

SteeringSafety: A Systematic Safety Evaluation Framework of Representation Steering in LLMscs.AI updates on arXiv.org arXiv:2509.13450v2 Announce Type: replace
Abstract: We introduce SteeringSafety, a systematic framework for evaluating representation steering methods across seven safety perspectives spanning 17 datasets. While prior work highlights general capabilities of representation steering, we systematically explore safety perspectives including bias, harmfulness, hallucination, social behaviors, reasoning, epistemic integrity, and normative judgment. Our framework provides modularized building blocks for state-of-the-art steering methods, enabling unified implementation of DIM, ACE, CAA, PCA, and LAT with recent enhancements like conditional steering. Results on Gemma-2-2B, Llama-3.1-8B, and Qwen-2.5-7B reveal that strong steering performance depends critically on pairing of method, model, and specific perspective. DIM shows consistent effectiveness, but all methods exhibit substantial entanglement: social behaviors show highest vulnerability (reaching degradation as high as 76%), jailbreaking often compromises normative judgment, and hallucination steering unpredictably shifts political views. Our findings underscore the critical need for holistic safety evaluations.
arXiv:2509.13450v2 Announce Type: replace
Abstract: We introduce SteeringSafety, a systematic framework for evaluating representation steering methods across seven safety perspectives spanning 17 datasets. While prior work highlights general capabilities of representation steering, we systematically explore safety perspectives including bias, harmfulness, hallucination, social behaviors, reasoning, epistemic integrity, and normative judgment. Our framework provides modularized building blocks for state-of-the-art steering methods, enabling unified implementation of DIM, ACE, CAA, PCA, and LAT with recent enhancements like conditional steering. Results on Gemma-2-2B, Llama-3.1-8B, and Qwen-2.5-7B reveal that strong steering performance depends critically on pairing of method, model, and specific perspective. DIM shows consistent effectiveness, but all methods exhibit substantial entanglement: social behaviors show highest vulnerability (reaching degradation as high as 76%), jailbreaking often compromises normative judgment, and hallucination steering unpredictably shifts political views. Our findings underscore the critical need for holistic safety evaluations. Read More
WithAnyone: Towards Controllable and ID Consistent Image Generationcs.AI updates on arXiv.org arXiv:2510.14975v1 Announce Type: cross
Abstract: Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
arXiv:2510.14975v1 Announce Type: cross
Abstract: Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation. Read More
Reasoning with Sampling: Your Base Model is Smarter Than You Thinkcs.AI updates on arXiv.org arXiv:2510.14901v1 Announce Type: cross
Abstract: Frontier reasoning models have exhibited incredible capabilities across a wide array of disciplines, driven by posttraining large language models (LLMs) with reinforcement learning (RL). However, despite the widespread success of this paradigm, much of the literature has been devoted to disentangling truly novel behaviors that emerge during RL but are not present in the base models. In our work, we approach this question from a different angle, instead asking whether comparable reasoning capabilites can be elicited from base models at inference time by pure sampling, without any additional training. Inspired by Markov chain Monte Carlo (MCMC) techniques for sampling from sharpened distributions, we propose a simple iterative sampling algorithm leveraging the base models’ own likelihoods. Over different base models, we show that our algorithm offers substantial boosts in reasoning that nearly match and even outperform those from RL on a wide variety of single-shot tasks, including MATH500, HumanEval, and GPQA. Moreover, our sampler avoids the collapse in diversity over multiple samples that is characteristic of RL-posttraining. Crucially, our method does not require training, curated datasets, or a verifier, suggesting broad applicability beyond easily verifiable domains.
arXiv:2510.14901v1 Announce Type: cross
Abstract: Frontier reasoning models have exhibited incredible capabilities across a wide array of disciplines, driven by posttraining large language models (LLMs) with reinforcement learning (RL). However, despite the widespread success of this paradigm, much of the literature has been devoted to disentangling truly novel behaviors that emerge during RL but are not present in the base models. In our work, we approach this question from a different angle, instead asking whether comparable reasoning capabilites can be elicited from base models at inference time by pure sampling, without any additional training. Inspired by Markov chain Monte Carlo (MCMC) techniques for sampling from sharpened distributions, we propose a simple iterative sampling algorithm leveraging the base models’ own likelihoods. Over different base models, we show that our algorithm offers substantial boosts in reasoning that nearly match and even outperform those from RL on a wide variety of single-shot tasks, including MATH500, HumanEval, and GPQA. Moreover, our sampler avoids the collapse in diversity over multiple samples that is characteristic of RL-posttraining. Crucially, our method does not require training, curated datasets, or a verifier, suggesting broad applicability beyond easily verifiable domains. Read More
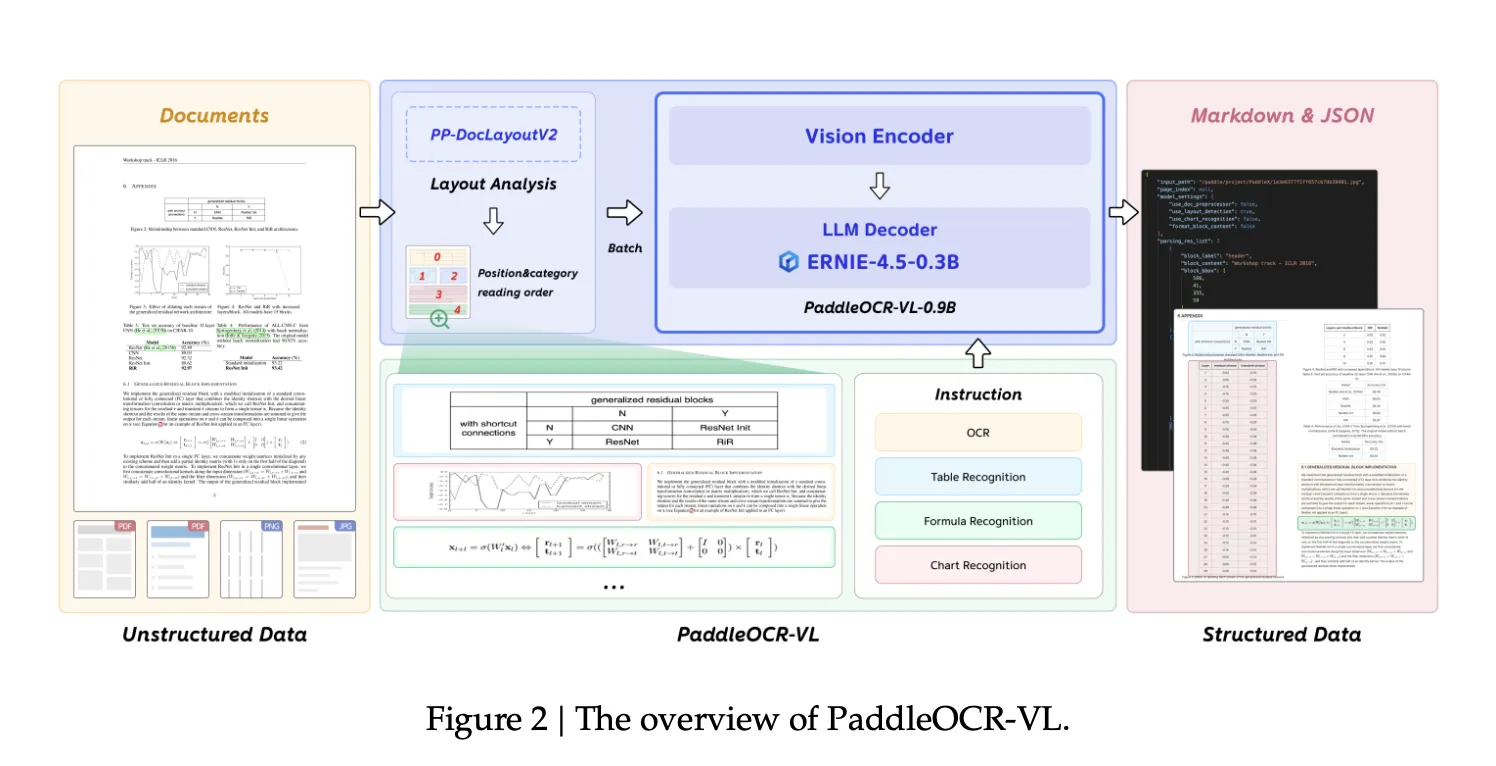
Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document ParsingMarkTechPost How do you convert complex, multilingual documents—dense layouts, small scripts, formulas, charts, and handwriting—into faithful structured Markdown/JSON with state-of-the-art accuracy while keeping inference latency and memory low enough for real deployments?Baidu’s PaddlePaddle group has released PaddleOCR-VL, a 0.9B-parameter vision-language model designed for end-to-end document parsing across text, tables, formulas, charts, and handwriting. The core model
The post Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing appeared first on MarkTechPost.
How do you convert complex, multilingual documents—dense layouts, small scripts, formulas, charts, and handwriting—into faithful structured Markdown/JSON with state-of-the-art accuracy while keeping inference latency and memory low enough for real deployments?Baidu’s PaddlePaddle group has released PaddleOCR-VL, a 0.9B-parameter vision-language model designed for end-to-end document parsing across text, tables, formulas, charts, and handwriting. The core model
The post Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a NaViT-style + ERNIE-4.5-0.3B VLM Targeting End-to-End Multilingual Document Parsing appeared first on MarkTechPost. Read More
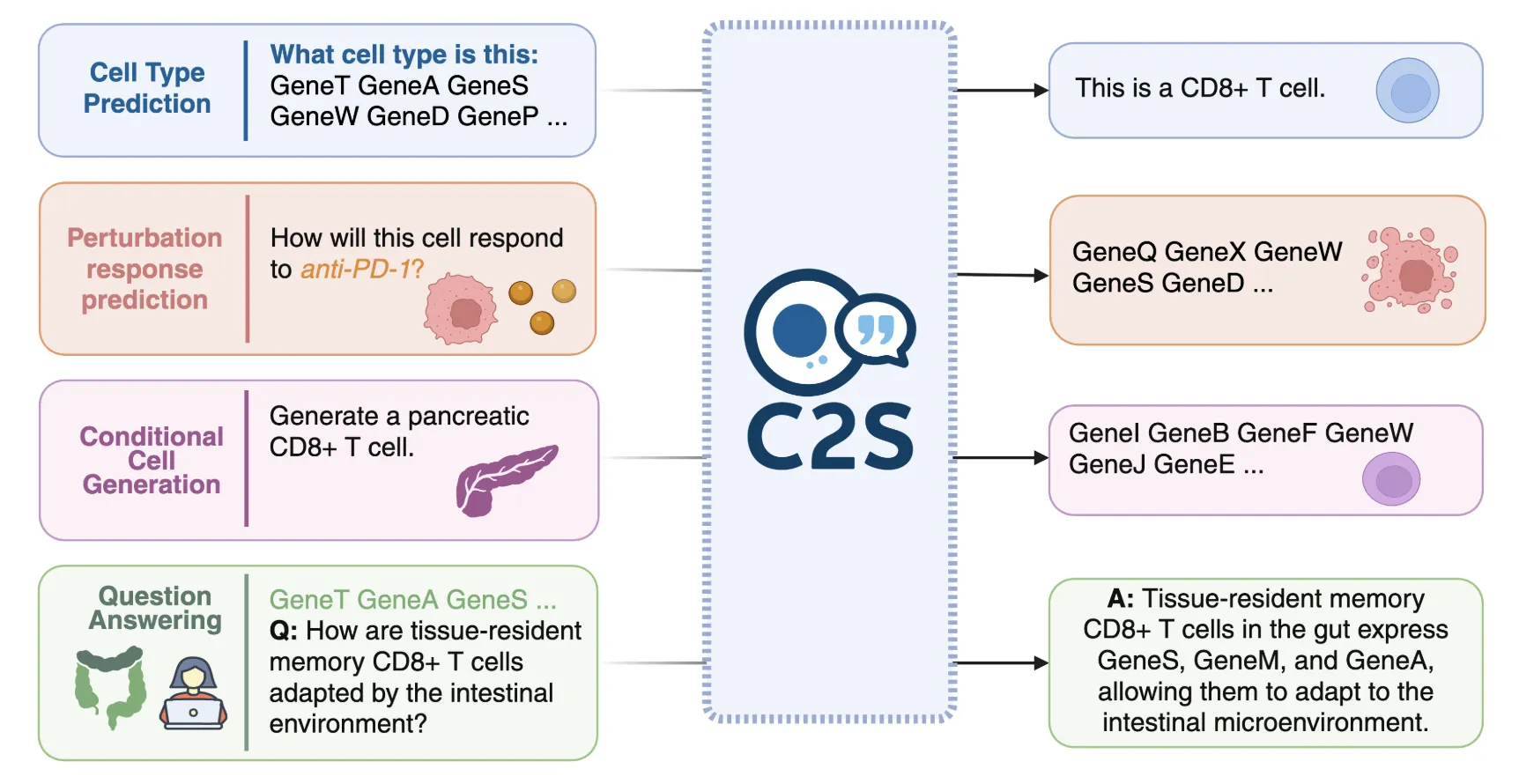
Google AI Releases C2S-Scale 27B Model that Translate Complex Single-Cell Gene Expression Data into ‘cell sentences’ that LLMs can UnderstandMarkTechPost A team of researchers from Google Research, Google DeepMind, and Yale released C2S-Scale 27B, a 27-billion-parameter foundation model for single-cell analysis built on Gemma-2. The model formalizes single-cell RNA-seq (scRNA-seq) profiles as “cell sentences”—ordered lists of gene symbols—so that a language model can natively parse and reason over cellular states. Beyond benchmarking gains, the research
The post Google AI Releases C2S-Scale 27B Model that Translate Complex Single-Cell Gene Expression Data into ‘cell sentences’ that LLMs can Understand appeared first on MarkTechPost.
A team of researchers from Google Research, Google DeepMind, and Yale released C2S-Scale 27B, a 27-billion-parameter foundation model for single-cell analysis built on Gemma-2. The model formalizes single-cell RNA-seq (scRNA-seq) profiles as “cell sentences”—ordered lists of gene symbols—so that a language model can natively parse and reason over cellular states. Beyond benchmarking gains, the research
The post Google AI Releases C2S-Scale 27B Model that Translate Complex Single-Cell Gene Expression Data into ‘cell sentences’ that LLMs can Understand appeared first on MarkTechPost. Read More
Qualifire AI Releases Rogue: An End-to-End Agentic AI Testing Framework, Evaluating the Performance of AI AgentsMarkTechPost Agentic systems are stochastic, context-dependent, and policy-bounded. Conventional QA—unit tests, static prompts, or scalar “LLM-as-a-judge” scores—fails to expose multi-turn vulnerabilities and provides weak audit trails. Developer teams need protocol-accurate conversations, explicit policy checks, and machine-readable evidence that can gate releases with confidence. Qualifire AI has open-sourced Rogue, a Python framework that evaluates AI agents over
The post Qualifire AI Releases Rogue: An End-to-End Agentic AI Testing Framework, Evaluating the Performance of AI Agents appeared first on MarkTechPost.
Agentic systems are stochastic, context-dependent, and policy-bounded. Conventional QA—unit tests, static prompts, or scalar “LLM-as-a-judge” scores—fails to expose multi-turn vulnerabilities and provides weak audit trails. Developer teams need protocol-accurate conversations, explicit policy checks, and machine-readable evidence that can gate releases with confidence. Qualifire AI has open-sourced Rogue, a Python framework that evaluates AI agents over
The post Qualifire AI Releases Rogue: An End-to-End Agentic AI Testing Framework, Evaluating the Performance of AI Agents appeared first on MarkTechPost. Read More
A Coding Guide to Build an AI-Powered Cryptographic Agent System with Hybrid Encryption, Digital Signatures, and Adaptive Security IntelligenceMarkTechPost In this tutorial, we build an AI-powered cryptographic agent system that combines the strength of classical encryption with adaptive intelligence. We design agents capable of performing hybrid encryption with RSA and AES, generating digital signatures, detecting anomalies in message patterns, and intelligently recommending key rotations. As we progress, we witness these autonomous agents securely establish
The post A Coding Guide to Build an AI-Powered Cryptographic Agent System with Hybrid Encryption, Digital Signatures, and Adaptive Security Intelligence appeared first on MarkTechPost.
In this tutorial, we build an AI-powered cryptographic agent system that combines the strength of classical encryption with adaptive intelligence. We design agents capable of performing hybrid encryption with RSA and AES, generating digital signatures, detecting anomalies in message patterns, and intelligently recommending key rotations. As we progress, we witness these autonomous agents securely establish
The post A Coding Guide to Build an AI-Powered Cryptographic Agent System with Hybrid Encryption, Digital Signatures, and Adaptive Security Intelligence appeared first on MarkTechPost. Read More
Big Reasoning with Small Models: Instruction Retrieval at Inference Timecs.AI updates on arXiv.org arXiv:2510.13935v1 Announce Type: cross
Abstract: Can we bring large-scale reasoning to local-scale compute? Small language models (SLMs) are increasingly attractive because they run efficiently on local hardware, offering strong privacy, low cost, and reduced environmental impact. Yet they often struggle with tasks that require multi-step reasoning or domain-specific knowledge. We address this limitation through instruction intervention at inference time, where an SLM retrieves structured reasoning procedures rather than generating them from scratch. Our method builds an Instruction Corpus by grouping similar training questions and creating instructions via GPT-5. During inference, the SLM retrieves the most relevant instructions and follows their steps. Unlike retrieval-augmented generation, which retrieves text passages, instruction retrieval gives the model structured guidance for reasoning. We evaluate this framework on MedQA (medical board exams), MMLU Professional Law, and MathQA using models from 3B to 14B parameters without any additional fine-tuning. Instruction retrieval yields consistent gains: 9.4% on MedQA, 7.9% on MMLU Law, and 5.1% on MathQA. Concise instructions outperform longer ones, and the magnitude of improvement depends strongly on model family and intrinsic reasoning ability.
arXiv:2510.13935v1 Announce Type: cross
Abstract: Can we bring large-scale reasoning to local-scale compute? Small language models (SLMs) are increasingly attractive because they run efficiently on local hardware, offering strong privacy, low cost, and reduced environmental impact. Yet they often struggle with tasks that require multi-step reasoning or domain-specific knowledge. We address this limitation through instruction intervention at inference time, where an SLM retrieves structured reasoning procedures rather than generating them from scratch. Our method builds an Instruction Corpus by grouping similar training questions and creating instructions via GPT-5. During inference, the SLM retrieves the most relevant instructions and follows their steps. Unlike retrieval-augmented generation, which retrieves text passages, instruction retrieval gives the model structured guidance for reasoning. We evaluate this framework on MedQA (medical board exams), MMLU Professional Law, and MathQA using models from 3B to 14B parameters without any additional fine-tuning. Instruction retrieval yields consistent gains: 9.4% on MedQA, 7.9% on MMLU Law, and 5.1% on MathQA. Concise instructions outperform longer ones, and the magnitude of improvement depends strongly on model family and intrinsic reasoning ability. Read More

What if AI is the next dot-com bubble?AI News The surge of multi-billion-dollar investments in AI has sparked growing debate over whether the industry is heading for a bubble similar to the dot-com boom. Investors are watching closely for signs that enthusiasm might be fading or that the heavy spending on infrastructure and chips is failing to deliver expected returns. A recent survey by
The post What if AI is the next dot-com bubble? appeared first on AI News.
The surge of multi-billion-dollar investments in AI has sparked growing debate over whether the industry is heading for a bubble similar to the dot-com boom. Investors are watching closely for signs that enthusiasm might be fading or that the heavy spending on infrastructure and chips is failing to deliver expected returns. A recent survey by
The post What if AI is the next dot-com bubble? appeared first on AI News. Read More
LLMs’ Suitability for Network Security: A Case Study of STRIDE Threat Modelingcs.AI updates on arXiv.org arXiv:2505.04101v2 Announce Type: replace-cross
Abstract: Artificial Intelligence (AI) is expected to be an integral part of next-generation AI-native 6G networks. With the prevalence of AI, researchers have identified numerous use cases of AI in network security. However, there are very few studies that analyze the suitability of Large Language Models (LLMs) in network security. To fill this gap, we examine the suitability of LLMs in network security, particularly with the case study of STRIDE threat modeling. We utilize four prompting techniques with five LLMs to perform STRIDE classification of 5G threats. From our evaluation results, we point out key findings and detailed insights along with the explanation of the possible underlying factors influencing the behavior of LLMs in the modeling of certain threats. The numerical results and the insights support the necessity for adjusting and fine-tuning LLMs for network security use cases.
arXiv:2505.04101v2 Announce Type: replace-cross
Abstract: Artificial Intelligence (AI) is expected to be an integral part of next-generation AI-native 6G networks. With the prevalence of AI, researchers have identified numerous use cases of AI in network security. However, there are very few studies that analyze the suitability of Large Language Models (LLMs) in network security. To fill this gap, we examine the suitability of LLMs in network security, particularly with the case study of STRIDE threat modeling. We utilize four prompting techniques with five LLMs to perform STRIDE classification of 5G threats. From our evaluation results, we point out key findings and detailed insights along with the explanation of the possible underlying factors influencing the behavior of LLMs in the modeling of certain threats. The numerical results and the insights support the necessity for adjusting and fine-tuning LLMs for network security use cases. Read More
