
YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, StrongerTowards Data Science From YOLOv1 to YOLOv2: prior box, k-means, Darknet-19, passthrough layer, and more
The post YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, Stronger appeared first on Towards Data Science.
From YOLOv1 to YOLOv2: prior box, k-means, Darknet-19, passthrough layer, and more
The post YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, Stronger appeared first on Towards Data Science. Read More
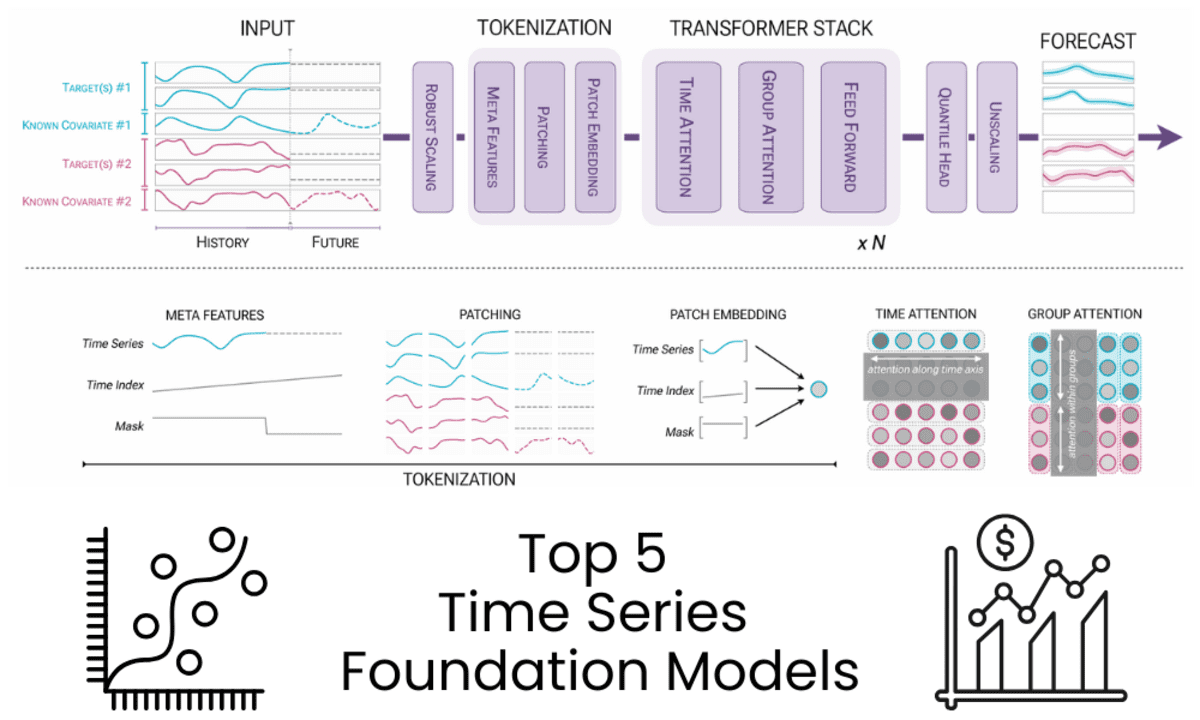
5 Time Series Foundation Models You Are Missing Out OnKDnuggets Five widely adopted time series foundation models delivering accurate zero-shot forecasting across industries and time horizons.
Five widely adopted time series foundation models delivering accurate zero-shot forecasting across industries and time horizons. Read More
Creating a Data Pipeline to Monitor Local Crime TrendsTowards Data Science A walkthough of creating an ETL pipeline to extract local crime data and visualize it in Metabase.
The post Creating a Data Pipeline to Monitor Local Crime Trends appeared first on Towards Data Science.
A walkthough of creating an ETL pipeline to extract local crime data and visualize it in Metabase.
The post Creating a Data Pipeline to Monitor Local Crime Trends appeared first on Towards Data Science. Read More
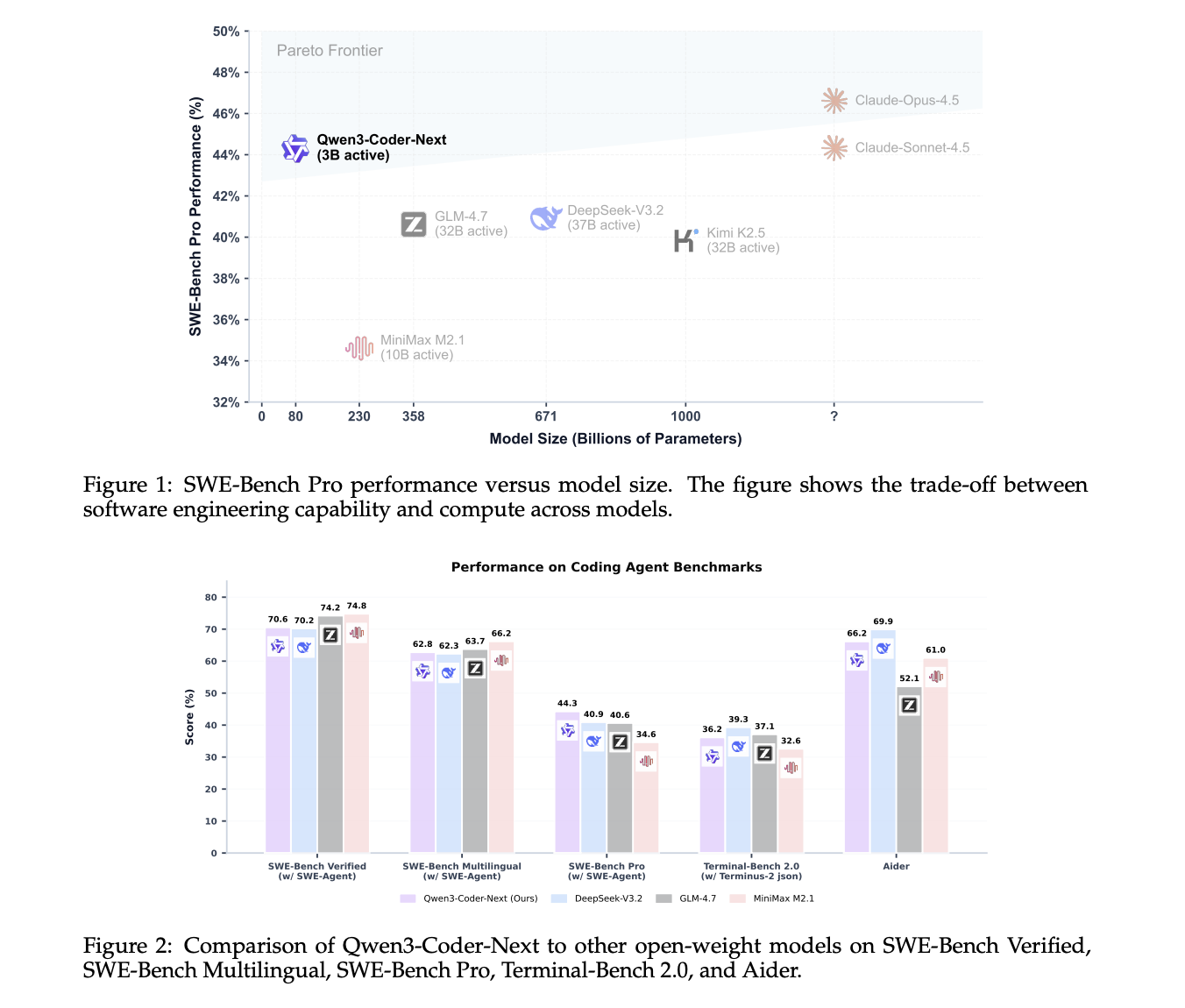
Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local DevelopmentMarkTechPost Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local development. It sits on top of the Qwen3-Next-80B-A3B backbone. The model uses a sparse Mixture-of-Experts (MoE) architecture with hybrid attention. It has 80B total parameters, but only 3B parameters are activated per token. The goal is to match the
The post Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development appeared first on MarkTechPost.
Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local development. It sits on top of the Qwen3-Next-80B-A3B backbone. The model uses a sparse Mixture-of-Experts (MoE) architecture with hybrid attention. It has 80B total parameters, but only 3B parameters are activated per token. The goal is to match the
The post Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development appeared first on MarkTechPost. Read More

Democratizing business intelligence: BGL’s journey with Claude Agent SDK and Amazon Bedrock AgentCoreArtificial Intelligence BGL is a leading provider of self-managed superannuation fund (SMSF) administration solutions that help individuals manage the complex compliance and reporting of their own or a client’s retirement savings, serving over 12,700 businesses across 15 countries. In this blog post, we explore how BGL built its production-ready AI agent using Claude Agent SDK and Amazon Bedrock AgentCore.
BGL is a leading provider of self-managed superannuation fund (SMSF) administration solutions that help individuals manage the complex compliance and reporting of their own or a client’s retirement savings, serving over 12,700 businesses across 15 countries. In this blog post, we explore how BGL built its production-ready AI agent using Claude Agent SDK and Amazon Bedrock AgentCore. Read More
How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOAMarkTechPost In this tutorial, we present an advanced, hands-on tutorial that demonstrates how we use Qrisp to build and execute non-trivial quantum algorithms. We walk through core Qrisp abstractions for quantum data, construct entangled states, and then progressively implement Grover’s search with automatic uncomputation, Quantum Phase Estimation, and a full QAOA workflow for the MaxCut problem.
The post How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOA appeared first on MarkTechPost.
In this tutorial, we present an advanced, hands-on tutorial that demonstrates how we use Qrisp to build and execute non-trivial quantum algorithms. We walk through core Qrisp abstractions for quantum data, construct entangled states, and then progressively implement Grover’s search with automatic uncomputation, Quantum Phase Estimation, and a full QAOA workflow for the MaxCut problem.
The post How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOA appeared first on MarkTechPost. Read More
F-scheduler: illuminating the free-lunch design space for fast sampling of diffusion modelscs.AI updates on arXiv.org arXiv:2510.02390v3 Announce Type: replace-cross
Abstract: Diffusion models are the state-of-the-art generative models for high-resolution images, but sampling from pretrained models is computationally expensive, motivating interest in fast sampling. Although Free-U Net is a training-free enhancement for improving image quality, we find it ineffective under few-step ($<10$) sampling. We analyze the discrete diffusion ODE and propose F-scheduler, a scheduler designed for ODE solvers with Free-U Net. Our proposed scheduler consists of a special time schedule that does not fully denoise the feature to enable the use of the KL-term in the $beta$-VAE decoder, and the schedule of a proper inference stage for modifying the U-Net skip-connection via Free-U Net. Via information theory, we provide insights into how the better scheduled ODE solvers for the diffusion model can outperform the training-based diffusion distillation model. The newly proposed scheduler is compatible with most of the few-step ODE solvers and can sample a 1024 x 1024-resolution image in 6 steps and a 512 x 512-resolution image in 5 steps when it applies to DPM++ 2m and UniPC, with an FID result that outperforms the SOTA distillation models and the 20-step DPM++ 2m solver, respectively. Codebase: https://github.com/TheLovesOfLadyPurple/F-scheduler
arXiv:2510.02390v3 Announce Type: replace-cross
Abstract: Diffusion models are the state-of-the-art generative models for high-resolution images, but sampling from pretrained models is computationally expensive, motivating interest in fast sampling. Although Free-U Net is a training-free enhancement for improving image quality, we find it ineffective under few-step ($<10$) sampling. We analyze the discrete diffusion ODE and propose F-scheduler, a scheduler designed for ODE solvers with Free-U Net. Our proposed scheduler consists of a special time schedule that does not fully denoise the feature to enable the use of the KL-term in the $beta$-VAE decoder, and the schedule of a proper inference stage for modifying the U-Net skip-connection via Free-U Net. Via information theory, we provide insights into how the better scheduled ODE solvers for the diffusion model can outperform the training-based diffusion distillation model. The newly proposed scheduler is compatible with most of the few-step ODE solvers and can sample a 1024 x 1024-resolution image in 6 steps and a 512 x 512-resolution image in 5 steps when it applies to DPM++ 2m and UniPC, with an FID result that outperforms the SOTA distillation models and the 20-step DPM++ 2m solver, respectively. Codebase: https://github.com/TheLovesOfLadyPurple/F-scheduler Read More
DIVERGE: Diversity-Enhanced RAG for Open-Ended Information Seekingcs.AI updates on arXiv.org arXiv:2602.00238v1 Announce Type: cross
Abstract: Existing retrieval-augmented generation (RAG) systems are primarily designed under the assumption that each query has a single correct answer. This overlooks common information-seeking scenarios with multiple plausible answers, where diversity is essential to avoid collapsing to a single dominant response, thereby constraining creativity and compromising fair and inclusive information access. Our analysis reveals a commonly overlooked limitation of standard RAG systems: they underutilize retrieved context diversity, such that increasing retrieval diversity alone does not yield diverse generations. To address this limitation, we propose DIVERGE, a plug-and-play agentic RAG framework with novel reflection-guided generation and memory-augmented iterative refinement, which promotes diverse viewpoints while preserving answer quality. We introduce novel metrics tailored to evaluating the diversity-quality trade-off in open-ended questions, and show that they correlate well with human judgments. We demonstrate that DIVERGE achieves the best diversity-quality trade-off compared to competitive baselines and previous state-of-the-art methods on the real-world Infinity-Chat dataset, substantially improving diversity while maintaining quality. More broadly, our results reveal a systematic limitation of current LLM-based systems for open-ended information-seeking and show that explicitly modeling diversity can mitigate it. Our code is available at: https://github.com/au-clan/Diverge
arXiv:2602.00238v1 Announce Type: cross
Abstract: Existing retrieval-augmented generation (RAG) systems are primarily designed under the assumption that each query has a single correct answer. This overlooks common information-seeking scenarios with multiple plausible answers, where diversity is essential to avoid collapsing to a single dominant response, thereby constraining creativity and compromising fair and inclusive information access. Our analysis reveals a commonly overlooked limitation of standard RAG systems: they underutilize retrieved context diversity, such that increasing retrieval diversity alone does not yield diverse generations. To address this limitation, we propose DIVERGE, a plug-and-play agentic RAG framework with novel reflection-guided generation and memory-augmented iterative refinement, which promotes diverse viewpoints while preserving answer quality. We introduce novel metrics tailored to evaluating the diversity-quality trade-off in open-ended questions, and show that they correlate well with human judgments. We demonstrate that DIVERGE achieves the best diversity-quality trade-off compared to competitive baselines and previous state-of-the-art methods on the real-world Infinity-Chat dataset, substantially improving diversity while maintaining quality. More broadly, our results reveal a systematic limitation of current LLM-based systems for open-ended information-seeking and show that explicitly modeling diversity can mitigate it. Our code is available at: https://github.com/au-clan/Diverge Read More
TransportAgents: a multi-agents LLM framework for traffic accident severity predictioncs.AI updates on arXiv.org arXiv:2601.15519v2 Announce Type: replace
Abstract: Accurate prediction of traffic crash severity is critical for improving emergency response and public safety planning. Although recent large language models (LLMs) exhibit strong reasoning capabilities, their single-agent architectures often struggle with heterogeneous, domain-specific crash data and tend to generate biased or unstable predictions. To address these limitations, this paper proposes TransportAgents, a hybrid multi-agent framework that integrates category-specific LLM reasoning with a multilayer perceptron (MLP) integration module. Each specialized agent focuses on a particular subset of traffic information, such as demographics, environmental context, or incident details, to produce intermediate severity assessments that are subsequently fused into a unified prediction. Extensive experiments on two complementary U.S. datasets, the Consumer Product Safety Risk Management System (CPSRMS) and the National Electronic Injury Surveillance System (NEISS), demonstrate that TransportAgents consistently outperforms both traditional machine learning and advanced LLM-based baselines. Across three representative backbones, including closed-source models such as GPT-3.5 and GPT-4o, as well as open-source models such as LLaMA-3.3, the framework exhibits strong robustness, scalability, and cross-dataset generalizability. A supplementary distributional analysis further shows that TransportAgents produces more balanced and well-calibrated severity predictions than standard single-agent LLM approaches, highlighting its interpretability and reliability for safety-critical decision support applications.
arXiv:2601.15519v2 Announce Type: replace
Abstract: Accurate prediction of traffic crash severity is critical for improving emergency response and public safety planning. Although recent large language models (LLMs) exhibit strong reasoning capabilities, their single-agent architectures often struggle with heterogeneous, domain-specific crash data and tend to generate biased or unstable predictions. To address these limitations, this paper proposes TransportAgents, a hybrid multi-agent framework that integrates category-specific LLM reasoning with a multilayer perceptron (MLP) integration module. Each specialized agent focuses on a particular subset of traffic information, such as demographics, environmental context, or incident details, to produce intermediate severity assessments that are subsequently fused into a unified prediction. Extensive experiments on two complementary U.S. datasets, the Consumer Product Safety Risk Management System (CPSRMS) and the National Electronic Injury Surveillance System (NEISS), demonstrate that TransportAgents consistently outperforms both traditional machine learning and advanced LLM-based baselines. Across three representative backbones, including closed-source models such as GPT-3.5 and GPT-4o, as well as open-source models such as LLaMA-3.3, the framework exhibits strong robustness, scalability, and cross-dataset generalizability. A supplementary distributional analysis further shows that TransportAgents produces more balanced and well-calibrated severity predictions than standard single-agent LLM approaches, highlighting its interpretability and reliability for safety-critical decision support applications. Read More
DuFFin: A Dual-Level Fingerprinting Framework for LLMs IP Protectioncs.AI updates on arXiv.org arXiv:2505.16530v2 Announce Type: replace-cross
Abstract: Large language models (LLMs) are considered valuable Intellectual Properties (IP) for legitimate owners due to the enormous computational cost of training. It is crucial to protect the IP of LLMs from malicious stealing or unauthorized deployment. Despite existing efforts in watermarking and fingerprinting LLMs, these methods either impact the text generation process or are limited in white-box access to the suspect model, making them impractical. Hence, we propose DuFFin, a novel $textbf{Du}$al-Level $textbf{Fin}$gerprinting $textbf{F}$ramework for black-box setting ownership verification. DuFFin extracts the trigger pattern and the knowledge-level fingerprints to identify the source of a suspect model. We conduct experiments on a variety of models collected from the open-source website, including four popular base models as protected LLMs and their fine-tuning, quantization, and safety alignment versions, which are released by large companies, start-ups, and individual users. Results show that our method can accurately verify the copyright of the base protected LLM on their model variants, achieving the IP-ROC metric greater than 0.95. Our code is available at https://github.com/yuliangyan0807/llm-fingerprint.
arXiv:2505.16530v2 Announce Type: replace-cross
Abstract: Large language models (LLMs) are considered valuable Intellectual Properties (IP) for legitimate owners due to the enormous computational cost of training. It is crucial to protect the IP of LLMs from malicious stealing or unauthorized deployment. Despite existing efforts in watermarking and fingerprinting LLMs, these methods either impact the text generation process or are limited in white-box access to the suspect model, making them impractical. Hence, we propose DuFFin, a novel $textbf{Du}$al-Level $textbf{Fin}$gerprinting $textbf{F}$ramework for black-box setting ownership verification. DuFFin extracts the trigger pattern and the knowledge-level fingerprints to identify the source of a suspect model. We conduct experiments on a variety of models collected from the open-source website, including four popular base models as protected LLMs and their fine-tuning, quantization, and safety alignment versions, which are released by large companies, start-ups, and individual users. Results show that our method can accurately verify the copyright of the base protected LLM on their model variants, achieving the IP-ROC metric greater than 0.95. Our code is available at https://github.com/yuliangyan0807/llm-fingerprint. Read More