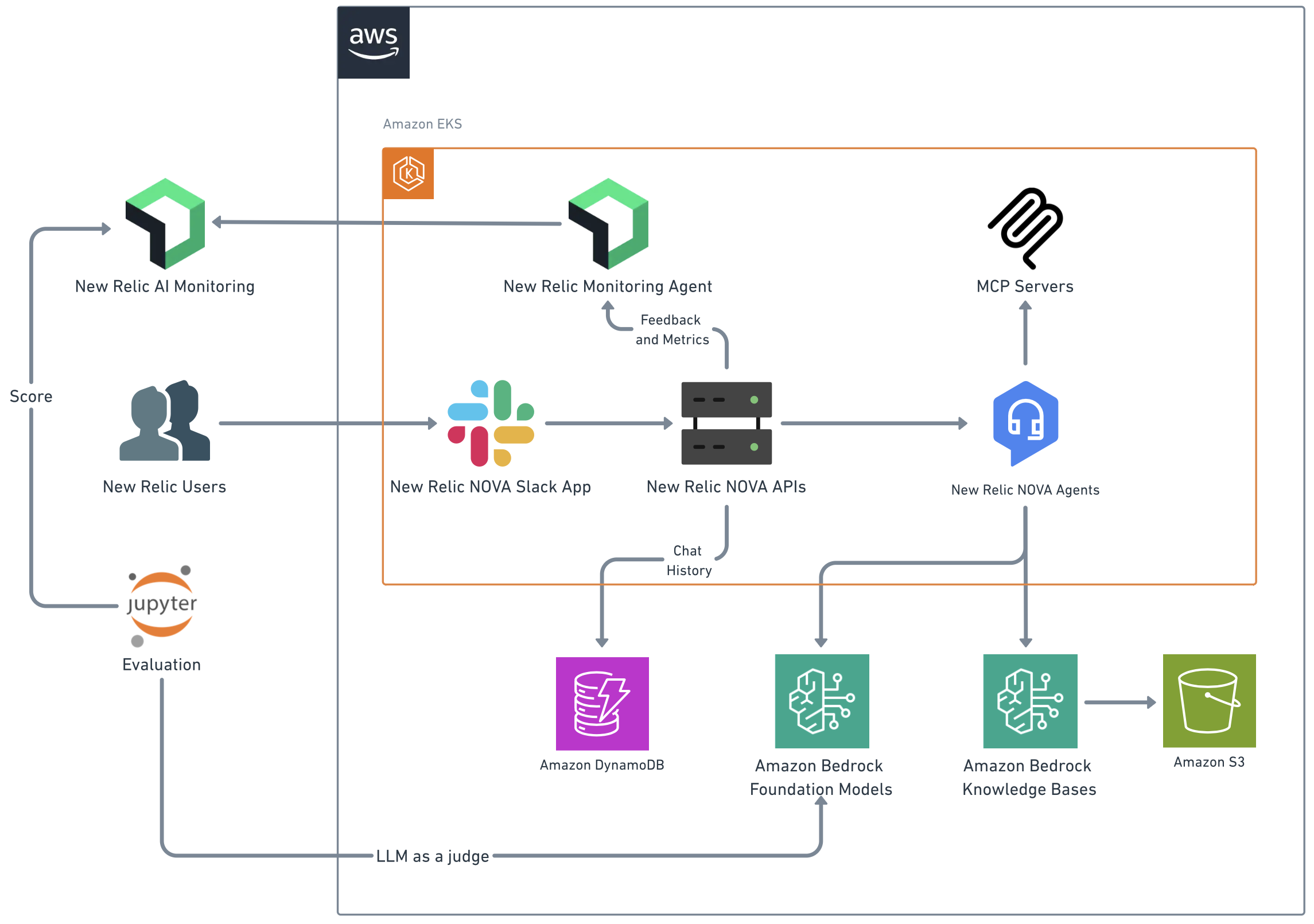
New Relic transforms productivity with generative AI on AWSArtificial Intelligence Working with the Generative AI Innovation Center, New Relic NOVA (New Relic Omnipresence Virtual Assistant) evolved from a knowledge assistant into a comprehensive productivity engine. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale.
Working with the Generative AI Innovation Center, New Relic NOVA (New Relic Omnipresence Virtual Assistant) evolved from a knowledge assistant into a comprehensive productivity engine. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale. Read More
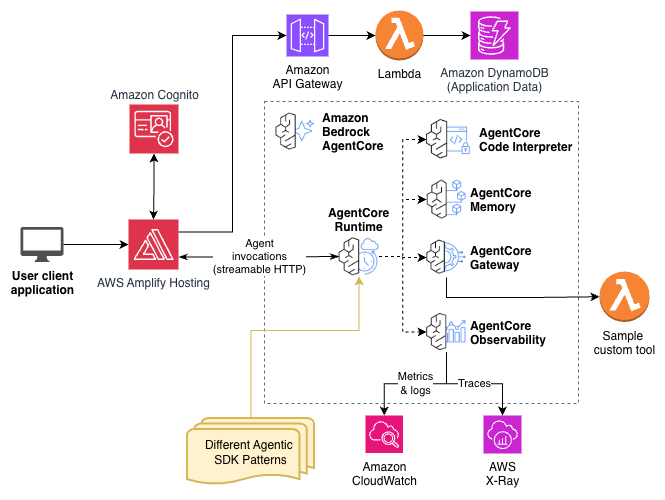
Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCoreArtificial Intelligence In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration. Read More

7 Python EDA Tricks to Find and Fix Data IssuesKDnuggets 7 Python tricks applicable to your early exploratory data analyses (EDA) to identify and deal with various data quality issues.
7 Python tricks applicable to your early exploratory data analyses (EDA) to identify and deal with various data quality issues. Read More

The Death of the “Everything Prompt”: Google’s Move Toward Structured AITowards Data Science How the new Interactions API enables deep-reasoning, stateful, agentic workflows.
The post The Death of the “Everything Prompt”: Google’s Move Toward Structured AI appeared first on Towards Data Science.
How the new Interactions API enables deep-reasoning, stateful, agentic workflows.
The post The Death of the “Everything Prompt”: Google’s Move Toward Structured AI appeared first on Towards Data Science. Read More
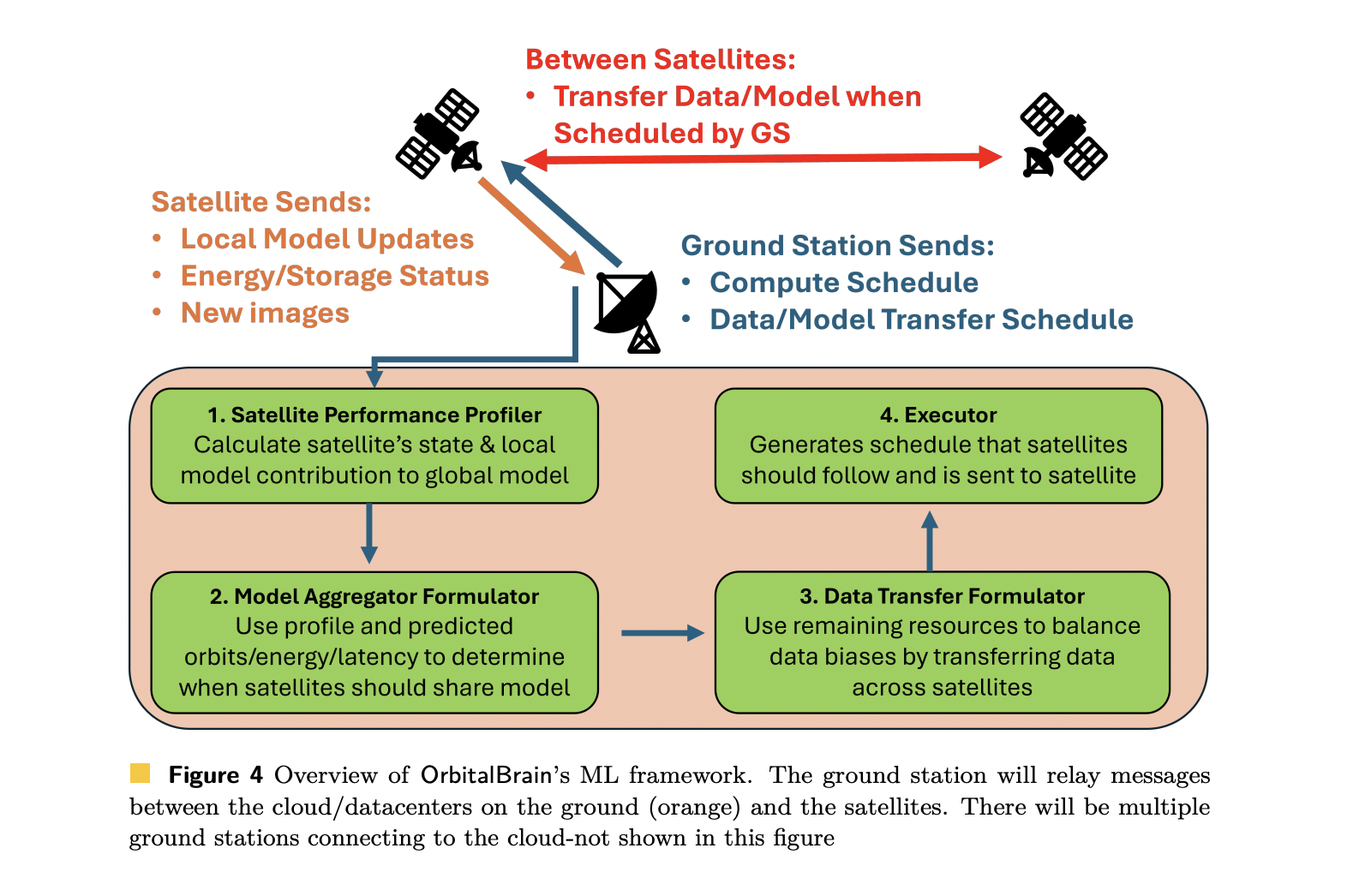
Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization StrategiesMarkTechPost Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground in time for model training. Downlink bandwidth is the main bottleneck. Images can sit on orbit for days while ground models train on partial and delayed data. Microsoft Researchers introduced ‘OrbitalBrain’ framework as a different
The post Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization Strategies appeared first on MarkTechPost.
Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground in time for model training. Downlink bandwidth is the main bottleneck. Images can sit on orbit for days while ground models train on partial and delayed data. Microsoft Researchers introduced ‘OrbitalBrain’ framework as a different
The post Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization Strategies appeared first on MarkTechPost. Read More
The Machine Learning Lessons I’ve Learned Last MonthTowards Data Science Delayed January: deadlines, downtimes, and flow times
The post The Machine Learning Lessons I’ve Learned Last Month appeared first on Towards Data Science.
Delayed January: deadlines, downtimes, and flow times
The post The Machine Learning Lessons I’ve Learned Last Month appeared first on Towards Data Science. Read More
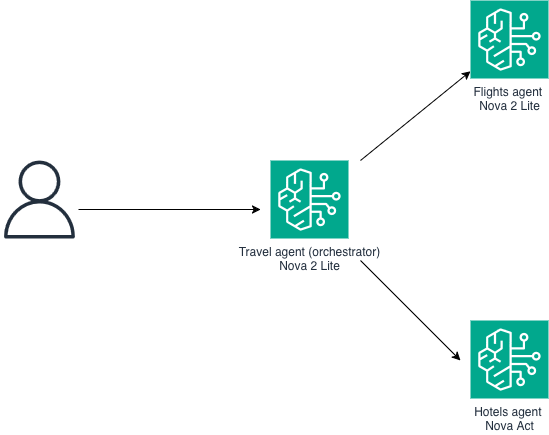
Agent-to-agent collaboration: Using Amazon Nova 2 Lite and Amazon Nova Act for multi-agent systemsArtificial Intelligence This post walks through how agent-to-agent collaboration on Amazon Bedrock works in practice, using Amazon Nova 2 Lite for planning and Amazon Nova Act for browser interaction, to turn a fragile single-agent setup into a predictable multi-agent system.
This post walks through how agent-to-agent collaboration on Amazon Bedrock works in practice, using Amazon Nova 2 Lite for planning and Amazon Nova Act for browser interaction, to turn a fragile single-agent setup into a predictable multi-agent system. Read More
Goldman Sachs tests autonomous AI agents for process-heavy workAI News Goldman Sachs is pushing deeper into real use of artificial intelligence inside its operations, moving to systems that can carry out complex tasks on their own. The Wall Street bank is working with AI startup Anthropic to create autonomous AI agents powered by Anthropic’s Claude model that can handle work that used to require large
The post Goldman Sachs tests autonomous AI agents for process-heavy work appeared first on AI News.
Goldman Sachs is pushing deeper into real use of artificial intelligence inside its operations, moving to systems that can carry out complex tasks on their own. The Wall Street bank is working with AI startup Anthropic to create autonomous AI agents powered by Anthropic’s Claude model that can handle work that used to require large
The post Goldman Sachs tests autonomous AI agents for process-heavy work appeared first on AI News. Read More
What AI can (and can’t) tell us about XRP in ETF-driven marketsAI News For a long time, cryptocurrency prices moved quickly. A headline would hit, sentiment would spike, and charts would react almost immediately. That pattern no longer holds. Today’s market is slow, heavier than before, and shaped by forces that do not always announce themselves clearly. Capital allocation, ETF mechanics, and macro positioning now influence price behaviour
The post What AI can (and can’t) tell us about XRP in ETF-driven markets appeared first on AI News.
For a long time, cryptocurrency prices moved quickly. A headline would hit, sentiment would spike, and charts would react almost immediately. That pattern no longer holds. Today’s market is slow, heavier than before, and shaped by forces that do not always announce themselves clearly. Capital allocation, ETF mechanics, and macro positioning now influence price behaviour
The post What AI can (and can’t) tell us about XRP in ETF-driven markets appeared first on AI News. Read More

Exclusive: Why are Chinese AI models dominating open-source as Western labs step back?AI News Because Western AI labs won’t—or can’t—anymore. As OpenAI, Anthropic, and Google face mounting pressure to restrict their most powerful models, Chinese developers have filled the open-source void with AI explicitly built for what operators need: powerful models that run on commodity hardware. A new security study reveals just how thoroughly Chinese AI has captured this space. Research published by SentinelOne
The post Exclusive: Why are Chinese AI models dominating open-source as Western labs step back? appeared first on AI News.
Because Western AI labs won’t—or can’t—anymore. As OpenAI, Anthropic, and Google face mounting pressure to restrict their most powerful models, Chinese developers have filled the open-source void with AI explicitly built for what operators need: powerful models that run on commodity hardware. A new security study reveals just how thoroughly Chinese AI has captured this space. Research published by SentinelOne
The post Exclusive: Why are Chinese AI models dominating open-source as Western labs step back? appeared first on AI News. Read More