
Top 5 AI Code Review Tools for DevelopersKDnuggets Code reviews shouldn’t be a bottleneck. The best AI code review tools now catch bugs, anti-patterns, security flaws, and more in seconds before they ever hit production.
Code reviews shouldn’t be a bottleneck. The best AI code review tools now catch bugs, anti-patterns, security flaws, and more in seconds before they ever hit production. Read More

Infosys AI implementation framework offers business leaders guidanceAI News As a large provider of technology services operating in multiple industries, Infosys is one of the names that quickly come to mind when decision-makers consider possible providers of consultation on and practical implementation of any AI project – discrete or organisation-wide. Infosys delivers these services through its Topaz Fabric, leveraging its partnerships with specific AI
The post Infosys AI implementation framework offers business leaders guidance appeared first on AI News.
As a large provider of technology services operating in multiple industries, Infosys is one of the names that quickly come to mind when decision-makers consider possible providers of consultation on and practical implementation of any AI project – discrete or organisation-wide. Infosys delivers these services through its Topaz Fabric, leveraging its partnerships with specific AI
The post Infosys AI implementation framework offers business leaders guidance appeared first on AI News. Read More

Why Every Analytics Engineer Needs to Understand Data ArchitectureTowards Data Science Get the data architecture right, and everything else becomes easier.
I know it sounds simple, but in reality, little nuances in designing your data architecture may have costly implications. This article provides a crash course on the architectures that shape your daily decisions – from relational databases to event-driven systems.
The post Why Every Analytics Engineer Needs to Understand Data Architecture appeared first on Towards Data Science.
Get the data architecture right, and everything else becomes easier.
I know it sounds simple, but in reality, little nuances in designing your data architecture may have costly implications. This article provides a crash course on the architectures that shape your daily decisions – from relational databases to event-driven systems.
The post Why Every Analytics Engineer Needs to Understand Data Architecture appeared first on Towards Data Science. Read More
Agentic AI for Modern Deep Learning ExperimentationTowards Data Science Stop babysitting training runs. Start shipping research. Autonomous experiment management built for/by deep learning engineers.
The post Agentic AI for Modern Deep Learning Experimentation appeared first on Towards Data Science.
Stop babysitting training runs. Start shipping research. Autonomous experiment management built for/by deep learning engineers.
The post Agentic AI for Modern Deep Learning Experimentation appeared first on Towards Data Science. Read More
A new way to express yourself: Gemini can now create musicGoogle DeepMind News The Gemini app now features our most advanced music generation model Lyria 3, empowering anyone to make 30-second tracks using text or images.
The Gemini app now features our most advanced music generation model Lyria 3, empowering anyone to make 30-second tracks using text or images. Read More

How financial institutions are embedding AI decision-makingAI News For leaders in the financial sector, the experimental phase of generative AI has concluded and the focus for 2026 is operational integration. While early adoption centred on content generation and efficiency in isolated workflows, the current requirement is to industrialise these capabilities. The objective is to create systems where AI agents do not merely assist
The post How financial institutions are embedding AI decision-making appeared first on AI News.
For leaders in the financial sector, the experimental phase of generative AI has concluded and the focus for 2026 is operational integration. While early adoption centred on content generation and efficiency in isolated workflows, the current requirement is to industrialise these capabilities. The objective is to create systems where AI agents do not merely assist
The post How financial institutions are embedding AI decision-making appeared first on AI News. Read More
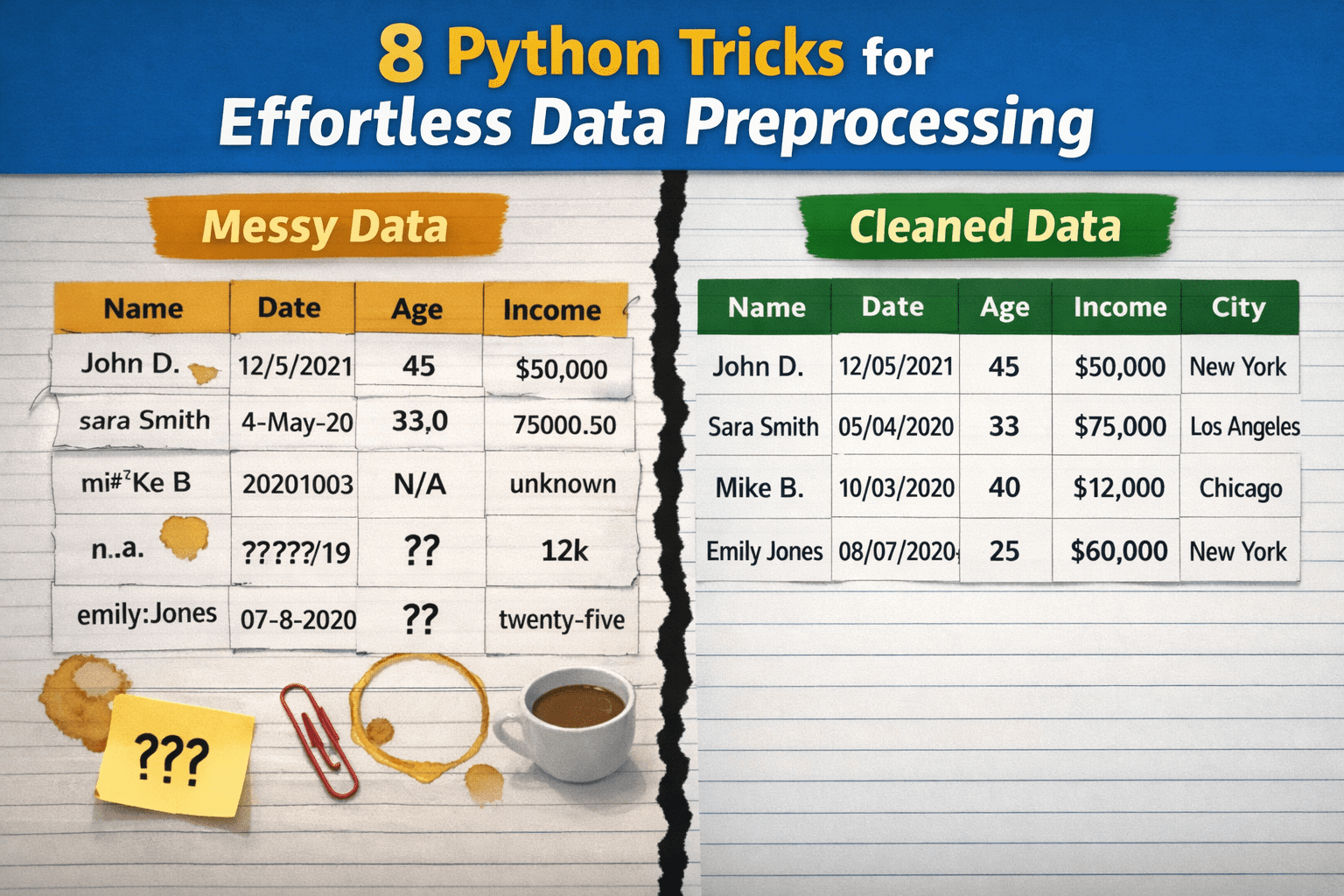
From Messy to Clean: 8 Python Tricks for Effortless Data PreprocessingKDnuggets 8 Python tricks to turn raw, messy data into clean, neatly preprocessed data with minimal effort.
8 Python tricks to turn raw, messy data into clean, neatly preprocessed data with minimal effort. Read More
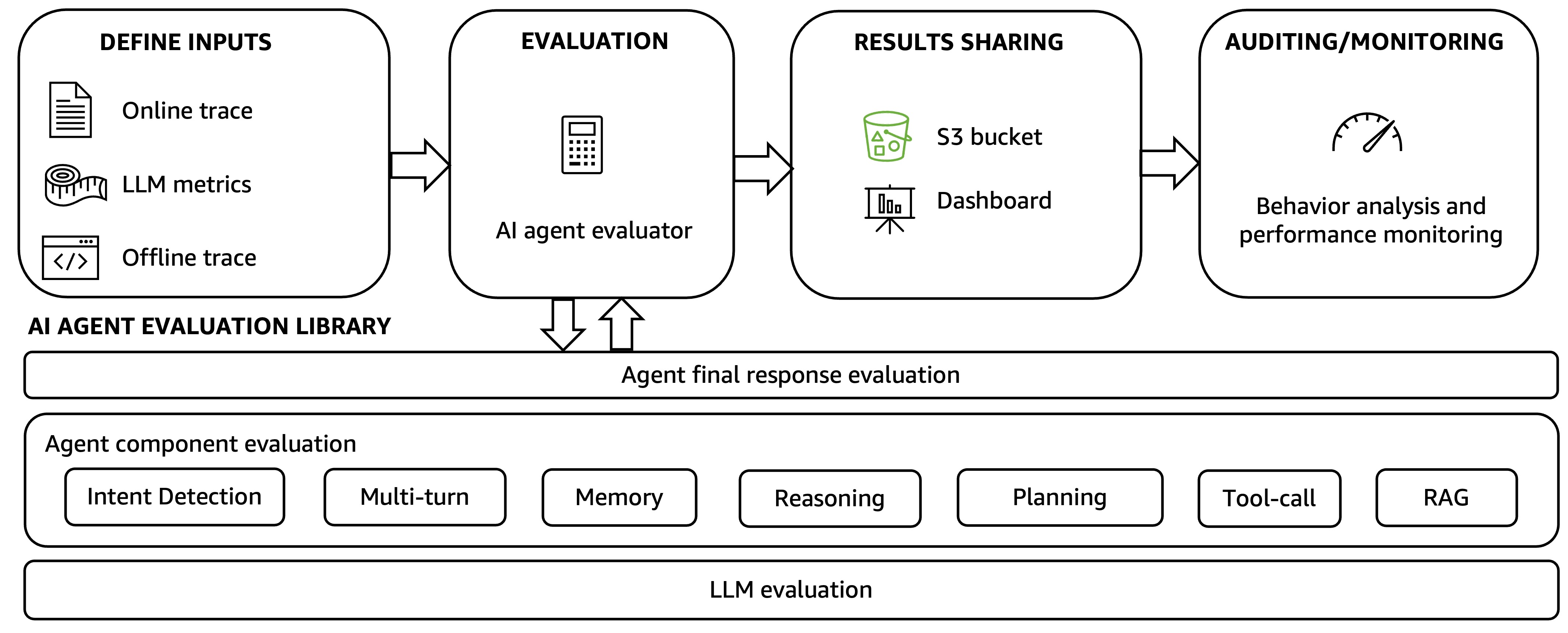
Evaluating AI agents: Real-world lessons from building agentic systems at AmazonArtificial Intelligence In this post, we present a comprehensive evaluation framework for Amazon agentic AI systems that addresses the complexity of agentic AI applications at Amazon through two core components: a generic evaluation workflow that standardizes assessment procedures across diverse agent implementations, and an agent evaluation library that provides systematic measurements and metrics in Amazon Bedrock AgentCore Evaluations, along with Amazon use case-specific evaluation approaches and metrics.
In this post, we present a comprehensive evaluation framework for Amazon agentic AI systems that addresses the complexity of agentic AI applications at Amazon through two core components: a generic evaluation workflow that standardizes assessment procedures across diverse agent implementations, and an agent evaluation library that provides systematic measurements and metrics in Amazon Bedrock AgentCore Evaluations, along with Amazon use case-specific evaluation approaches and metrics. Read More
[Tutorial] Building a Visual Document Retrieval Pipeline with ColPali and Late Interaction ScoringMarkTechPost In this tutorial, we build an end-to-end visual document retrieval pipeline using ColPali. We focus on making the setup robust by resolving common dependency conflicts and ensuring the environment stays stable. We render PDF pages as images, embed them using ColPali’s multi-vector representations, and rely on late-interaction scoring to retrieve the most relevant pages for
The post [Tutorial] Building a Visual Document Retrieval Pipeline with ColPali and Late Interaction Scoring appeared first on MarkTechPost.
In this tutorial, we build an end-to-end visual document retrieval pipeline using ColPali. We focus on making the setup robust by resolving common dependency conflicts and ensuring the environment stays stable. We render PDF pages as images, embed them using ColPali’s multi-vector representations, and rely on late-interaction scoring to retrieve the most relevant pages for
The post [Tutorial] Building a Visual Document Retrieval Pipeline with ColPali and Late Interaction Scoring appeared first on MarkTechPost. Read More
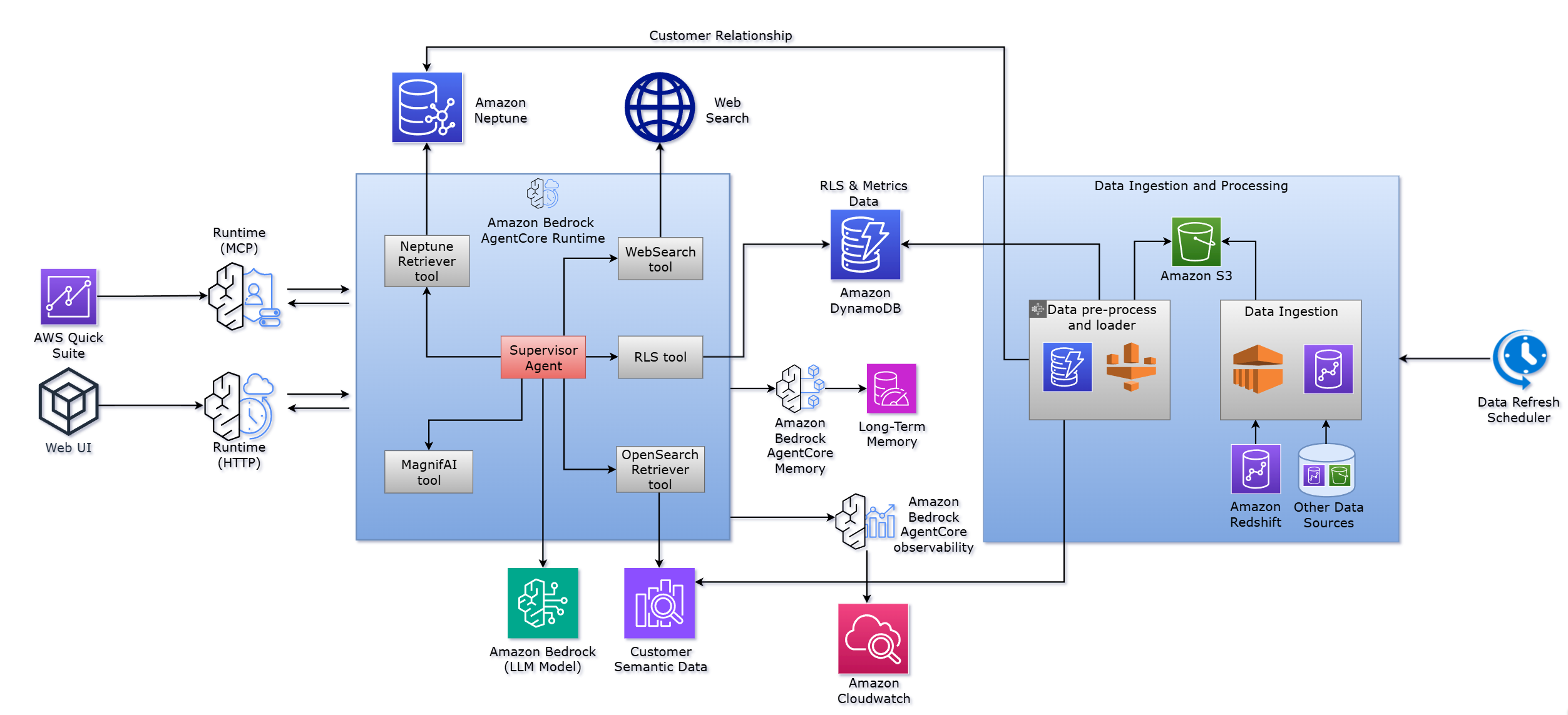
Build unified intelligence with Amazon Bedrock AgentCoreArtificial Intelligence In this post, we demonstrate how to build unified intelligence systems using Amazon Bedrock AgentCore through our real-world implementation of the Customer Agent and Knowledge Engine (CAKE).
In this post, we demonstrate how to build unified intelligence systems using Amazon Bedrock AgentCore through our real-world implementation of the Customer Agent and Knowledge Engine (CAKE). Read More