

Credal Transformer: A Principled Approach for Quantifying and Mitigating Hallucinations in Large Language Modelscs.AI updates on arXiv.org arXiv:2510.12137v1 Announce Type: cross
Abstract: Large Language Models (LLMs) hallucinate, generating factually incorrect yet confident assertions. We argue this stems from the Transformer’s Softmax function, which creates “Artificial Certainty” by collapsing ambiguous attention scores into a single probability distribution, discarding uncertainty information at each layer. To fix this, we introduce the Credal Transformer, which replaces standard attention with a Credal Attention Mechanism (CAM) based on evidential theory. CAM produces a “credal set” (a set of distributions) instead of a single attention vector, with the set’s size directly measuring model uncertainty. We implement this by re-conceptualizing attention scores as evidence masses for a Dirichlet distribution: sufficient evidence recovers standard attention, while insufficient evidence yields a diffuse distribution, representing ambiguity. Empirically, the Credal Transformer identifies out-of-distribution inputs, quantifies ambiguity, and significantly reduces confident errors on unanswerable questions by abstaining. Our contribution is a new architecture to mitigate hallucinations and a design paradigm that integrates uncertainty quantification directly into the model, providing a foundation for more reliable AI.
arXiv:2510.12137v1 Announce Type: cross
Abstract: Large Language Models (LLMs) hallucinate, generating factually incorrect yet confident assertions. We argue this stems from the Transformer’s Softmax function, which creates “Artificial Certainty” by collapsing ambiguous attention scores into a single probability distribution, discarding uncertainty information at each layer. To fix this, we introduce the Credal Transformer, which replaces standard attention with a Credal Attention Mechanism (CAM) based on evidential theory. CAM produces a “credal set” (a set of distributions) instead of a single attention vector, with the set’s size directly measuring model uncertainty. We implement this by re-conceptualizing attention scores as evidence masses for a Dirichlet distribution: sufficient evidence recovers standard attention, while insufficient evidence yields a diffuse distribution, representing ambiguity. Empirically, the Credal Transformer identifies out-of-distribution inputs, quantifies ambiguity, and significantly reduces confident errors on unanswerable questions by abstaining. Our contribution is a new architecture to mitigate hallucinations and a design paradigm that integrates uncertainty quantification directly into the model, providing a foundation for more reliable AI. Read More
Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluationcs.AI updates on arXiv.org arXiv:2510.11977v1 Announce Type: new
Abstract: AI agents have been developed for complex real-world tasks from coding to customer service. But AI agent evaluations suffer from many challenges that undermine our understanding of how well agents really work. We introduce the Holistic Agent Leaderboard (HAL) to address these challenges. We make three main contributions. First, we provide a standardized evaluation harness that orchestrates parallel evaluations across hundreds of VMs, reducing evaluation time from weeks to hours while eliminating common implementation bugs. Second, we conduct three-dimensional analysis spanning models, scaffolds, and benchmarks. We validate the harness by conducting 21,730 agent rollouts across 9 models and 9 benchmarks in coding, web navigation, science, and customer service with a total cost of about $40,000. Our analysis reveals surprising insights, such as higher reasoning effort reducing accuracy in the majority of runs. Third, we use LLM-aided log inspection to uncover previously unreported behaviors, such as searching for the benchmark on HuggingFace instead of solving a task, or misusing credit cards in flight booking tasks. We share all agent logs, comprising 2.5B tokens of language model calls, to incentivize further research into agent behavior. By standardizing how the field evaluates agents and addressing common pitfalls in agent evaluation, we hope to shift the focus from agents that ace benchmarks to agents that work reliably in the real world.
arXiv:2510.11977v1 Announce Type: new
Abstract: AI agents have been developed for complex real-world tasks from coding to customer service. But AI agent evaluations suffer from many challenges that undermine our understanding of how well agents really work. We introduce the Holistic Agent Leaderboard (HAL) to address these challenges. We make three main contributions. First, we provide a standardized evaluation harness that orchestrates parallel evaluations across hundreds of VMs, reducing evaluation time from weeks to hours while eliminating common implementation bugs. Second, we conduct three-dimensional analysis spanning models, scaffolds, and benchmarks. We validate the harness by conducting 21,730 agent rollouts across 9 models and 9 benchmarks in coding, web navigation, science, and customer service with a total cost of about $40,000. Our analysis reveals surprising insights, such as higher reasoning effort reducing accuracy in the majority of runs. Third, we use LLM-aided log inspection to uncover previously unreported behaviors, such as searching for the benchmark on HuggingFace instead of solving a task, or misusing credit cards in flight booking tasks. We share all agent logs, comprising 2.5B tokens of language model calls, to incentivize further research into agent behavior. By standardizing how the field evaluates agents and addressing common pitfalls in agent evaluation, we hope to shift the focus from agents that ace benchmarks to agents that work reliably in the real world. Read More
Conjecturing: An Overlooked Step in Formal Mathematical Reasoningcs.AI updates on arXiv.org arXiv:2510.11986v1 Announce Type: cross
Abstract: Autoformalisation, the task of expressing informal mathematical statements in formal language, is often viewed as a direct translation process. This, however, disregards a critical preceding step: conjecturing. Many mathematical problems cannot be formalised directly without first conjecturing a conclusion such as an explicit answer, or a specific bound. Since Large Language Models (LLMs) already struggle with autoformalisation, and the evaluation of their conjecturing ability is limited and often entangled within autoformalisation or proof, it is particularly challenging to understand its effect. To address this gap, we augment existing datasets to create ConjectureBench, and redesign the evaluation framework and metric specifically to measure the conjecturing capabilities of LLMs both as a distinct task and within the autoformalisation pipeline. Our evaluation of foundational models, including GPT-4.1 and DeepSeek-V3.1, reveals that their autoformalisation performance is substantially overestimated when the conjecture is accounted for during evaluation. However, the conjecture should not be assumed to be provided. We design an inference-time method, Lean-FIRe to improve conjecturing and autoformalisation, which, to the best of our knowledge, achieves the first successful end-to-end autoformalisation of 13 PutnamBench problems with GPT-4.1 and 7 with DeepSeek-V3.1. We demonstrate that while LLMs possess the requisite knowledge to generate accurate conjectures, improving autoformalisation performance requires treating conjecturing as an independent task, and investigating further how to correctly integrate it within autoformalisation. Finally, we provide forward-looking guidance to steer future research toward improving conjecturing, an overlooked step of formal mathematical reasoning.
arXiv:2510.11986v1 Announce Type: cross
Abstract: Autoformalisation, the task of expressing informal mathematical statements in formal language, is often viewed as a direct translation process. This, however, disregards a critical preceding step: conjecturing. Many mathematical problems cannot be formalised directly without first conjecturing a conclusion such as an explicit answer, or a specific bound. Since Large Language Models (LLMs) already struggle with autoformalisation, and the evaluation of their conjecturing ability is limited and often entangled within autoformalisation or proof, it is particularly challenging to understand its effect. To address this gap, we augment existing datasets to create ConjectureBench, and redesign the evaluation framework and metric specifically to measure the conjecturing capabilities of LLMs both as a distinct task and within the autoformalisation pipeline. Our evaluation of foundational models, including GPT-4.1 and DeepSeek-V3.1, reveals that their autoformalisation performance is substantially overestimated when the conjecture is accounted for during evaluation. However, the conjecture should not be assumed to be provided. We design an inference-time method, Lean-FIRe to improve conjecturing and autoformalisation, which, to the best of our knowledge, achieves the first successful end-to-end autoformalisation of 13 PutnamBench problems with GPT-4.1 and 7 with DeepSeek-V3.1. We demonstrate that while LLMs possess the requisite knowledge to generate accurate conjectures, improving autoformalisation performance requires treating conjecturing as an independent task, and investigating further how to correctly integrate it within autoformalisation. Finally, we provide forward-looking guidance to steer future research toward improving conjecturing, an overlooked step of formal mathematical reasoning. Read More
Asking Clarifying Questions for Preference Elicitation With Large Language Modelscs.AI updates on arXiv.org arXiv:2510.12015v1 Announce Type: new
Abstract: Large Language Models (LLMs) have made it possible for recommendation systems to interact with users in open-ended conversational interfaces. In order to personalize LLM responses, it is crucial to elicit user preferences, especially when there is limited user history. One way to get more information is to present clarifying questions to the user. However, generating effective sequential clarifying questions across various domains remains a challenge. To address this, we introduce a novel approach for training LLMs to ask sequential questions that reveal user preferences. Our method follows a two-stage process inspired by diffusion models. Starting from a user profile, the forward process generates clarifying questions to obtain answers and then removes those answers step by step, serving as a way to add “noise” to the user profile. The reverse process involves training a model to “denoise” the user profile by learning to ask effective clarifying questions. Our results show that our method significantly improves the LLM’s proficiency in asking funnel questions and eliciting user preferences effectively.
arXiv:2510.12015v1 Announce Type: new
Abstract: Large Language Models (LLMs) have made it possible for recommendation systems to interact with users in open-ended conversational interfaces. In order to personalize LLM responses, it is crucial to elicit user preferences, especially when there is limited user history. One way to get more information is to present clarifying questions to the user. However, generating effective sequential clarifying questions across various domains remains a challenge. To address this, we introduce a novel approach for training LLMs to ask sequential questions that reveal user preferences. Our method follows a two-stage process inspired by diffusion models. Starting from a user profile, the forward process generates clarifying questions to obtain answers and then removes those answers step by step, serving as a way to add “noise” to the user profile. The reverse process involves training a model to “denoise” the user profile by learning to ask effective clarifying questions. Our results show that our method significantly improves the LLM’s proficiency in asking funnel questions and eliciting user preferences effectively. Read More
CGBench: Benchmarking Language Model Scientific Reasoning for Clinical Genetics Researchcs.AI updates on arXiv.org arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly.
arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly. Read More

Salesforce commits $15 billion to boost AI growth in San FranciscoAI News Salesforce plans to invest $15 billion in San Francisco over the next five years to help businesses adopt AI. The move underscores the company’s push to stay competitive as AI becomes central to enterprise software. Founded and headquartered in San Francisco since 1999, Salesforce has been adding AI features across its products, including the workplace
The post Salesforce commits $15 billion to boost AI growth in San Francisco appeared first on AI News.
Salesforce plans to invest $15 billion in San Francisco over the next five years to help businesses adopt AI. The move underscores the company’s push to stay competitive as AI becomes central to enterprise software. Founded and headquartered in San Francisco since 1999, Salesforce has been adding AI features across its products, including the workplace
The post Salesforce commits $15 billion to boost AI growth in San Francisco appeared first on AI News. Read More

Cisco: Only 13% have a solid AI strategy and they’re lapping rivalsAI News If you’ve ever thought companies talk more than act when it comes to their AI strategy, a new Cisco report backs you up. It turns out that just 13 percent globally are actually prepared for the AI revolution. However, this small group – which Cisco calls the ‘Pacesetters’ – are lapping the competition. The third
The post Cisco: Only 13% have a solid AI strategy and they’re lapping rivals appeared first on AI News.
If you’ve ever thought companies talk more than act when it comes to their AI strategy, a new Cisco report backs you up. It turns out that just 13 percent globally are actually prepared for the AI revolution. However, this small group – which Cisco calls the ‘Pacesetters’ – are lapping the competition. The third
The post Cisco: Only 13% have a solid AI strategy and they’re lapping rivals appeared first on AI News. Read More
Building A Successful Relationship With StakeholdersTowards Data Science Show your value by moving beyond the technical
The post Building A Successful Relationship With Stakeholders appeared first on Towards Data Science.
Show your value by moving beyond the technical
The post Building A Successful Relationship With Stakeholders appeared first on Towards Data Science. Read More
Human Won’t Replace PythonTowards Data Science Why vibe-coding is not a step up from “classic” coding — and why it matters
The post Human Won’t Replace Python appeared first on Towards Data Science.
Why vibe-coding is not a step up from “classic” coding — and why it matters
The post Human Won’t Replace Python appeared first on Towards Data Science. Read More
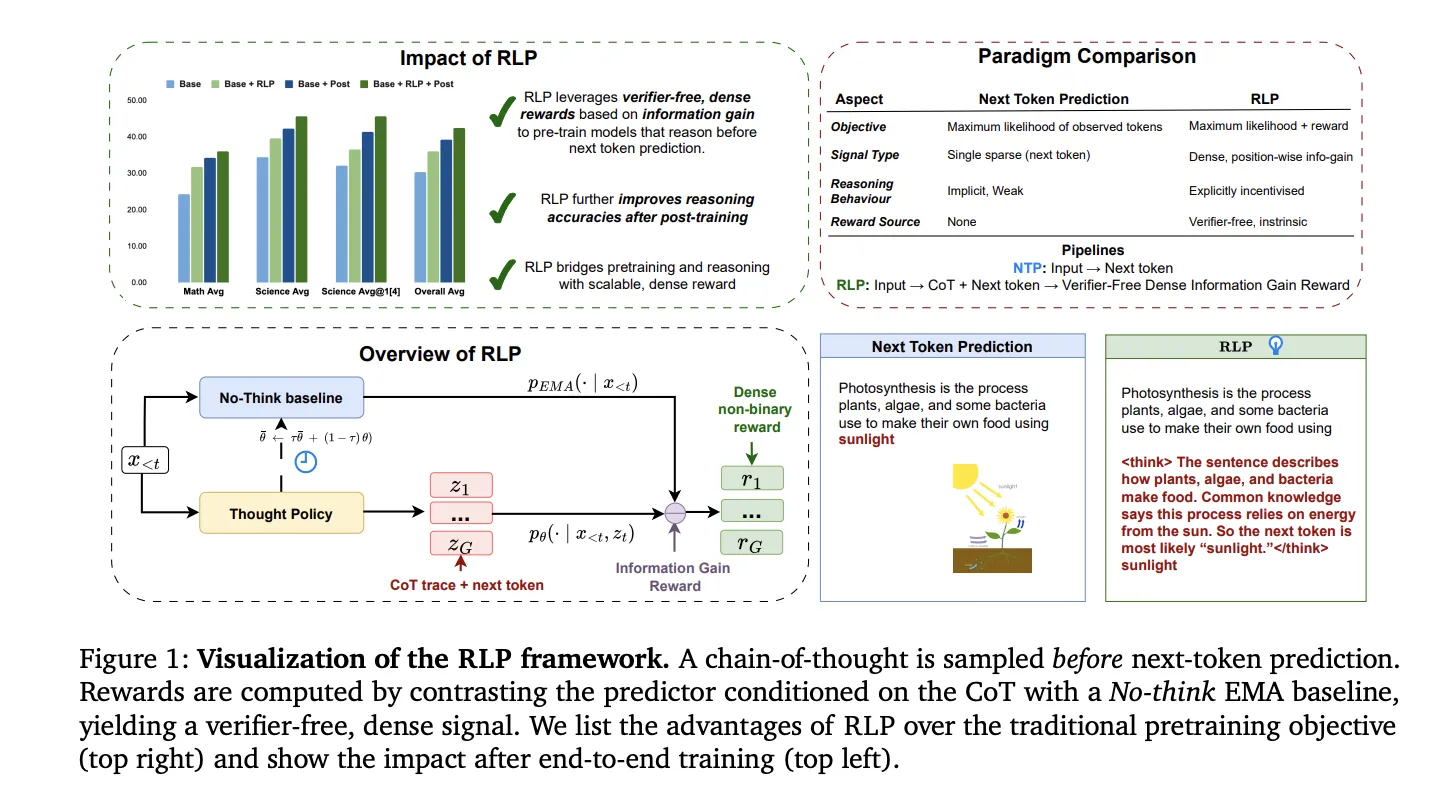
NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During PretrainingMarkTechPost NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather than deferring it to post-training. The core idea is simple and testable: treat a short chain-of-thought (CoT) as an action sampled before next-token prediction and reward it by the information gain it provides on the
The post NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining appeared first on MarkTechPost.
NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather than deferring it to post-training. The core idea is simple and testable: treat a short chain-of-thought (CoT) as an action sampled before next-token prediction and reward it by the information gain it provides on the
The post NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining appeared first on MarkTechPost. Read More
