

Graph RAG vs SQL RAGTowards Data Science Evaluating RAGs on graph and SQL databases
The post Graph RAG vs SQL RAG appeared first on Towards Data Science.
Evaluating RAGs on graph and SQL databases
The post Graph RAG vs SQL RAG appeared first on Towards Data Science. Read More
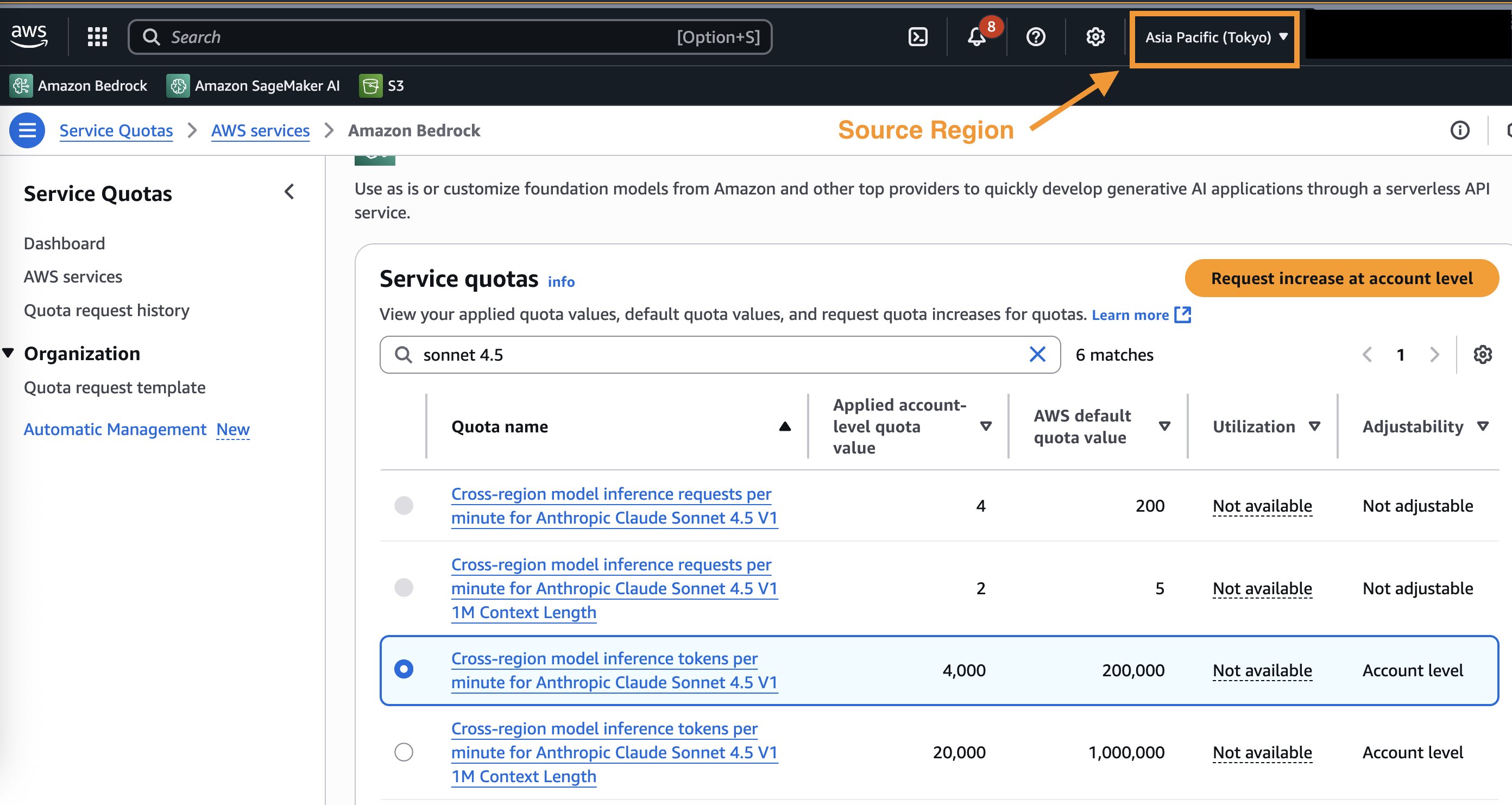
Introducing Amazon Bedrock cross-Region inference for Claude Sonnet 4.5 and Haiku 4.5 in Japan and AustraliaArtificial Intelligence こんにちは, G’day. The recent launch of Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5, now available on Amazon Bedrock, marks a significant leap forward in generative AI models. These state-of-the-art models excel at complex agentic tasks, coding, and enterprise workloads, offering enhanced capabilities to developers. Along with the new models, we are thrilled to announce that
こんにちは, G’day. The recent launch of Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5, now available on Amazon Bedrock, marks a significant leap forward in generative AI models. These state-of-the-art models excel at complex agentic tasks, coding, and enterprise workloads, offering enhanced capabilities to developers. Along with the new models, we are thrilled to announce that Read More
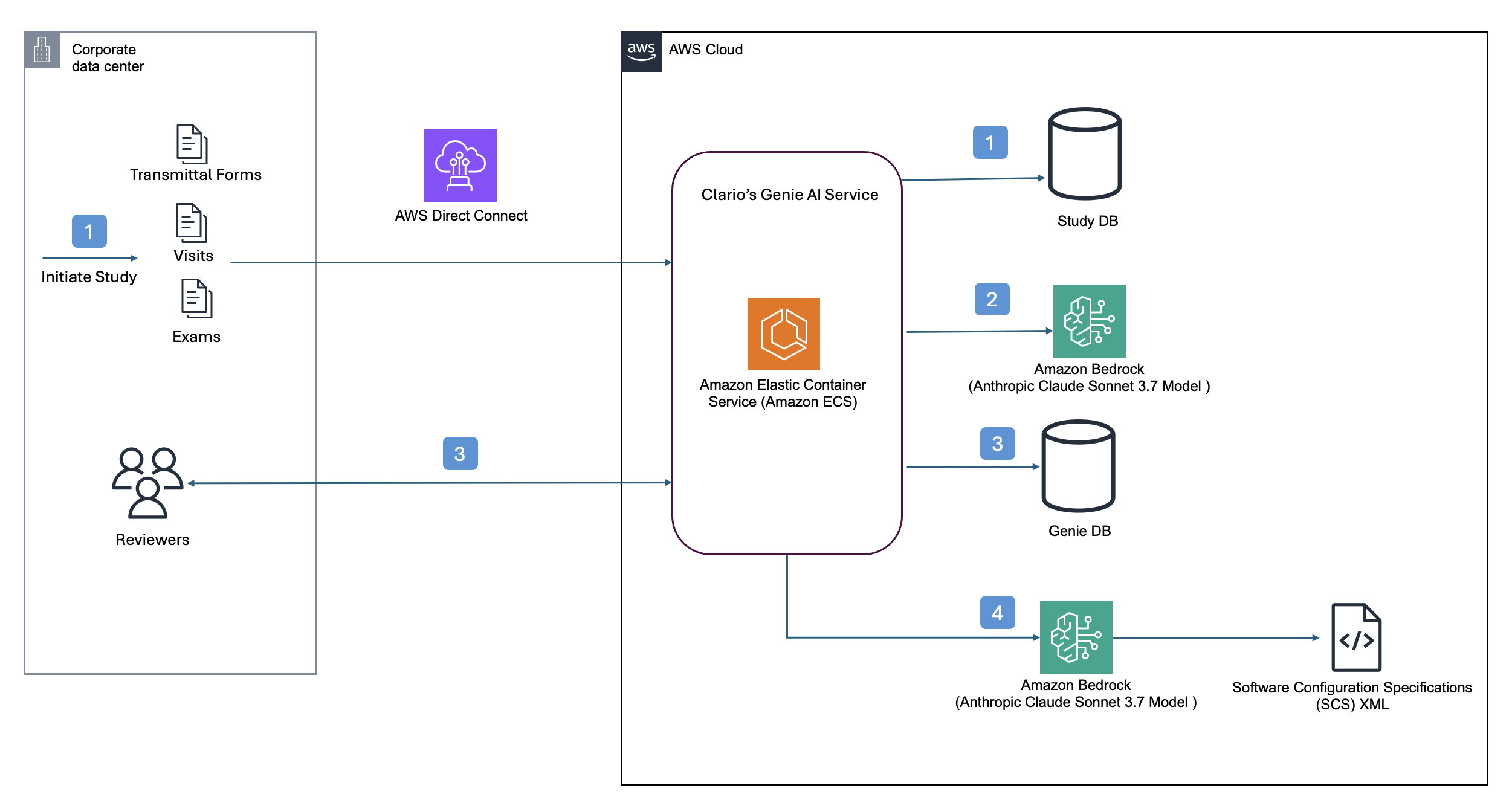
Clario streamlines clinical trial software configurations using Amazon BedrockArtificial Intelligence This post builds upon our previous post discussing how Clario developed an AI solution powered by Amazon Bedrock to accelerate clinical trials. Since then, Clario has further enhanced their AI capabilities, focusing on innovative solutions that streamline the generation of software configurations and artifacts for clinical trials while delivering high-quality clinical evidence.
This post builds upon our previous post discussing how Clario developed an AI solution powered by Amazon Bedrock to accelerate clinical trials. Since then, Clario has further enhanced their AI capabilities, focusing on innovative solutions that streamline the generation of software configurations and artifacts for clinical trials while delivering high-quality clinical evidence. Read More
How LeapXpert uses AI to bring order and oversight to business messagingAI News It’s no longer news that AI is transforming how people communicate at work. The bad (and less common) news, however, is that AI is also making those conversations harder to control. From chat apps to collaboration tools, employees exchange thousands of messages every day, many of which now pass through AI systems that summarise, analyse,
The post How LeapXpert uses AI to bring order and oversight to business messaging appeared first on AI News.
It’s no longer news that AI is transforming how people communicate at work. The bad (and less common) news, however, is that AI is also making those conversations harder to control. From chat apps to collaboration tools, employees exchange thousands of messages every day, many of which now pass through AI systems that summarise, analyse,
The post How LeapXpert uses AI to bring order and oversight to business messaging appeared first on AI News. Read More
How Lumana is redefining AI’s role in video surveillanceAI News For all the progress in artificial intelligence, most video security systems still fail at recognising context in real-world conditions. The majority of cameras can capture real-time footage, but struggle to interpret it. This is a problem turning into a growing concern for smart city designers, manufacturers and schools, each of which may depend on AI
The post How Lumana is redefining AI’s role in video surveillance appeared first on AI News.
For all the progress in artificial intelligence, most video security systems still fail at recognising context in real-world conditions. The majority of cameras can capture real-time footage, but struggle to interpret it. This is a problem turning into a growing concern for smart city designers, manufacturers and schools, each of which may depend on AI
The post How Lumana is redefining AI’s role in video surveillance appeared first on AI News. Read More
Learning World Models for Interactive Video Generationcs.AI updates on arXiv.org arXiv:2505.21996v2 Announce Type: replace-cross
Abstract: Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities.
arXiv:2505.21996v2 Announce Type: replace-cross
Abstract: Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities. Read More
Human-in-the-loop Online Rejection Sampling for Robotic Manipulationcs.AI updates on arXiv.org arXiv:2510.26406v1 Announce Type: cross
Abstract: Reinforcement learning (RL) is widely used to produce robust robotic manipulation policies, but fine-tuning vision-language-action (VLA) models with RL can be unstable due to inaccurate value estimates and sparse supervision at intermediate steps. In contrast, imitation learning (IL) is easy to train but often underperforms due to its offline nature. In this paper, we propose Hi-ORS, a simple yet effective post-training method that utilizes rejection sampling to achieve both training stability and high robustness. Hi-ORS stabilizes value estimation by filtering out negatively rewarded samples during online fine-tuning, and adopts a reward-weighted supervised training objective to provide dense intermediate-step supervision. For systematic study, we develop an asynchronous inference-training framework that supports flexible online human-in-the-loop corrections, which serve as explicit guidance for learning error-recovery behaviors. Across three real-world tasks and two embodiments, Hi-ORS fine-tunes a pi-base policy to master contact-rich manipulation in just 1.5 hours of real-world training, outperforming RL and IL baselines by a substantial margin in both effectiveness and efficiency. Notably, the fine-tuned policy exhibits strong test-time scalability by reliably executing complex error-recovery behaviors to achieve better performance.
arXiv:2510.26406v1 Announce Type: cross
Abstract: Reinforcement learning (RL) is widely used to produce robust robotic manipulation policies, but fine-tuning vision-language-action (VLA) models with RL can be unstable due to inaccurate value estimates and sparse supervision at intermediate steps. In contrast, imitation learning (IL) is easy to train but often underperforms due to its offline nature. In this paper, we propose Hi-ORS, a simple yet effective post-training method that utilizes rejection sampling to achieve both training stability and high robustness. Hi-ORS stabilizes value estimation by filtering out negatively rewarded samples during online fine-tuning, and adopts a reward-weighted supervised training objective to provide dense intermediate-step supervision. For systematic study, we develop an asynchronous inference-training framework that supports flexible online human-in-the-loop corrections, which serve as explicit guidance for learning error-recovery behaviors. Across three real-world tasks and two embodiments, Hi-ORS fine-tunes a pi-base policy to master contact-rich manipulation in just 1.5 hours of real-world training, outperforming RL and IL baselines by a substantial margin in both effectiveness and efficiency. Notably, the fine-tuned policy exhibits strong test-time scalability by reliably executing complex error-recovery behaviors to achieve better performance. Read More
Let Hypothesis Break Your Python Code Before Your Users DoTowards Data Science Property-based tests that find bugs you didn’t know existed.
The post Let Hypothesis Break Your Python Code Before Your Users Do appeared first on Towards Data Science.
Property-based tests that find bugs you didn’t know existed.
The post Let Hypothesis Break Your Python Code Before Your Users Do appeared first on Towards Data Science. Read More
Custom Intelligence: Building AI that matches your business DNAArtificial Intelligence In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences,
In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences, Read More
Through the Judge’s Eyes: Inferred Thinking Traces Improve Reliability of LLM Raterscs.AI updates on arXiv.org arXiv:2510.25860v1 Announce Type: new
Abstract: Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
arXiv:2510.25860v1 Announce Type: new
Abstract: Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters. Read More
