
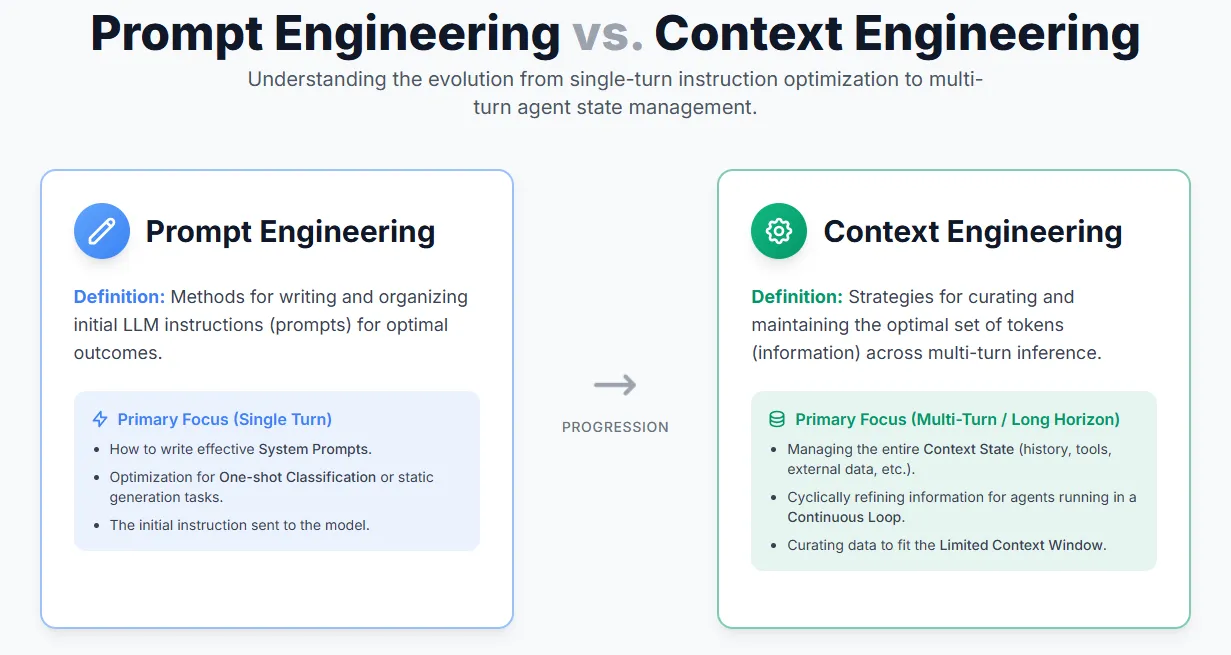
A Guide for Effective Context Engineering for AI AgentsMarkTechPost Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost.
Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost. Read More

Learning to Interpret Weight Differences in Language Modelscs.AI updates on arXiv.org arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions.
arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions. Read More
Changing Base Without Losing Pace: A GPU-Efficient Alternative to MatMul in DNNscs.AI updates on arXiv.org arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI.
arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI. Read More
AppCopilot: Toward General, Accurate, Long-Horizon, and Efficient Mobile Agentcs.AI updates on arXiv.org arXiv:2509.02444v2 Announce Type: replace
Abstract: With the raid evolution of large language models and multimodal models, the mobile-agent landscape has proliferated without converging on the fundamental challenges. This paper identifies four core problems that should be solved for mobile agents to deliver practical, scalable impact: (1) generalization across tasks, APPs, and devices; (2) accuracy, specifically precise on-screen interaction and click targeting; (3) long-horizon capability for sustained, multi-step goals; and (4) efficiency, specifically high-performance runtime on resource-constrained devices. We present AppCopilot, a multimodal, multi-agent, general-purpose mobile agent that operates across applications. AppCopilot operationalizes this position through an end-to-end pipeline spanning data collection, training, finetuning, efficient inference, and PC/mobile application. At the model layer, it integrates multimodal foundation models with robust Chinese-English support. At the reasoning and control layer, it combines chain-of-thought reasoning, hierarchical task planning and decomposition, and multi-agent collaboration. At the execution layer, it enables experiential adaptation, voice interaction, function calling, cross-APP and cross-device orchestration, and comprehensive mobile APP support. The system design incorporates profiling-driven optimization for latency and memory across heterogeneous hardware. Empirically, AppCopilot achieves significant improvements on four dimensions: stronger generalization, higher precision of on screen actions, more reliable long horizon task completion, and faster, more resource efficient runtime. By articulating a cohesive position and a reference architecture that closes the loop from data collection, training to finetuning and efficient inference, this paper offers a concrete roadmap for general purpose mobile agent and provides actionable guidance.
arXiv:2509.02444v2 Announce Type: replace
Abstract: With the raid evolution of large language models and multimodal models, the mobile-agent landscape has proliferated without converging on the fundamental challenges. This paper identifies four core problems that should be solved for mobile agents to deliver practical, scalable impact: (1) generalization across tasks, APPs, and devices; (2) accuracy, specifically precise on-screen interaction and click targeting; (3) long-horizon capability for sustained, multi-step goals; and (4) efficiency, specifically high-performance runtime on resource-constrained devices. We present AppCopilot, a multimodal, multi-agent, general-purpose mobile agent that operates across applications. AppCopilot operationalizes this position through an end-to-end pipeline spanning data collection, training, finetuning, efficient inference, and PC/mobile application. At the model layer, it integrates multimodal foundation models with robust Chinese-English support. At the reasoning and control layer, it combines chain-of-thought reasoning, hierarchical task planning and decomposition, and multi-agent collaboration. At the execution layer, it enables experiential adaptation, voice interaction, function calling, cross-APP and cross-device orchestration, and comprehensive mobile APP support. The system design incorporates profiling-driven optimization for latency and memory across heterogeneous hardware. Empirically, AppCopilot achieves significant improvements on four dimensions: stronger generalization, higher precision of on screen actions, more reliable long horizon task completion, and faster, more resource efficient runtime. By articulating a cohesive position and a reference architecture that closes the loop from data collection, training to finetuning and efficient inference, this paper offers a concrete roadmap for general purpose mobile agent and provides actionable guidance. Read More

5 Docker Containers for Your AI InfrastructureKDnuggets Below are five of the most useful Docker containers that can help you build a powerful AI infrastructure in 2026, without the need to wrestle with environment mismatches or missing dependencies.
Below are five of the most useful Docker containers that can help you build a powerful AI infrastructure in 2026, without the need to wrestle with environment mismatches or missing dependencies. Read More
How to Build Guardrails for Effective AgentsTowards Data Science Learn how to set up effective guardrails to enforce desired behaviour from your agents
The post How to Build Guardrails for Effective Agents appeared first on Towards Data Science.
Learn how to set up effective guardrails to enforce desired behaviour from your agents
The post How to Build Guardrails for Effective Agents appeared first on Towards Data Science. Read More
What Layers When: Learning to Skip Compute in LLMs with Residual Gatescs.AI updates on arXiv.org arXiv:2510.13876v2 Announce Type: replace-cross
Abstract: We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch’s output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding.
arXiv:2510.13876v2 Announce Type: replace-cross
Abstract: We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch’s output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding. Read More
Ascent Fails to Forgetcs.AI updates on arXiv.org arXiv:2509.26427v2 Announce Type: replace-cross
Abstract: Contrary to common belief, we show that gradient ascent-based unconstrained optimization methods frequently fail to perform machine unlearning, a phenomenon we attribute to the inherent statistical dependence between the forget and retain data sets. This dependence, which can manifest itself even as simple correlations, undermines the misconception that these sets can be independently manipulated during unlearning. We provide empirical and theoretical evidence showing these methods often fail precisely due to this overlooked relationship. For random forget sets, this dependence means that degrading forget set metrics (which, for a retrained model, should mirror test set metrics) inevitably harms overall test performance. Going beyond random sets, we consider logistic regression as an instructive example where a critical failure mode emerges: inter-set dependence causes gradient descent-ascent iterations to progressively diverge from the ideal retrained model. Strikingly, these methods can converge to solutions that are not only far from the retrained ideal but are potentially even further from it than the original model itself, rendering the unlearning process actively detrimental. A toy example further illustrates how this dependence can trap models in inferior local minima, inescapable via finetuning. Our findings highlight that the presence of such statistical dependencies, even when manifest only as correlations, can be sufficient for ascent-based unlearning to fail. Our theoretical insights are corroborated by experiments on complex neural networks, demonstrating that these methods do not perform as expected in practice due to this unaddressed statistical interplay.
arXiv:2509.26427v2 Announce Type: replace-cross
Abstract: Contrary to common belief, we show that gradient ascent-based unconstrained optimization methods frequently fail to perform machine unlearning, a phenomenon we attribute to the inherent statistical dependence between the forget and retain data sets. This dependence, which can manifest itself even as simple correlations, undermines the misconception that these sets can be independently manipulated during unlearning. We provide empirical and theoretical evidence showing these methods often fail precisely due to this overlooked relationship. For random forget sets, this dependence means that degrading forget set metrics (which, for a retrained model, should mirror test set metrics) inevitably harms overall test performance. Going beyond random sets, we consider logistic regression as an instructive example where a critical failure mode emerges: inter-set dependence causes gradient descent-ascent iterations to progressively diverge from the ideal retrained model. Strikingly, these methods can converge to solutions that are not only far from the retrained ideal but are potentially even further from it than the original model itself, rendering the unlearning process actively detrimental. A toy example further illustrates how this dependence can trap models in inferior local minima, inescapable via finetuning. Our findings highlight that the presence of such statistical dependencies, even when manifest only as correlations, can be sufficient for ascent-based unlearning to fail. Our theoretical insights are corroborated by experiments on complex neural networks, demonstrating that these methods do not perform as expected in practice due to this unaddressed statistical interplay. Read More
CLASP: General-Purpose Clothes Manipulation with Semantic Keypointscs.AI updates on arXiv.org arXiv:2507.19983v2 Announce Type: replace-cross
Abstract: Clothes manipulation, such as folding or hanging, is a critical capability for home service robots. Despite recent advances, most existing methods remain limited to specific clothes types and tasks, due to the complex, high-dimensional geometry of clothes. This paper presents CLothes mAnipulation with Semantic keyPoints (CLASP), which aims at general-purpose clothes manipulation over diverse clothes types, T-shirts, shorts, skirts, long dresses, …, as well as different tasks, folding, flattening, hanging, …. The core idea of CLASP is semantic keypoints-e.g., ”left sleeve” and ”right shoulder”-a sparse spatial-semantic representation, salient for both perception and action. Semantic keypoints of clothes can be reliably extracted from RGB-D images and provide an effective representation for a wide range of clothes manipulation policies. CLASP uses semantic keypoints as an intermediate representation to connect high-level task planning and low-level action execution. At the high level, it exploits vision language models (VLMs) to predict task plans over the semantic keypoints. At the low level, it executes the plans with the help of a set of pre-built manipulation skills conditioned on the keypoints. Extensive simulation experiments show that CLASP outperforms state-of-the-art baseline methods on multiple tasks across diverse clothes types, demonstrating strong performance and generalization. Further experiments with a Franka dual-arm system on four distinct tasks-folding, flattening, hanging, and placing-confirm CLASP’s performance on real-life clothes manipulation.
arXiv:2507.19983v2 Announce Type: replace-cross
Abstract: Clothes manipulation, such as folding or hanging, is a critical capability for home service robots. Despite recent advances, most existing methods remain limited to specific clothes types and tasks, due to the complex, high-dimensional geometry of clothes. This paper presents CLothes mAnipulation with Semantic keyPoints (CLASP), which aims at general-purpose clothes manipulation over diverse clothes types, T-shirts, shorts, skirts, long dresses, …, as well as different tasks, folding, flattening, hanging, …. The core idea of CLASP is semantic keypoints-e.g., ”left sleeve” and ”right shoulder”-a sparse spatial-semantic representation, salient for both perception and action. Semantic keypoints of clothes can be reliably extracted from RGB-D images and provide an effective representation for a wide range of clothes manipulation policies. CLASP uses semantic keypoints as an intermediate representation to connect high-level task planning and low-level action execution. At the high level, it exploits vision language models (VLMs) to predict task plans over the semantic keypoints. At the low level, it executes the plans with the help of a set of pre-built manipulation skills conditioned on the keypoints. Extensive simulation experiments show that CLASP outperforms state-of-the-art baseline methods on multiple tasks across diverse clothes types, demonstrating strong performance and generalization. Further experiments with a Franka dual-arm system on four distinct tasks-folding, flattening, hanging, and placing-confirm CLASP’s performance on real-life clothes manipulation. Read More
EmoSphere-SER: Enhancing Speech Emotion Recognition Through Spherical Representation with Auxiliary Classificationcs.AI updates on arXiv.org arXiv:2505.19693v2 Announce Type: replace-cross
Abstract: Speech emotion recognition predicts a speaker’s emotional state from speech signals using discrete labels or continuous dimensions such as arousal, valence, and dominance (VAD). We propose EmoSphere-SER, a joint model that integrates spherical VAD region classification to guide VAD regression for improved emotion prediction. In our framework, VAD values are transformed into spherical coordinates that are divided into multiple spherical regions, and an auxiliary classification task predicts which spherical region each point belongs to, guiding the regression process. Additionally, we incorporate a dynamic weighting scheme and a style pooling layer with multi-head self-attention to capture spectral and temporal dynamics, further boosting performance. This combined training strategy reinforces structured learning and improves prediction consistency. Experimental results show that our approach exceeds baseline methods, confirming the validity of the proposed framework.
arXiv:2505.19693v2 Announce Type: replace-cross
Abstract: Speech emotion recognition predicts a speaker’s emotional state from speech signals using discrete labels or continuous dimensions such as arousal, valence, and dominance (VAD). We propose EmoSphere-SER, a joint model that integrates spherical VAD region classification to guide VAD regression for improved emotion prediction. In our framework, VAD values are transformed into spherical coordinates that are divided into multiple spherical regions, and an auxiliary classification task predicts which spherical region each point belongs to, guiding the regression process. Additionally, we incorporate a dynamic weighting scheme and a style pooling layer with multi-head self-attention to capture spectral and temporal dynamics, further boosting performance. This combined training strategy reinforces structured learning and improves prediction consistency. Experimental results show that our approach exceeds baseline methods, confirming the validity of the proposed framework. Read More
