

Fine-Grained Iterative Adversarial Attacks with Limited Computation Budgetcs.AI updates on arXiv.org arXiv:2510.26981v1 Announce Type: cross
Abstract: This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget.
arXiv:2510.26981v1 Announce Type: cross
Abstract: This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget. Read More
Causal Masking on Spatial Data: An Information-Theoretic Case for Learning Spatial Datasets with Unimodal Language Modelscs.AI updates on arXiv.org arXiv:2510.27009v1 Announce Type: new
Abstract: Language models are traditionally designed around causal masking. In domains with spatial or relational structure, causal masking is often viewed as inappropriate, and sequential linearizations are instead used. Yet the question of whether it is viable to accept the information loss introduced by causal masking on nonsequential data has received little direct study, in part because few domains offer both spatial and sequential representations of the same dataset. In this work, we investigate this issue in the domain of chess, which naturally supports both representations. We train language models with bidirectional and causal self-attention mechanisms on both spatial (board-based) and sequential (move-based) data. Our results show that models trained on spatial board states – textit{even with causal masking} – consistently achieve stronger playing strength than models trained on sequential data. While our experiments are conducted on chess, our results are methodological and may have broader implications: applying causal masking to spatial data is a viable procedure for training unimodal LLMs on spatial data, and in some domains is even preferable to sequentialization.
arXiv:2510.27009v1 Announce Type: new
Abstract: Language models are traditionally designed around causal masking. In domains with spatial or relational structure, causal masking is often viewed as inappropriate, and sequential linearizations are instead used. Yet the question of whether it is viable to accept the information loss introduced by causal masking on nonsequential data has received little direct study, in part because few domains offer both spatial and sequential representations of the same dataset. In this work, we investigate this issue in the domain of chess, which naturally supports both representations. We train language models with bidirectional and causal self-attention mechanisms on both spatial (board-based) and sequential (move-based) data. Our results show that models trained on spatial board states – textit{even with causal masking} – consistently achieve stronger playing strength than models trained on sequential data. While our experiments are conducted on chess, our results are methodological and may have broader implications: applying causal masking to spatial data is a viable procedure for training unimodal LLMs on spatial data, and in some domains is even preferable to sequentialization. Read More
e1: Learning Adaptive Control of Reasoning Effortcs.AI updates on arXiv.org arXiv:2510.27042v1 Announce Type: new
Abstract: Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.
arXiv:2510.27042v1 Announce Type: new
Abstract: Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training. Read More
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Modelscs.AI updates on arXiv.org arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space.
arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space. Read More
Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvementcs.AI updates on arXiv.org arXiv:2510.27051v1 Announce Type: new
Abstract: Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA’s Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25%) and query rephrasal errors (3.2%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96% accuracy, a 10x reduction in model size, and 70% latency improvement. For query rephrasal, fine-tuning yielded a 3.7% gain in accuracy and a 40% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale.
arXiv:2510.27051v1 Announce Type: new
Abstract: Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA’s Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25%) and query rephrasal errors (3.2%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96% accuracy, a 10x reduction in model size, and 70% latency improvement. For query rephrasal, fine-tuning yielded a 3.7% gain in accuracy and a 40% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale. Read More
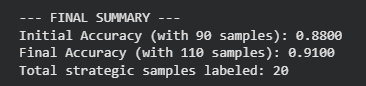
How to Build Supervised AI Models When You Don’t Have Annotated DataMarkTechPost One of the biggest challenges in real-world machine learning is that supervised models require labeled data—yet in many practical scenarios, the data you start with is almost always unlabeled. Manually annotating thousands of samples isn’t just slow; it’s expensive, tedious, and often impractical. This is where active learning becomes a game-changer. Active learning is a
The post How to Build Supervised AI Models When You Don’t Have Annotated Data appeared first on MarkTechPost.
One of the biggest challenges in real-world machine learning is that supervised models require labeled data—yet in many practical scenarios, the data you start with is almost always unlabeled. Manually annotating thousands of samples isn’t just slow; it’s expensive, tedious, and often impractical. This is where active learning becomes a game-changer. Active learning is a
The post How to Build Supervised AI Models When You Don’t Have Annotated Data appeared first on MarkTechPost. Read More
Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU ClustersMarkTechPost How can AI teams run Tinker style reinforcement learning on large language models using their own infrastructure with a single unified engine? Anyscale and NovaSky (UC Berkeley) Team releases SkyRL tx v0.1.0 that gives developers a way to run a Tinker compatible training and inference engine directly on their own hardware, while keeping the same
The post Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU Clusters appeared first on MarkTechPost.
How can AI teams run Tinker style reinforcement learning on large language models using their own infrastructure with a single unified engine? Anyscale and NovaSky (UC Berkeley) Team releases SkyRL tx v0.1.0 that gives developers a way to run a Tinker compatible training and inference engine directly on their own hardware, while keeping the same
The post Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU Clusters appeared first on MarkTechPost. Read More
AWS and OpenAI announce multi-year strategic partnershipOpenAI News OpenAI and AWS have entered a multi-year, $38 billion partnership to scale advanced AI workloads. AWS will provide world-class infrastructure and compute capacity to power OpenAI’s next generation of models.
OpenAI and AWS have entered a multi-year, $38 billion partnership to scale advanced AI workloads. AWS will provide world-class infrastructure and compute capacity to power OpenAI’s next generation of models. Read More

AI browsers are a significant security threatAI News Among the explosion of AI systems, AI web browsers such as Fellou and Comet from Perplexity have begun to make appearances on the corporate desktop. Such applications are described as the next evolution of the humble browser, and come with AI features built in; they can read and summarise web pages – and, at their
The post AI browsers are a significant security threat appeared first on AI News.
Among the explosion of AI systems, AI web browsers such as Fellou and Comet from Perplexity have begun to make appearances on the corporate desktop. Such applications are described as the next evolution of the humble browser, and come with AI features built in; they can read and summarise web pages – and, at their
The post AI browsers are a significant security threat appeared first on AI News. Read More

The Complete Guide to Using Google AI StudioKDnuggets Google AI Studio offers an intuitive, web-based platform for prototyping and deploying AI solutions with the latest Gemini models. It streamlines the development process, allowing users to experiment with prompts, analyze outputs, and export production-ready code effortlessly.
Google AI Studio offers an intuitive, web-based platform for prototyping and deploying AI solutions with the latest Gemini models. It streamlines the development process, allowing users to experiment with prompts, analyze outputs, and export production-ready code effortlessly. Read More
