
DISCOVER: Identifying Patterns of Daily Living in Human Activities from Smart Home Datacs.AI updates on arXiv.org arXiv:2503.01733v3 Announce Type: replace-cross
Abstract: Smart homes equipped with ambient sensors offer a transformative approach to continuous health monitoring and assisted living. Traditional research in this domain primarily focuses on Human Activity Recognition (HAR), which relies on mapping sensor data to a closed set of predefined activity labels. However, the fixed granularity of these labels often constrains their practical utility, failing to capture the subtle, household-specific nuances essential, for example, for tracking individual health over time. To address this, we propose DISCOVER, a framework for discovering and annotating Patterns of Daily Living (PDL) – fine-grained, recurring sequences of sensor events that emerge directly from a resident’s unique routines. DISCOVER utilizes a self-supervised feature extraction and representation-aware clustering pipeline, supported by a custom visualization interface that enables experts to interpret and label discovered patterns with minimal effort. Our evaluation across multiple smart-home environments demonstrates that DISCOVER identifies cohesive behavioral clusters with high inter-rater agreement while achieving classification performance comparable to fully-supervised baselines using only 0.01% of the labels. Beyond reducing annotation overhead, DISCOVER establishes a foundation for longitudinal analysis. By grounding behavior in a resident’s specific environment rather than rigid semantic categories, our framework facilitates the observation of within-person habitual drift. This capability positions the system as a potential tool for identifying subtle behavioral indicators associated with early-stage cognitive decline in future longitudinal studies.
arXiv:2503.01733v3 Announce Type: replace-cross
Abstract: Smart homes equipped with ambient sensors offer a transformative approach to continuous health monitoring and assisted living. Traditional research in this domain primarily focuses on Human Activity Recognition (HAR), which relies on mapping sensor data to a closed set of predefined activity labels. However, the fixed granularity of these labels often constrains their practical utility, failing to capture the subtle, household-specific nuances essential, for example, for tracking individual health over time. To address this, we propose DISCOVER, a framework for discovering and annotating Patterns of Daily Living (PDL) – fine-grained, recurring sequences of sensor events that emerge directly from a resident’s unique routines. DISCOVER utilizes a self-supervised feature extraction and representation-aware clustering pipeline, supported by a custom visualization interface that enables experts to interpret and label discovered patterns with minimal effort. Our evaluation across multiple smart-home environments demonstrates that DISCOVER identifies cohesive behavioral clusters with high inter-rater agreement while achieving classification performance comparable to fully-supervised baselines using only 0.01% of the labels. Beyond reducing annotation overhead, DISCOVER establishes a foundation for longitudinal analysis. By grounding behavior in a resident’s specific environment rather than rigid semantic categories, our framework facilitates the observation of within-person habitual drift. This capability positions the system as a potential tool for identifying subtle behavioral indicators associated with early-stage cognitive decline in future longitudinal studies. Read More
Plug-and-Play Emotion Graphs for Compositional Prompting in Zero-Shot Speech Emotion Recognitioncs.AI updates on arXiv.org arXiv:2509.25458v2 Announce Type: replace
Abstract: Large audio-language models (LALMs) exhibit strong zero-shot performance across speech tasks but struggle with speech emotion recognition (SER) due to weak paralinguistic modeling and limited cross-modal reasoning. We propose Compositional Chain-of-Thought Prompting for Emotion Reasoning (CCoT-Emo), a framework that introduces structured Emotion Graphs (EGs) to guide LALMs in emotion inference without fine-tuning. Each EG encodes seven acoustic features (e.g., pitch, speech rate, jitter, shimmer), textual sentiment, keywords, and cross-modal associations. Embedded into prompts, EGs provide interpretable and compositional representations that enhance LALM reasoning. Experiments across SER benchmarks show that CCoT-Emo outperforms prior SOTA and improves accuracy over zero-shot baselines.
arXiv:2509.25458v2 Announce Type: replace
Abstract: Large audio-language models (LALMs) exhibit strong zero-shot performance across speech tasks but struggle with speech emotion recognition (SER) due to weak paralinguistic modeling and limited cross-modal reasoning. We propose Compositional Chain-of-Thought Prompting for Emotion Reasoning (CCoT-Emo), a framework that introduces structured Emotion Graphs (EGs) to guide LALMs in emotion inference without fine-tuning. Each EG encodes seven acoustic features (e.g., pitch, speech rate, jitter, shimmer), textual sentiment, keywords, and cross-modal associations. Embedded into prompts, EGs provide interpretable and compositional representations that enhance LALM reasoning. Experiments across SER benchmarks show that CCoT-Emo outperforms prior SOTA and improves accuracy over zero-shot baselines. Read More
Beyond Fixed Frames: Dynamic Character-Aligned Speech Tokenizationcs.AI updates on arXiv.org arXiv:2601.23174v2 Announce Type: replace-cross
Abstract: Neural audio codecs are at the core of modern conversational speech technologies, converting continuous speech into sequences of discrete tokens that can be processed by LLMs. However, existing codecs typically operate at fixed frame rates, allocating tokens uniformly in time and producing unnecessarily long sequences. In this work, we introduce DyCAST, a Dynamic Character-Aligned Speech Tokenizer that enables variable-frame-rate tokenization through soft character-level alignment and explicit duration modeling. DyCAST learns to associate tokens with character-level linguistic units during training and supports alignment-free inference with direct control over token durations at decoding time. To improve speech resynthesis quality at low frame rates, we further introduce a retrieval-augmented decoding mechanism that enhances reconstruction fidelity without increasing bitrate. Experiments show that DyCAST achieves competitive speech resynthesis quality and downstream performance while using significantly fewer tokens than fixed-frame-rate codecs. Code and checkpoints will be released publicly at https://github.com/lucadellalib/dycast.
arXiv:2601.23174v2 Announce Type: replace-cross
Abstract: Neural audio codecs are at the core of modern conversational speech technologies, converting continuous speech into sequences of discrete tokens that can be processed by LLMs. However, existing codecs typically operate at fixed frame rates, allocating tokens uniformly in time and producing unnecessarily long sequences. In this work, we introduce DyCAST, a Dynamic Character-Aligned Speech Tokenizer that enables variable-frame-rate tokenization through soft character-level alignment and explicit duration modeling. DyCAST learns to associate tokens with character-level linguistic units during training and supports alignment-free inference with direct control over token durations at decoding time. To improve speech resynthesis quality at low frame rates, we further introduce a retrieval-augmented decoding mechanism that enhances reconstruction fidelity without increasing bitrate. Experiments show that DyCAST achieves competitive speech resynthesis quality and downstream performance while using significantly fewer tokens than fixed-frame-rate codecs. Code and checkpoints will be released publicly at https://github.com/lucadellalib/dycast. Read More
When AI Persuades: Adversarial Explanation Attacks on Human Trust in AI-Assisted Decision Makingcs.AI updates on arXiv.org arXiv:2602.04003v1 Announce Type: new
Abstract: Most adversarial threats in artificial intelligence target the computational behavior of models rather than the humans who rely on them. Yet modern AI systems increasingly operate within human decision loops, where users interpret and act on model recommendations. Large Language Models generate fluent natural-language explanations that shape how users perceive and trust AI outputs, revealing a new attack surface at the cognitive layer: the communication channel between AI and its users. We introduce adversarial explanation attacks (AEAs), where an attacker manipulates the framing of LLM-generated explanations to modulate human trust in incorrect outputs. We formalize this behavioral threat through the trust miscalibration gap, a metric that captures the difference in human trust between correct and incorrect outputs under adversarial explanations. By incorporating this gap, AEAs explore the daunting threats in which persuasive explanations reinforce users’ trust in incorrect predictions. To characterize this threat, we conducted a controlled experiment (n = 205), systematically varying four dimensions of explanation framing: reasoning mode, evidence type, communication style, and presentation format. Our findings show that users report nearly identical trust for adversarial and benign explanations, with adversarial explanations preserving the vast majority of benign trust despite being incorrect. The most vulnerable cases arise when AEAs closely resemble expert communication, combining authoritative evidence, neutral tone, and domain-appropriate reasoning. Vulnerability is highest on hard tasks, in fact-driven domains, and among participants who are less formally educated, younger, or highly trusting of AI. This is the first systematic security study that treats explanations as an adversarial cognitive channel and quantifies their impact on human trust in AI-assisted decision making.
arXiv:2602.04003v1 Announce Type: new
Abstract: Most adversarial threats in artificial intelligence target the computational behavior of models rather than the humans who rely on them. Yet modern AI systems increasingly operate within human decision loops, where users interpret and act on model recommendations. Large Language Models generate fluent natural-language explanations that shape how users perceive and trust AI outputs, revealing a new attack surface at the cognitive layer: the communication channel between AI and its users. We introduce adversarial explanation attacks (AEAs), where an attacker manipulates the framing of LLM-generated explanations to modulate human trust in incorrect outputs. We formalize this behavioral threat through the trust miscalibration gap, a metric that captures the difference in human trust between correct and incorrect outputs under adversarial explanations. By incorporating this gap, AEAs explore the daunting threats in which persuasive explanations reinforce users’ trust in incorrect predictions. To characterize this threat, we conducted a controlled experiment (n = 205), systematically varying four dimensions of explanation framing: reasoning mode, evidence type, communication style, and presentation format. Our findings show that users report nearly identical trust for adversarial and benign explanations, with adversarial explanations preserving the vast majority of benign trust despite being incorrect. The most vulnerable cases arise when AEAs closely resemble expert communication, combining authoritative evidence, neutral tone, and domain-appropriate reasoning. Vulnerability is highest on hard tasks, in fact-driven domains, and among participants who are less formally educated, younger, or highly trusting of AI. This is the first systematic security study that treats explanations as an adversarial cognitive channel and quantifies their impact on human trust in AI-assisted decision making. Read More
GPT-5 lowers the cost of cell-free protein synthesisOpenAI News An autonomous lab combining OpenAI’s GPT-5 with Ginkgo Bioworks’ cloud automation cut cell-free protein synthesis costs by 40% through closed-loop experimentation.
An autonomous lab combining OpenAI’s GPT-5 with Ginkgo Bioworks’ cloud automation cut cell-free protein synthesis costs by 40% through closed-loop experimentation. Read More
AI Expo 2026 Day 2: Moving experimental pilots to AI productionAI News The second day of the co-located AI & Big Data Expo and Digital Transformation Week in London showed a market in a clear transition. Early excitement over generative models is fading. Enterprise leaders now face the friction of fitting these tools into current stacks. Day two sessions focused less on large language models and more
The post AI Expo 2026 Day 2: Moving experimental pilots to AI production appeared first on AI News.
The second day of the co-located AI & Big Data Expo and Digital Transformation Week in London showed a market in a clear transition. Early excitement over generative models is fading. Enterprise leaders now face the friction of fitting these tools into current stacks. Day two sessions focused less on large language models and more
The post AI Expo 2026 Day 2: Moving experimental pilots to AI production appeared first on AI News. Read More

OpenAI Just Launched GPT-5.3-Codex: A Faster Agentic Coding Model Unifying Frontier Code Performance And Professional Reasoning Into One SystemMarkTechPost OpenAI has just introduced GPT-5.3-Codex, a new agentic coding model that extends Codex from writing and reviewing code to handling a broad range of work on a computer. The model combines the frontier coding performance of GPT-5.2-Codex with the reasoning and professional knowledge capabilities of GPT-5.2 into a single system, and it runs 25% faster
The post OpenAI Just Launched GPT-5.3-Codex: A Faster Agentic Coding Model Unifying Frontier Code Performance And Professional Reasoning Into One System appeared first on MarkTechPost.
OpenAI has just introduced GPT-5.3-Codex, a new agentic coding model that extends Codex from writing and reviewing code to handling a broad range of work on a computer. The model combines the frontier coding performance of GPT-5.2-Codex with the reasoning and professional knowledge capabilities of GPT-5.2 into a single system, and it runs 25% faster
The post OpenAI Just Launched GPT-5.3-Codex: A Faster Agentic Coding Model Unifying Frontier Code Performance And Professional Reasoning Into One System appeared first on MarkTechPost. Read More
How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame ContractsMarkTechPost Schemas, and Composable DataFrame ContractsIn this tutorial, we demonstrate how to build robust, production-grade data validation pipelines using Pandera with typed DataFrame models. We start by simulating realistic, imperfect transactional data and progressively enforce strict schema constraints, column-level rules, and cross-column business logic using declarative checks. We show how lazy validation helps us surface multiple
The post How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame Contracts appeared first on MarkTechPost.
Schemas, and Composable DataFrame ContractsIn this tutorial, we demonstrate how to build robust, production-grade data validation pipelines using Pandera with typed DataFrame models. We start by simulating realistic, imperfect transactional data and progressively enforce strict schema constraints, column-level rules, and cross-column business logic using declarative checks. We show how lazy validation helps us surface multiple
The post How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame Contracts appeared first on MarkTechPost. Read More
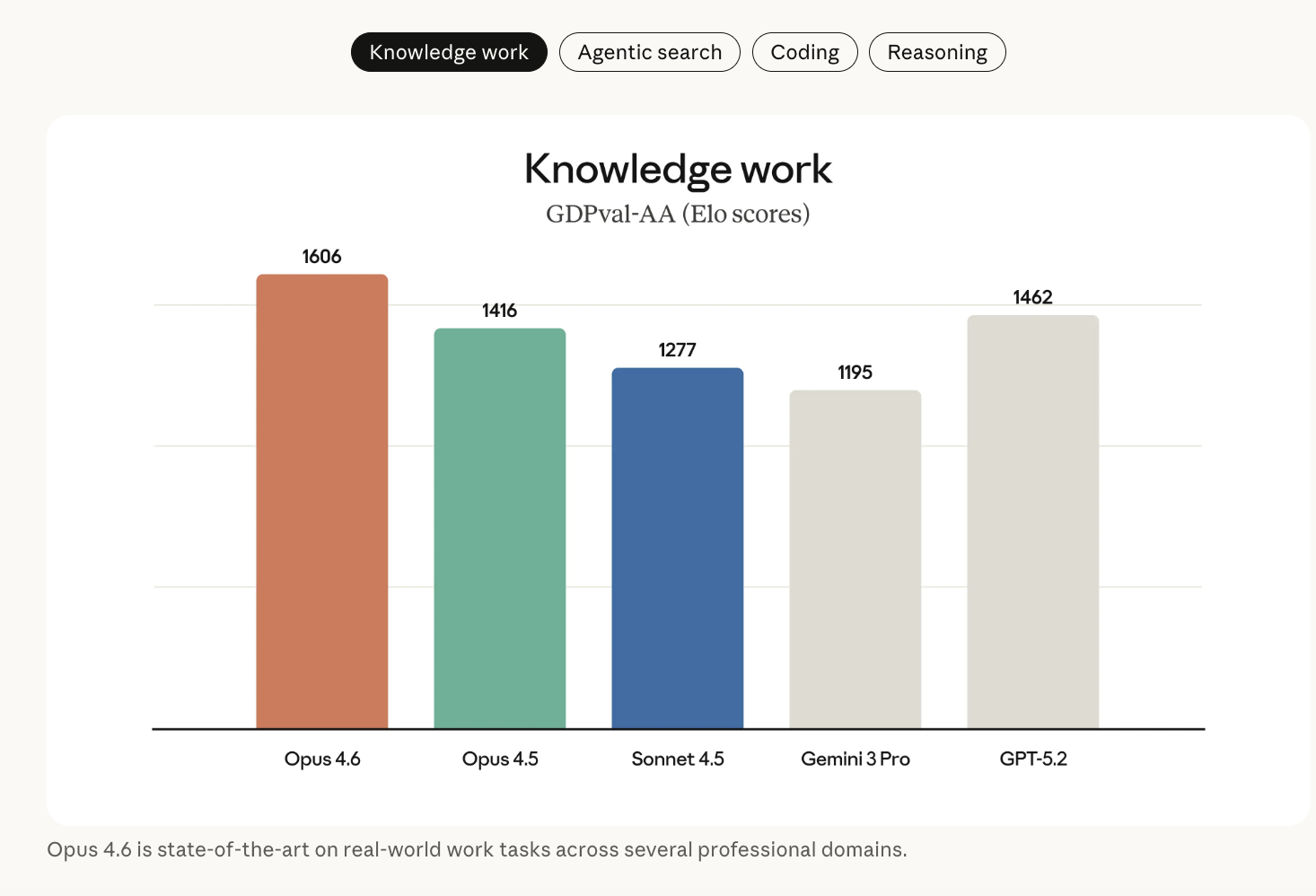
Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling CapabilitiesMarkTechPost Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value knowledge work. The model builds on Claude Opus 4.5 and is now available on claude.ai, the Claude API, and major cloud providers under the ID claude-opus-4-6. Model focus: agentic work, not single answers Opus 4.6
The post Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling Capabilities appeared first on MarkTechPost.
Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value knowledge work. The model builds on Claude Opus 4.5 and is now available on claude.ai, the Claude API, and major cloud providers under the ID claude-opus-4-6. Model focus: agentic work, not single answers Opus 4.6
The post Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling Capabilities appeared first on MarkTechPost. Read More
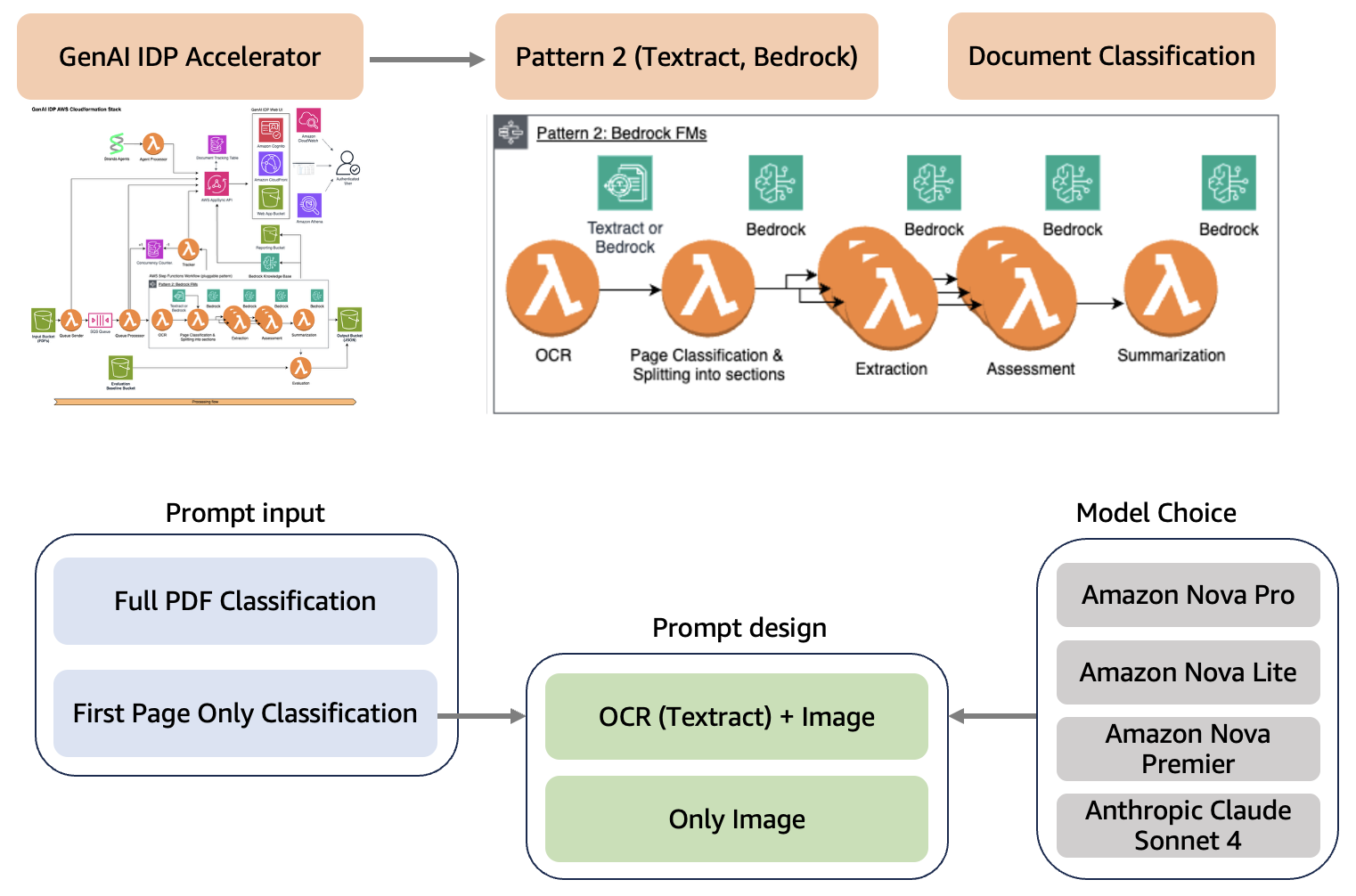
How Associa transforms document classification with the GenAI IDP Accelerator and Amazon BedrockArtificial Intelligence Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks.
Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks. Read More