

Flexora: Flexible Low Rank Adaptation for Large Language Modelscs.AI updates on arXiv.org arXiv:2408.10774v5 Announce Type: replace
Abstract: Large Language Models (LLMs) are driving advancements in artificial intelligence by increasing the scale of model parameters, which has significantly enhanced generalization ability and unlocked new capabilities in practice. However, their performance in specific downstream tasks is usually hindered by their knowledge boundaries on these tasks. Thus, fine-tuning techniques, especially the widely used Low-Rank Adaptation (LoRA) method, have been introduced to expand the boundaries on these tasks, whereas LoRA would underperform on certain tasks owing to its potential overfitting on these tasks. To overcome this overfitting and improve the performance of LoRA, we propose the flexible low rank adaptation (Flexora) method to automatically and flexibly select the most important layers needing to be fine-tuned to achieve the best performance on different downstream tasks. Specifically, Flexora firstly frames this layer selection problem as a well-defined hyperparameter optimization (HPO) problem, then addresses it using the unrolled differentiation (UD) method, and finally selects the most useful layers based on the optimized hyperparameters. Our extensive experiments on many pretrained models and natural language tasks show that Flexora is able to consistently improve over the existing baselines, indicating the effectiveness of our Flexora in practice. We additionally provide insightful theoretical results and many ablation studies to deliver a comprehensive understanding of our Flexora.
arXiv:2408.10774v5 Announce Type: replace
Abstract: Large Language Models (LLMs) are driving advancements in artificial intelligence by increasing the scale of model parameters, which has significantly enhanced generalization ability and unlocked new capabilities in practice. However, their performance in specific downstream tasks is usually hindered by their knowledge boundaries on these tasks. Thus, fine-tuning techniques, especially the widely used Low-Rank Adaptation (LoRA) method, have been introduced to expand the boundaries on these tasks, whereas LoRA would underperform on certain tasks owing to its potential overfitting on these tasks. To overcome this overfitting and improve the performance of LoRA, we propose the flexible low rank adaptation (Flexora) method to automatically and flexibly select the most important layers needing to be fine-tuned to achieve the best performance on different downstream tasks. Specifically, Flexora firstly frames this layer selection problem as a well-defined hyperparameter optimization (HPO) problem, then addresses it using the unrolled differentiation (UD) method, and finally selects the most useful layers based on the optimized hyperparameters. Our extensive experiments on many pretrained models and natural language tasks show that Flexora is able to consistently improve over the existing baselines, indicating the effectiveness of our Flexora in practice. We additionally provide insightful theoretical results and many ablation studies to deliver a comprehensive understanding of our Flexora. Read More
AUGUSTUS: An LLM-Driven Multimodal Agent System with Contextualized User Memorycs.AI updates on arXiv.org arXiv:2510.15261v1 Announce Type: new
Abstract: Riding on the success of LLMs with retrieval-augmented generation (RAG), there has been a growing interest in augmenting agent systems with external memory databases. However, the existing systems focus on storing text information in their memory, ignoring the importance of multimodal signals. Motivated by the multimodal nature of human memory, we present AUGUSTUS, a multimodal agent system aligned with the ideas of human memory in cognitive science. Technically, our system consists of 4 stages connected in a loop: (i) encode: understanding the inputs; (ii) store in memory: saving important information; (iii) retrieve: searching for relevant context from memory; and (iv) act: perform the task. Unlike existing systems that use vector databases, we propose conceptualizing information into semantic tags and associating the tags with their context to store them in a graph-structured multimodal contextual memory for efficient concept-driven retrieval. Our system outperforms the traditional multimodal RAG approach while being 3.5 times faster for ImageNet classification and outperforming MemGPT on the MSC benchmark.
arXiv:2510.15261v1 Announce Type: new
Abstract: Riding on the success of LLMs with retrieval-augmented generation (RAG), there has been a growing interest in augmenting agent systems with external memory databases. However, the existing systems focus on storing text information in their memory, ignoring the importance of multimodal signals. Motivated by the multimodal nature of human memory, we present AUGUSTUS, a multimodal agent system aligned with the ideas of human memory in cognitive science. Technically, our system consists of 4 stages connected in a loop: (i) encode: understanding the inputs; (ii) store in memory: saving important information; (iii) retrieve: searching for relevant context from memory; and (iv) act: perform the task. Unlike existing systems that use vector databases, we propose conceptualizing information into semantic tags and associating the tags with their context to store them in a graph-structured multimodal contextual memory for efficient concept-driven retrieval. Our system outperforms the traditional multimodal RAG approach while being 3.5 times faster for ImageNet classification and outperforming MemGPT on the MSC benchmark. Read More
Experience-Driven Exploration for Efficient API-Free AI Agentscs.AI updates on arXiv.org arXiv:2510.15259v1 Announce Type: new
Abstract: Most existing software lacks accessible Application Programming Interfaces (APIs), requiring agents to operate solely through pixel-based Graphical User Interfaces (GUIs). In this API-free setting, large language model (LLM)-based agents face severe efficiency bottlenecks: limited to local visual experiences, they make myopic decisions and rely on inefficient trial-and-error, hindering both skill acquisition and long-term planning. To address these challenges, we propose KG-Agent, an experience-driven learning framework that structures an agent’s raw pixel-level interactions into a persistent State-Action Knowledge Graph (SA-KG). KG-Agent overcomes inefficient exploration by linking functionally similar but visually distinct GUI states, forming a rich neighborhood of experience that enables the agent to generalize from a diverse set of historical strategies. To support long-horizon reasoning, we design a hybrid intrinsic reward mechanism based on the graph topology, combining a state value reward for exploiting known high-value pathways with a novelty reward that encourages targeted exploration. This approach decouples strategic planning from pure discovery, allowing the agent to effectively value setup actions with delayed gratification. We evaluate KG-Agent in two complex, open-ended GUI-based decision-making environments (Civilization V and Slay the Spire), demonstrating significant improvements in exploration efficiency and strategic depth over the state-of-the-art methods.
arXiv:2510.15259v1 Announce Type: new
Abstract: Most existing software lacks accessible Application Programming Interfaces (APIs), requiring agents to operate solely through pixel-based Graphical User Interfaces (GUIs). In this API-free setting, large language model (LLM)-based agents face severe efficiency bottlenecks: limited to local visual experiences, they make myopic decisions and rely on inefficient trial-and-error, hindering both skill acquisition and long-term planning. To address these challenges, we propose KG-Agent, an experience-driven learning framework that structures an agent’s raw pixel-level interactions into a persistent State-Action Knowledge Graph (SA-KG). KG-Agent overcomes inefficient exploration by linking functionally similar but visually distinct GUI states, forming a rich neighborhood of experience that enables the agent to generalize from a diverse set of historical strategies. To support long-horizon reasoning, we design a hybrid intrinsic reward mechanism based on the graph topology, combining a state value reward for exploiting known high-value pathways with a novelty reward that encourages targeted exploration. This approach decouples strategic planning from pure discovery, allowing the agent to effectively value setup actions with delayed gratification. We evaluate KG-Agent in two complex, open-ended GUI-based decision-making environments (Civilization V and Slay the Spire), demonstrating significant improvements in exploration efficiency and strategic depth over the state-of-the-art methods. Read More
HumorDB: Can AI understand graphical humor?cs.AI updates on arXiv.org arXiv:2406.13564v3 Announce Type: replace-cross
Abstract: Despite significant advancements in image segmentation and object detection, understanding complex scenes remains a significant challenge. Here, we focus on graphical humor as a paradigmatic example of image interpretation that requires elucidating the interaction of different scene elements in the context of prior cognitive knowledge. This paper introduces textbf{HumorDB}, a novel, controlled, and carefully curated dataset designed to evaluate and advance visual humor understanding by AI systems. The dataset comprises diverse images spanning photos, cartoons, sketches, and AI-generated content, including minimally contrastive pairs where subtle edits differentiate between humorous and non-humorous versions. We evaluate humans, state-of-the-art vision models, and large vision-language models on three tasks: binary humor classification, funniness rating prediction, and pairwise humor comparison. The results reveal a gap between current AI systems and human-level humor understanding. While pretrained vision-language models perform better than vision-only models, they still struggle with abstract sketches and subtle humor cues. Analysis of attention maps shows that even when models correctly classify humorous images, they often fail to focus on the precise regions that make the image funny. Preliminary mechanistic interpretability studies and evaluation of model explanations provide initial insights into how different architectures process humor. Our results identify promising trends and current limitations, suggesting that an effective understanding of visual humor requires sophisticated architectures capable of detecting subtle contextual features and bridging the gap between visual perception and abstract reasoning. All the code and data are available here: href{https://github.com/kreimanlab/HumorDB}{https://github.com/kreimanlab/HumorDB}
arXiv:2406.13564v3 Announce Type: replace-cross
Abstract: Despite significant advancements in image segmentation and object detection, understanding complex scenes remains a significant challenge. Here, we focus on graphical humor as a paradigmatic example of image interpretation that requires elucidating the interaction of different scene elements in the context of prior cognitive knowledge. This paper introduces textbf{HumorDB}, a novel, controlled, and carefully curated dataset designed to evaluate and advance visual humor understanding by AI systems. The dataset comprises diverse images spanning photos, cartoons, sketches, and AI-generated content, including minimally contrastive pairs where subtle edits differentiate between humorous and non-humorous versions. We evaluate humans, state-of-the-art vision models, and large vision-language models on three tasks: binary humor classification, funniness rating prediction, and pairwise humor comparison. The results reveal a gap between current AI systems and human-level humor understanding. While pretrained vision-language models perform better than vision-only models, they still struggle with abstract sketches and subtle humor cues. Analysis of attention maps shows that even when models correctly classify humorous images, they often fail to focus on the precise regions that make the image funny. Preliminary mechanistic interpretability studies and evaluation of model explanations provide initial insights into how different architectures process humor. Our results identify promising trends and current limitations, suggesting that an effective understanding of visual humor requires sophisticated architectures capable of detecting subtle contextual features and bridging the gap between visual perception and abstract reasoning. All the code and data are available here: href{https://github.com/kreimanlab/HumorDB}{https://github.com/kreimanlab/HumorDB} Read More
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLMcs.AI updates on arXiv.org arXiv:2510.15870v1 Announce Type: cross
Abstract: Advancing machine intelligence requires developing the ability to perceive across multiple modalities, much as humans sense the world. We introduce OmniVinci, an initiative to build a strong, open-source, omni-modal LLM. We carefully study the design choices across model architecture and data curation. For model architecture, we present three key innovations: (i) OmniAlignNet for strengthening alignment between vision and audio embeddings in a shared omni-modal latent space; (ii) Temporal Embedding Grouping for capturing relative temporal alignment between vision and audio signals; and (iii) Constrained Rotary Time Embedding for encoding absolute temporal information in omni-modal embeddings. We introduce a curation and synthesis pipeline that generates 24M single-modal and omni-modal conversations. We find that modalities reinforce one another in both perception and reasoning. Our model, OmniVinci, outperforms Qwen2.5-Omni with +19.05 on DailyOmni (cross-modal understanding), +1.7 on MMAR (audio), and +3.9 on Video-MME (vision), while using just 0.2T training tokens – a 6 times reduction compared to Qwen2.5-Omni’s 1.2T. We finally demonstrate omni-modal advantages in downstream applications spanning robotics, medical AI, and smart factory.
arXiv:2510.15870v1 Announce Type: cross
Abstract: Advancing machine intelligence requires developing the ability to perceive across multiple modalities, much as humans sense the world. We introduce OmniVinci, an initiative to build a strong, open-source, omni-modal LLM. We carefully study the design choices across model architecture and data curation. For model architecture, we present three key innovations: (i) OmniAlignNet for strengthening alignment between vision and audio embeddings in a shared omni-modal latent space; (ii) Temporal Embedding Grouping for capturing relative temporal alignment between vision and audio signals; and (iii) Constrained Rotary Time Embedding for encoding absolute temporal information in omni-modal embeddings. We introduce a curation and synthesis pipeline that generates 24M single-modal and omni-modal conversations. We find that modalities reinforce one another in both perception and reasoning. Our model, OmniVinci, outperforms Qwen2.5-Omni with +19.05 on DailyOmni (cross-modal understanding), +1.7 on MMAR (audio), and +3.9 on Video-MME (vision), while using just 0.2T training tokens – a 6 times reduction compared to Qwen2.5-Omni’s 1.2T. We finally demonstrate omni-modal advantages in downstream applications spanning robotics, medical AI, and smart factory. Read More
DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speechcs.AI updates on arXiv.org arXiv:2505.19687v2 Announce Type: replace-cross
Abstract: Cross-speaker emotion transfer in speech synthesis relies on extracting speaker-independent emotion embeddings for accurate emotion modeling without retaining speaker traits. However, existing timbre compression methods fail to fully separate speaker and emotion characteristics, causing speaker leakage and degraded synthesis quality. To address this, we propose DiEmo-TTS, a self-supervised distillation method to minimize emotional information loss and preserve speaker identity. We introduce cluster-driven sampling and information perturbation to preserve emotion while removing irrelevant factors. To facilitate this process, we propose an emotion clustering and matching approach using emotional attribute prediction and speaker embeddings, enabling generalization to unlabeled data. Additionally, we designed a dual conditioning transformer to integrate style features better. Experimental results confirm the effectiveness of our method in learning speaker-irrelevant emotion embeddings.
arXiv:2505.19687v2 Announce Type: replace-cross
Abstract: Cross-speaker emotion transfer in speech synthesis relies on extracting speaker-independent emotion embeddings for accurate emotion modeling without retaining speaker traits. However, existing timbre compression methods fail to fully separate speaker and emotion characteristics, causing speaker leakage and degraded synthesis quality. To address this, we propose DiEmo-TTS, a self-supervised distillation method to minimize emotional information loss and preserve speaker identity. We introduce cluster-driven sampling and information perturbation to preserve emotion while removing irrelevant factors. To facilitate this process, we propose an emotion clustering and matching approach using emotional attribute prediction and speaker embeddings, enabling generalization to unlabeled data. Additionally, we designed a dual conditioning transformer to integrate style features better. Experimental results confirm the effectiveness of our method in learning speaker-irrelevant emotion embeddings. Read More
An Implementation to Build Dynamic AI Systems with the Model Context Protocol (MCP) for Real-Time Resource and Tool IntegrationMarkTechPost In this tutorial, we explore the Advanced Model Context Protocol (MCP) and demonstrate how to use it to address one of the most unique challenges in modern AI systems: enabling real-time interaction between AI models and external data or tools. Traditional models operate in isolation, limited to their training data, but through MCP, we create
The post An Implementation to Build Dynamic AI Systems with the Model Context Protocol (MCP) for Real-Time Resource and Tool Integration appeared first on MarkTechPost.
In this tutorial, we explore the Advanced Model Context Protocol (MCP) and demonstrate how to use it to address one of the most unique challenges in modern AI systems: enabling real-time interaction between AI models and external data or tools. Traditional models operate in isolation, limited to their training data, but through MCP, we create
The post An Implementation to Build Dynamic AI Systems with the Model Context Protocol (MCP) for Real-Time Resource and Tool Integration appeared first on MarkTechPost. Read More
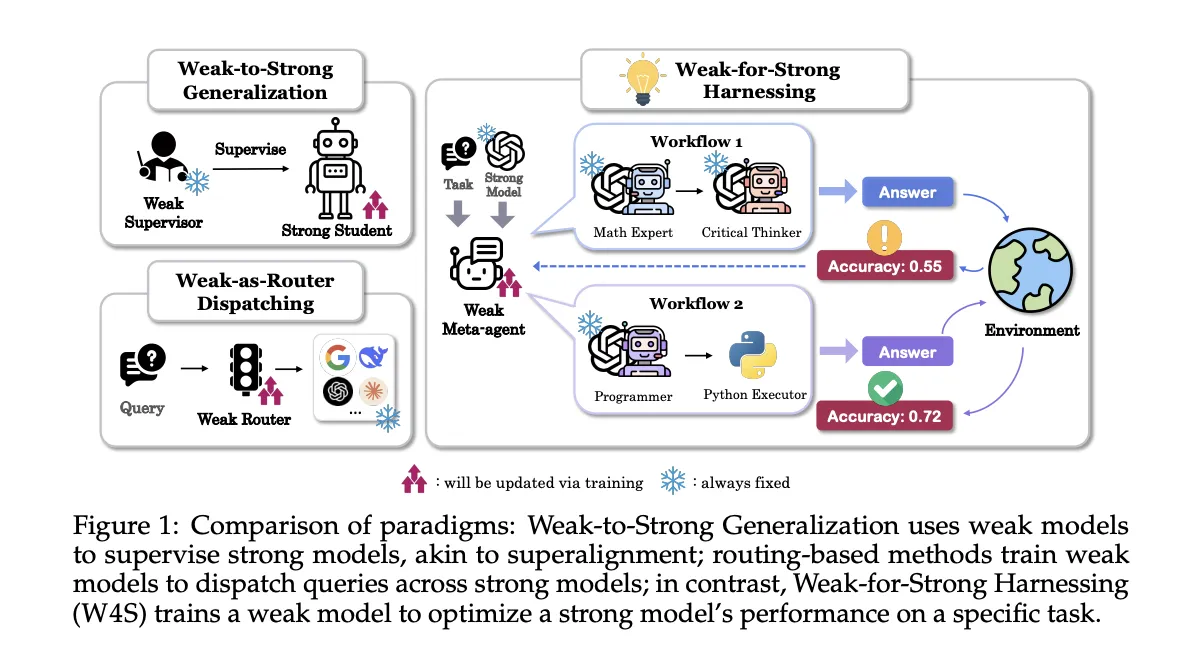
Weak-for-Strong (W4S): A Novel Reinforcement Learning Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMsMarkTechPost Researchers from Stanford, EPFL, and UNC introduce Weak-for-Strong Harnessing, W4S, a new Reinforcement Learning RL framework that trains a small meta-agent to design and refine code workflows that call a stronger executor model. The meta-agent does not fine tune the strong model, it learns to orchestrate it. W4S formalizes workflow design as a multi turn
The post Weak-for-Strong (W4S): A Novel Reinforcement Learning Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMs appeared first on MarkTechPost.
Researchers from Stanford, EPFL, and UNC introduce Weak-for-Strong Harnessing, W4S, a new Reinforcement Learning RL framework that trains a small meta-agent to design and refine code workflows that call a stronger executor model. The meta-agent does not fine tune the strong model, it learns to orchestrate it. W4S formalizes workflow design as a multi turn
The post Weak-for-Strong (W4S): A Novel Reinforcement Learning Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMs appeared first on MarkTechPost. Read More
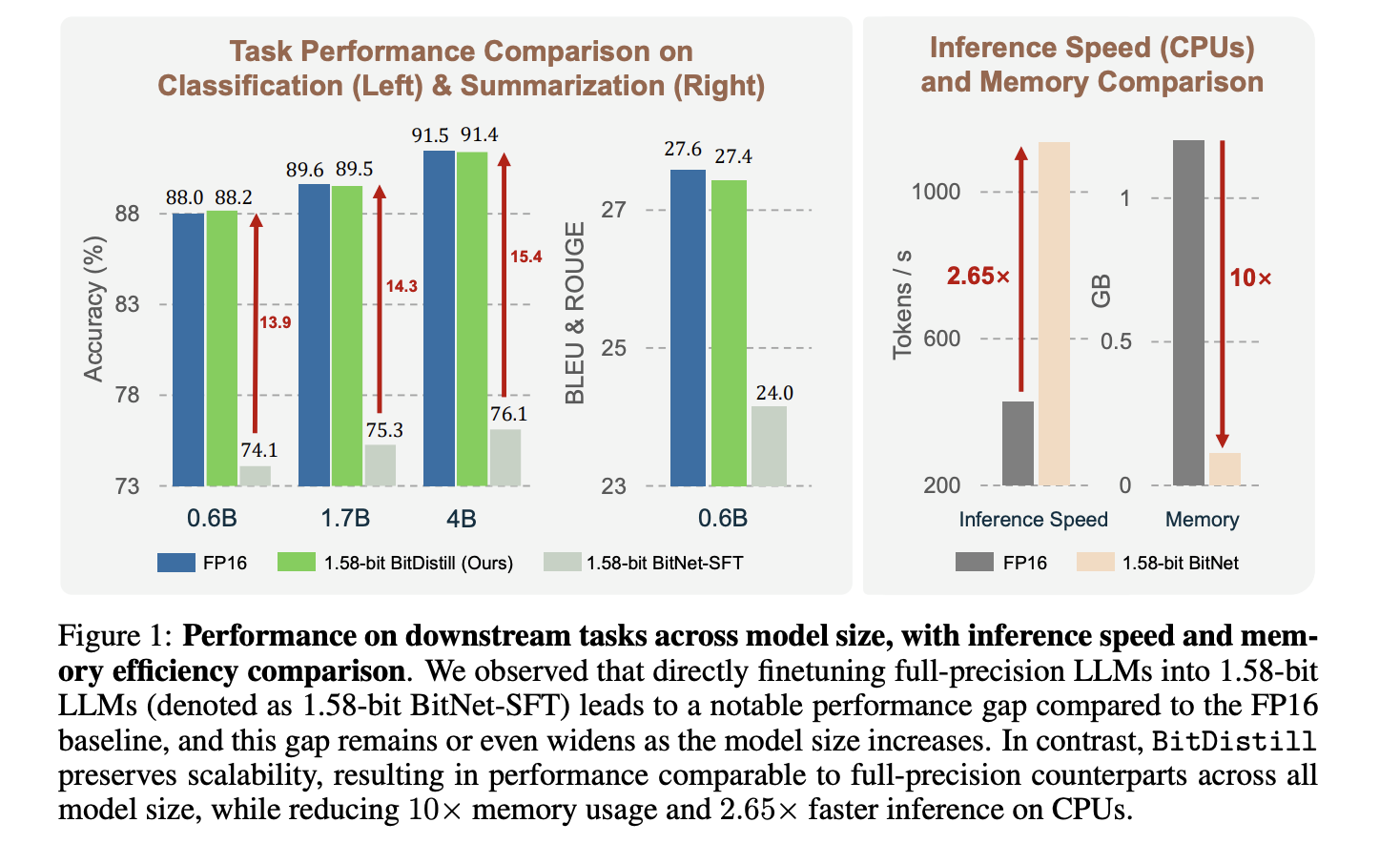
Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU SpeedupMarkTechPost Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific tasks, while keeping accuracy close to the FP16 teacher and improving CPU efficiency. The method combines SubLN based architectural refinement, continued pre training, and dual signal distillation from logits and multi head attention relations. Reported
The post Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU Speedup appeared first on MarkTechPost.
Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific tasks, while keeping accuracy close to the FP16 teacher and improving CPU efficiency. The method combines SubLN based architectural refinement, continued pre training, and dual signal distillation from logits and multi head attention relations. Reported
The post Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU Speedup appeared first on MarkTechPost. Read More
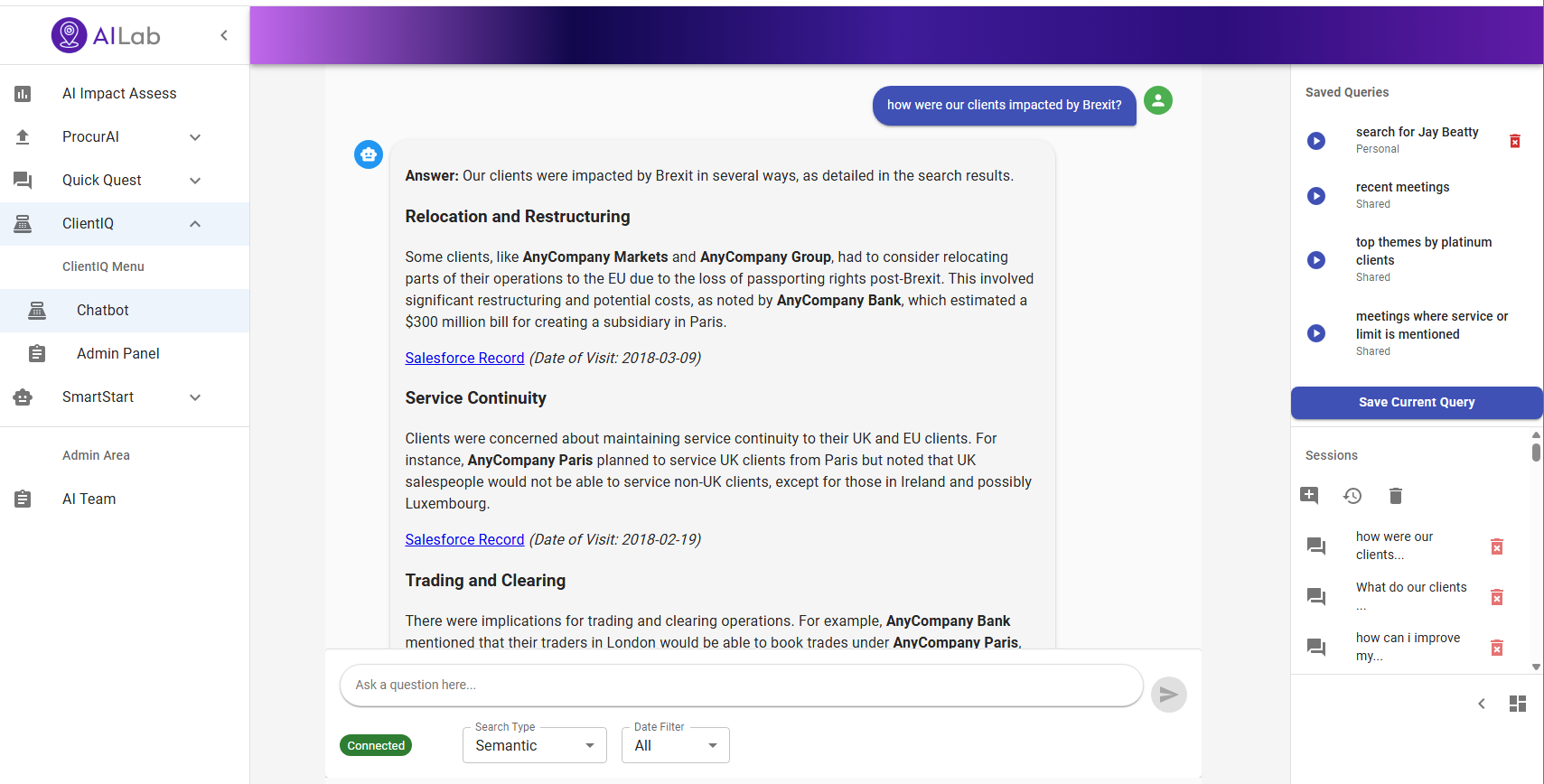
How TP ICAP transformed CRM data into real-time insights with Amazon Bedrock Artificial Intelligence
How TP ICAP transformed CRM data into real-time insights with Amazon BedrockArtificial Intelligence This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value.
This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value. Read More
