

A Systematic Literature Review of Spatio-Temporal Graph Neural Network Models for Time Series Forecasting and Classificationcs.AI updates on arXiv.org arXiv:2410.22377v3 Announce Type: replace-cross
Abstract: In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture, at once, dependencies among variables and across time points. The objective of this systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and 366 papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive review of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in their studies. To the best of our knowledge, this is the first and broadest systematic literature review presenting a detailed comparison of results from current spatio-temporal GNN models applied to different domains. In its final part, this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability. This paper is complemented by a GitHub repository at https://github.com/FlaGer99/SLR-Spatio-Temporal-GNN.git providing additional interactive tools to further explore the presented findings.
arXiv:2410.22377v3 Announce Type: replace-cross
Abstract: In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture, at once, dependencies among variables and across time points. The objective of this systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and 366 papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive review of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in their studies. To the best of our knowledge, this is the first and broadest systematic literature review presenting a detailed comparison of results from current spatio-temporal GNN models applied to different domains. In its final part, this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability. This paper is complemented by a GitHub repository at https://github.com/FlaGer99/SLR-Spatio-Temporal-GNN.git providing additional interactive tools to further explore the presented findings. Read More

Data Observability in Analytics: Tools, Techniques, and Why It MattersKDnuggets Data analytics without observability is nothing. Learn about its importance, techniques, and tools for implementation.
Data analytics without observability is nothing. Learn about its importance, techniques, and tools for implementation. Read More
Artificial Empathy: AI based Mental Healthcs.AI updates on arXiv.org arXiv:2506.00081v2 Announce Type: replace-cross
Abstract: Many people suffer from mental health problems but not everyone seeks professional help or has access to mental health care. AI chatbots have increasingly become a go-to for individuals who either have mental disorders or simply want someone to talk to. This paper presents a study on participants who have previously used chatbots and a scenario-based testing of large language model (LLM) chatbots. Our findings indicate that AI chatbots were primarily utilized as a “Five minute therapist” or as a non-judgmental companion. Participants appreciated the anonymity and lack of judgment from chatbots. However, there were concerns about privacy and the security of sensitive information. The scenario-based testing of LLM chatbots highlighted additional issues. Some chatbots were consistently reassuring, used emojis and names to add a personal touch, and were quick to suggest seeking professional help. However, there were limitations such as inconsistent tone, occasional inappropriate responses (e.g., casual or romantic), and a lack of crisis sensitivity, particularly in recognizing red flag language and escalating responses appropriately. These findings can inform both the technology and mental health care industries on how to better utilize AI chatbots to support individuals during challenging emotional periods.
arXiv:2506.00081v2 Announce Type: replace-cross
Abstract: Many people suffer from mental health problems but not everyone seeks professional help or has access to mental health care. AI chatbots have increasingly become a go-to for individuals who either have mental disorders or simply want someone to talk to. This paper presents a study on participants who have previously used chatbots and a scenario-based testing of large language model (LLM) chatbots. Our findings indicate that AI chatbots were primarily utilized as a “Five minute therapist” or as a non-judgmental companion. Participants appreciated the anonymity and lack of judgment from chatbots. However, there were concerns about privacy and the security of sensitive information. The scenario-based testing of LLM chatbots highlighted additional issues. Some chatbots were consistently reassuring, used emojis and names to add a personal touch, and were quick to suggest seeking professional help. However, there were limitations such as inconsistent tone, occasional inappropriate responses (e.g., casual or romantic), and a lack of crisis sensitivity, particularly in recognizing red flag language and escalating responses appropriately. These findings can inform both the technology and mental health care industries on how to better utilize AI chatbots to support individuals during challenging emotional periods. Read More
DialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Modelscs.AI updates on arXiv.org arXiv:2510.27543v1 Announce Type: cross
Abstract: We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
arXiv:2510.27543v1 Announce Type: cross
Abstract: We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development. Read More

Flawed AI benchmarks put enterprise budgets at riskAI News A new academic review suggests AI benchmarks are flawed, potentially leading an enterprise to make high-stakes decisions on “misleading” data. Enterprise leaders are committing budgets of eight or nine figures to generative AI programmes. These procurement and development decisions often rely on public leaderboards and benchmarks to compare model capabilities. A large-scale study, ‘Measuring what
The post Flawed AI benchmarks put enterprise budgets at risk appeared first on AI News.
A new academic review suggests AI benchmarks are flawed, potentially leading an enterprise to make high-stakes decisions on “misleading” data. Enterprise leaders are committing budgets of eight or nine figures to generative AI programmes. These procurement and development decisions often rely on public leaderboards and benchmarks to compare model capabilities. A large-scale study, ‘Measuring what
The post Flawed AI benchmarks put enterprise budgets at risk appeared first on AI News. Read More
TempoPFN: Synthetic Pre-training of Linear RNNs for Zero-shot Time Series Forecastingcs.AI updates on arXiv.org arXiv:2510.25502v2 Announce Type: replace-cross
Abstract: Foundation models for zero-shot time series forecasting face challenges in efficient long-horizon prediction and reproducibility, with existing synthetic-only approaches underperforming on challenging benchmarks. This paper presents TempoPFN, a univariate time series foundation model based on linear Recurrent Neural Networks (RNNs) pre-trained exclusively on synthetic data. The model uses a GatedDeltaProduct architecture with state-weaving for fully parallelizable training across sequence lengths, eliminating the need for windowing or summarization techniques while maintaining robust temporal state-tracking. Our comprehensive synthetic data pipeline unifies diverse generators, including stochastic differential equations, Gaussian processes, and audio synthesis, with novel augmentations. In zero-shot evaluations on the Gift-Eval benchmark, TempoPFN achieves top-tier competitive performance, outperforming all existing synthetic-only approaches and surpassing the vast majority of models trained on real-world data, while being more efficient than existing baselines by leveraging fully parallelizable training and inference. We open-source our complete data generation pipeline and training code, providing a reproducible foundation for future research.
arXiv:2510.25502v2 Announce Type: replace-cross
Abstract: Foundation models for zero-shot time series forecasting face challenges in efficient long-horizon prediction and reproducibility, with existing synthetic-only approaches underperforming on challenging benchmarks. This paper presents TempoPFN, a univariate time series foundation model based on linear Recurrent Neural Networks (RNNs) pre-trained exclusively on synthetic data. The model uses a GatedDeltaProduct architecture with state-weaving for fully parallelizable training across sequence lengths, eliminating the need for windowing or summarization techniques while maintaining robust temporal state-tracking. Our comprehensive synthetic data pipeline unifies diverse generators, including stochastic differential equations, Gaussian processes, and audio synthesis, with novel augmentations. In zero-shot evaluations on the Gift-Eval benchmark, TempoPFN achieves top-tier competitive performance, outperforming all existing synthetic-only approaches and surpassing the vast majority of models trained on real-world data, while being more efficient than existing baselines by leveraging fully parallelizable training and inference. We open-source our complete data generation pipeline and training code, providing a reproducible foundation for future research. Read More
On the Mistaken Assumption of Interchangeable Deep Reinforcement Learning Implementationscs.AI updates on arXiv.org arXiv:2503.22575v2 Announce Type: replace-cross
Abstract: Deep Reinforcement Learning (DRL) is a paradigm of artificial intelligence where an agent uses a neural network to learn which actions to take in a given environment. DRL has recently gained traction from being able to solve complex environments like driving simulators, 3D robotic control, and multiplayer-online-battle-arena video games. Numerous implementations of the state-of-the-art algorithms responsible for training these agents, like the Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) algorithms, currently exist. However, studies make the mistake of assuming implementations of the same algorithm to be consistent and thus, interchangeable. In this paper, through a differential testing lens, we present the results of studying the extent of implementation inconsistencies, their effect on the implementations’ performance, as well as their impact on the conclusions of prior studies under the assumption of interchangeable implementations. The outcomes of our differential tests showed significant discrepancies between the tested algorithm implementations, indicating that they are not interchangeable. In particular, out of the five PPO implementations tested on 56 games, three implementations achieved superhuman performance for 50% of their total trials while the other two implementations only achieved superhuman performance for less than 15% of their total trials. As part of a meticulous manual analysis of the implementations’ source code, we analyzed implementation discrepancies and determined that code-level inconsistencies primarily caused these discrepancies. Lastly, we replicated a study and showed that this assumption of implementation interchangeability was sufficient to flip experiment outcomes. Therefore, this calls for a shift in how implementations are being used.
arXiv:2503.22575v2 Announce Type: replace-cross
Abstract: Deep Reinforcement Learning (DRL) is a paradigm of artificial intelligence where an agent uses a neural network to learn which actions to take in a given environment. DRL has recently gained traction from being able to solve complex environments like driving simulators, 3D robotic control, and multiplayer-online-battle-arena video games. Numerous implementations of the state-of-the-art algorithms responsible for training these agents, like the Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) algorithms, currently exist. However, studies make the mistake of assuming implementations of the same algorithm to be consistent and thus, interchangeable. In this paper, through a differential testing lens, we present the results of studying the extent of implementation inconsistencies, their effect on the implementations’ performance, as well as their impact on the conclusions of prior studies under the assumption of interchangeable implementations. The outcomes of our differential tests showed significant discrepancies between the tested algorithm implementations, indicating that they are not interchangeable. In particular, out of the five PPO implementations tested on 56 games, three implementations achieved superhuman performance for 50% of their total trials while the other two implementations only achieved superhuman performance for less than 15% of their total trials. As part of a meticulous manual analysis of the implementations’ source code, we analyzed implementation discrepancies and determined that code-level inconsistencies primarily caused these discrepancies. Lastly, we replicated a study and showed that this assumption of implementation interchangeability was sufficient to flip experiment outcomes. Therefore, this calls for a shift in how implementations are being used. Read More

ClinCheck Live brings AI planning to Invisalign dental treatmentsAI News Align Technology, a medical device company that designs, manufactures, and sells the Invisalign system of clear aligners, exocad CAD/CAM software, and iTero intra-oral scanners, has unveiled ClinCheck Live Plan, a new feature in its Invisalign digital dental treatment planning. ClinCheck Live Plan is designed to automate the creation of an initial Invisalign treatment plan that’s
The post ClinCheck Live brings AI planning to Invisalign dental treatments appeared first on AI News.
Align Technology, a medical device company that designs, manufactures, and sells the Invisalign system of clear aligners, exocad CAD/CAM software, and iTero intra-oral scanners, has unveiled ClinCheck Live Plan, a new feature in its Invisalign digital dental treatment planning. ClinCheck Live Plan is designed to automate the creation of an initial Invisalign treatment plan that’s
The post ClinCheck Live brings AI planning to Invisalign dental treatments appeared first on AI News. Read More

Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025MarkTechPost Code-oriented large language models moved from autocomplete to software engineering systems. In 2025, leading models must fix real GitHub issues, refactor multi-repo backends, write tests, and run as agents over long context windows. The main question for teams is not “can it code” but which model fits which constraints. Here are seven models (and systems
The post Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025 appeared first on MarkTechPost.
Code-oriented large language models moved from autocomplete to software engineering systems. In 2025, leading models must fix real GitHub issues, refactor multi-repo backends, write tests, and run as agents over long context windows. The main question for teams is not “can it code” but which model fits which constraints. Here are seven models (and systems
The post Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025 appeared first on MarkTechPost. Read More
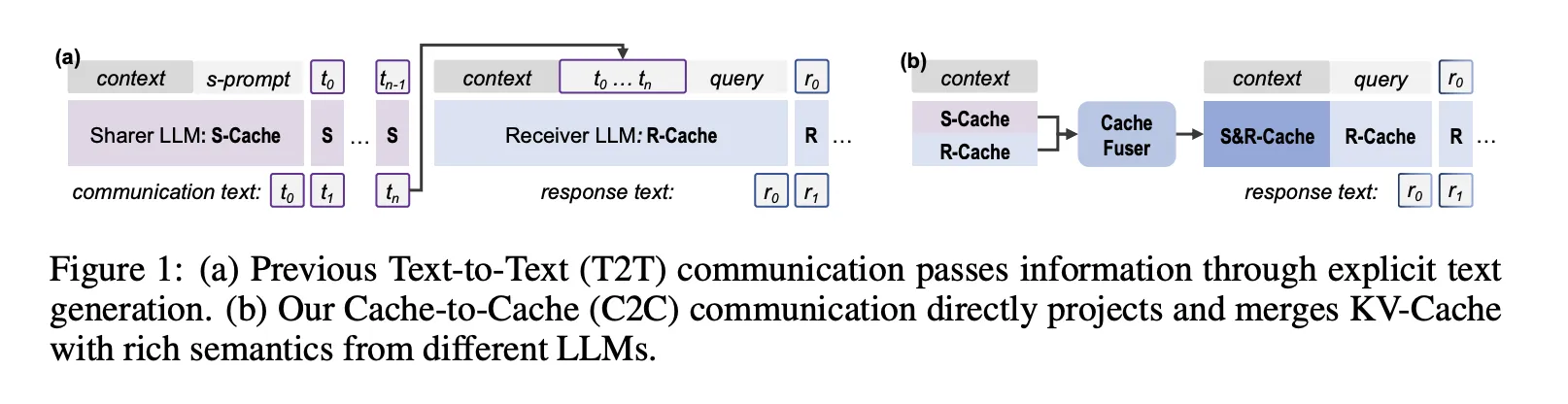
Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache FusionMarkTechPost Can large language models collaborate without sending a single token of text? a team of researchers from Tsinghua University, Infinigence AI, The Chinese University of Hong Kong, Shanghai AI Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-Cache (C2C) is a new communication paradigm where large language models exchange information through their KV-Cache rather than
The post Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion appeared first on MarkTechPost.
Can large language models collaborate without sending a single token of text? a team of researchers from Tsinghua University, Infinigence AI, The Chinese University of Hong Kong, Shanghai AI Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-Cache (C2C) is a new communication paradigm where large language models exchange information through their KV-Cache rather than
The post Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion appeared first on MarkTechPost. Read More
