short in real-world scenarios, lacking multi-turn conversational ability, on-device efficiency, and precise understanding of ECG measurements such as the PQRST intervals. To address these limitations, we introduce ECG-Agent, the first LLM-based tool-calling agent for multi-turn ECG dialogue. To facilitate its development and evaluation, we also present ECG-Multi-Turn-Dialogue (ECG-MTD) dataset, a collection of realistic user-assistant multi-turn dialogues for diverse ECG lead configurations. We develop ECG-Agents in various sizes, from on-device capable to larger agents. Experimental results show that ECG-Agents outperform baseline ECG-LLMs in response accuracy. Furthermore, on-device agents achieve comparable performance to larger agents in various evaluations that assess response accuracy, tool-calling ability, and hallucinations, demonstrating their viability for real-world applications. Read More
Reward Models Inherit Value Biases from Pretrainingcs.AI updates on arXiv.org arXiv:2601.20838v1 Announce Type: cross
Abstract: Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the “Big Two” psychological axes, we show a robust preference of Llama RMs for “agency” and a corresponding robust preference of Gemma RMs for “communion.” This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers’ choice of base model is as much a consideration of values as of performance.
arXiv:2601.20838v1 Announce Type: cross
Abstract: Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the “Big Two” psychological axes, we show a robust preference of Llama RMs for “agency” and a corresponding robust preference of Gemma RMs for “communion.” This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers’ choice of base model is as much a consideration of values as of performance. Read More
NoWag: A Unified Framework for Shape Preserving Compression of Large Language Modelscs.AI updates on arXiv.org arXiv:2504.14569v5 Announce Type: replace-cross
Abstract: Large language models (LLMs) exhibit remarkable performance across various natural language processing tasks but suffer from immense computational and memory demands, limiting their deployment in resource-constrained environments. To address this challenge, we propose NoWag (Normalized Weight and Activation Guided Compression), a unified framework for one-shot shape preserving compression algorithms. We apply NoWag to compress Llama-2 (7B, 13B, 70B) and Llama-3 (8B, 70B) models using two popular shape-preserving techniques: vector quantization (NoWag-VQ) and unstructured/semi-structured pruning (NoWag-P). Our results show that NoWag-VQ significantly outperforms state-of-the-art one-shot vector quantization methods, while NoWag-P performs competitively against leading pruning techniques. These findings highlight underlying commonalities between these compression paradigms and suggest promising directions for future research. Our code is available at https://github.com/LawrenceRLiu/NoWag
arXiv:2504.14569v5 Announce Type: replace-cross
Abstract: Large language models (LLMs) exhibit remarkable performance across various natural language processing tasks but suffer from immense computational and memory demands, limiting their deployment in resource-constrained environments. To address this challenge, we propose NoWag (Normalized Weight and Activation Guided Compression), a unified framework for one-shot shape preserving compression algorithms. We apply NoWag to compress Llama-2 (7B, 13B, 70B) and Llama-3 (8B, 70B) models using two popular shape-preserving techniques: vector quantization (NoWag-VQ) and unstructured/semi-structured pruning (NoWag-P). Our results show that NoWag-VQ significantly outperforms state-of-the-art one-shot vector quantization methods, while NoWag-P performs competitively against leading pruning techniques. These findings highlight underlying commonalities between these compression paradigms and suggest promising directions for future research. Our code is available at https://github.com/LawrenceRLiu/NoWag Read More
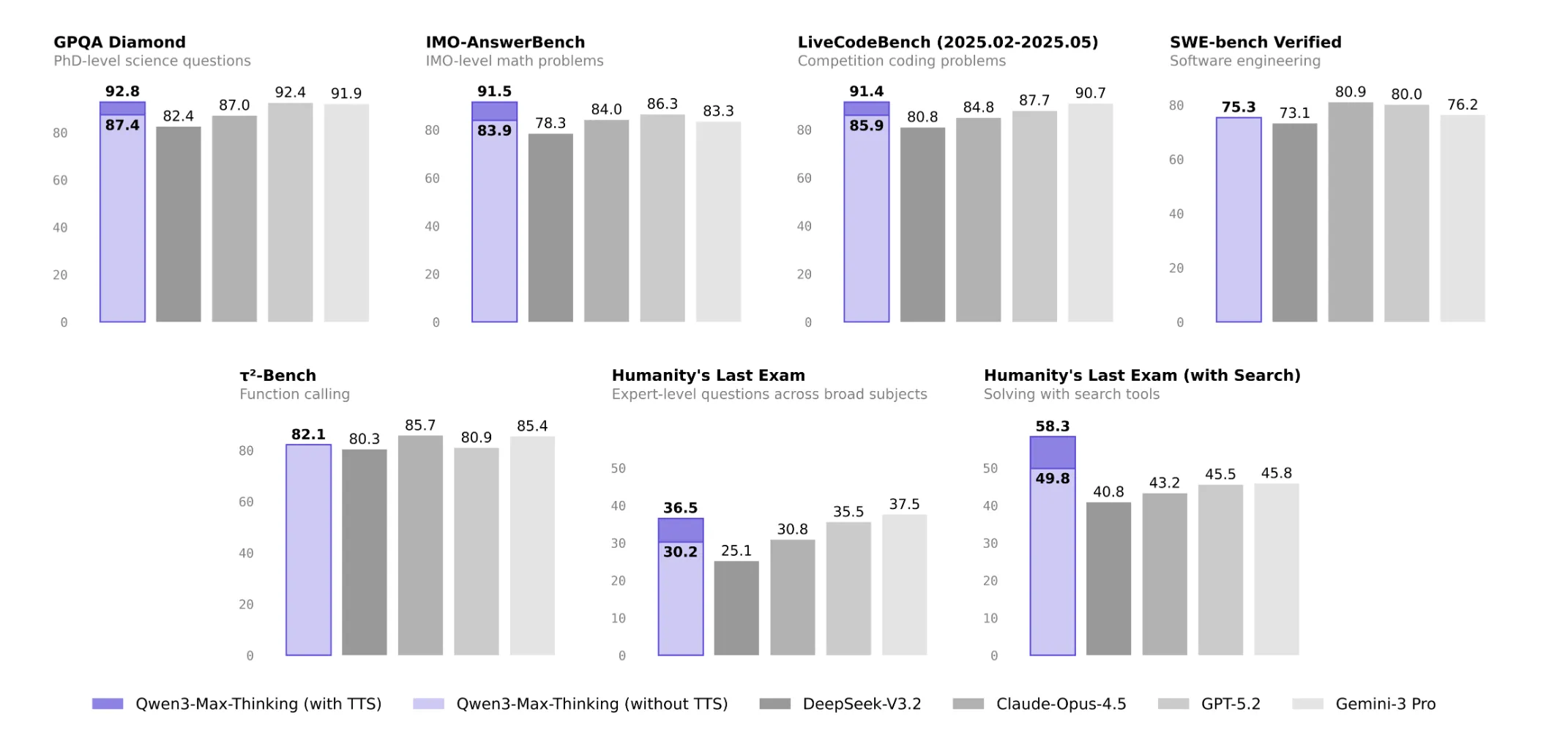
Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic WorkloadsMarkTechPost Qwen3-Max-Thinking is Alibaba’s new flagship reasoning model. It does not only scale parameters, it also changes how inference is done, with explicit control over thinking depth and built in tools for search, memory, and code execution. Model scale, data, and deployment Qwen3-Max-Thinking is a trillion-parameter MoE flagship LLM pretrained on 36T tokens and built on
The post Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic Workloads appeared first on MarkTechPost.
Qwen3-Max-Thinking is Alibaba’s new flagship reasoning model. It does not only scale parameters, it also changes how inference is done, with explicit control over thinking depth and built in tools for search, memory, and code execution. Model scale, data, and deployment Qwen3-Max-Thinking is a trillion-parameter MoE flagship LLM pretrained on 36T tokens and built on
The post Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic Workloads appeared first on MarkTechPost. Read More
How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial OperationsMarkTechPost In this tutorial, we implement a dual-agent governance system that applies Constitutional AI principles to financial operations. We demonstrate how we separate execution and oversight by pairing a Worker Agent that performs financial actions with an Auditor Agent that enforces policy, safety, and compliance. By encoding governance rules directly into a formal constitution and combining
The post How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial Operations appeared first on MarkTechPost.
In this tutorial, we implement a dual-agent governance system that applies Constitutional AI principles to financial operations. We demonstrate how we separate execution and oversight by pairing a Worker Agent that performs financial actions with an Auditor Agent that enforces policy, safety, and compliance. By encoding governance rules directly into a formal constitution and combining
The post How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial Operations appeared first on MarkTechPost. Read More

White House compares industrial revolution with AI eraAI News A White House paper titled “Artificial Intelligence and the Great Divergence” sets out parallels between the effects of the industrial revolution in the 18th and 19th centuries and the current times, with artificial intelligence positioned as guiding the way the world’s economies will be shaped. Artificial intelligence now sits at the centre of US economic
The post White House compares industrial revolution with AI era appeared first on AI News.
A White House paper titled “Artificial Intelligence and the Great Divergence” sets out parallels between the effects of the industrial revolution in the 18th and 19th centuries and the current times, with artificial intelligence positioned as guiding the way the world’s economies will be shaped. Artificial intelligence now sits at the centre of US economic
The post White House compares industrial revolution with AI era appeared first on AI News. Read More

Top 7 Coding Plans for Vibe CodingKDnuggets API bills are killing vibe coding. These seven coding plans let you ship faster without watching token costs.
API bills are killing vibe coding. These seven coding plans let you ship faster without watching token costs. Read More