Unlock global AI inference scalability using new global cross-Region inference on Amazon Bedrock with Anthropic’s Claude Sonnet 4.5Artificial Intelligence Organizations are increasingly integrating generative AI capabilities into their applications to enhance customer experiences, streamline operations, and drive innovation. As generative AI workloads continue to grow in scale and importance, organizations face new challenges in maintaining consistent performance, reliability, and availability of their AI-powered applications. Customers are looking to scale their AI inference workloads across
Organizations are increasingly integrating generative AI capabilities into their applications to enhance customer experiences, streamline operations, and drive innovation. As generative AI workloads continue to grow in scale and importance, organizations face new challenges in maintaining consistent performance, reliability, and availability of their AI-powered applications. Customers are looking to scale their AI inference workloads across Read More
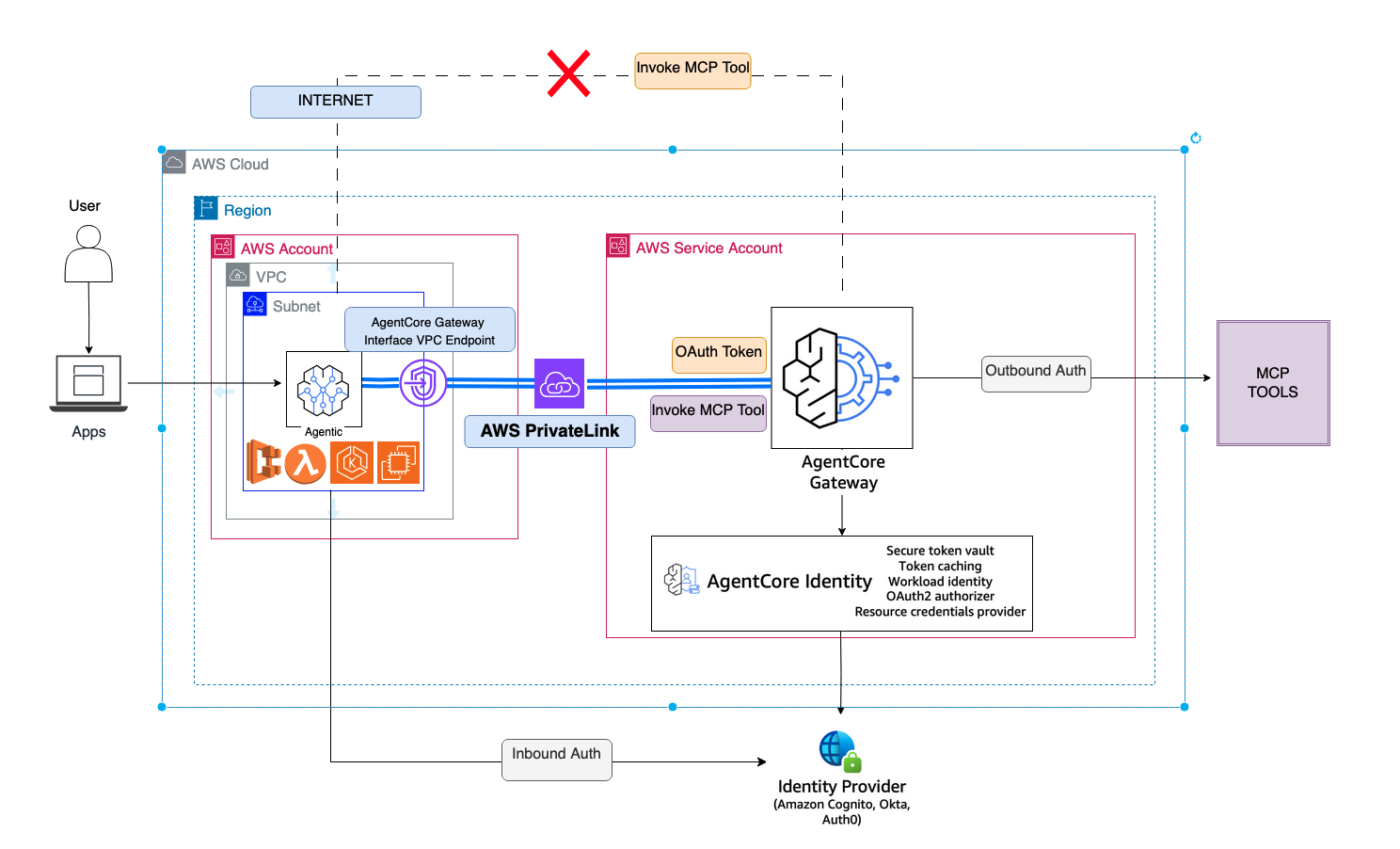
Secure ingress connectivity to Amazon Bedrock AgentCore Gateway using interface VPC endpointsArtificial Intelligence In this post, we demonstrate how to access AgentCore Gateway through a VPC interface endpoint from an Amazon Elastic Compute Cloud (Amazon EC2) instance in a VPC. We also show how to configure your VPC endpoint policy to provide secure access to the AgentCore Gateway while maintaining the principle of least privilege access.
In this post, we demonstrate how to access AgentCore Gateway through a VPC interface endpoint from an Amazon Elastic Compute Cloud (Amazon EC2) instance in a VPC. We also show how to configure your VPC endpoint policy to provide secure access to the AgentCore Gateway while maintaining the principle of least privilege access. Read More

What happens when generative AI models train recursively on each others’ outputs?cs.AI updates on arXiv.org arXiv:2505.21677v3 Announce Type: replace-cross
Abstract: The internet serves as a common source of training data for generative AI (genAI) models but is increasingly populated with AI-generated content. This duality raises the possibility that future genAI models may be trained on other models’ generated outputs. Prior work has studied consequences of models training on their own generated outputs, but limited work has considered what happens if models ingest content produced by other models. Given society’s increasing dependence on genAI tools, understanding such data-mediated model interactions is critical. This work provides empirical evidence for how data-mediated interactions might unfold in practice, develops a theoretical model for this interactive training process, and experimentally validates the theory. We find that data-mediated interactions can benefit models by exposing them to novel concepts perhaps missed in original training data, but also can homogenize their performance on shared tasks.
arXiv:2505.21677v3 Announce Type: replace-cross
Abstract: The internet serves as a common source of training data for generative AI (genAI) models but is increasingly populated with AI-generated content. This duality raises the possibility that future genAI models may be trained on other models’ generated outputs. Prior work has studied consequences of models training on their own generated outputs, but limited work has considered what happens if models ingest content produced by other models. Given society’s increasing dependence on genAI tools, understanding such data-mediated model interactions is critical. This work provides empirical evidence for how data-mediated interactions might unfold in practice, develops a theoretical model for this interactive training process, and experimentally validates the theory. We find that data-mediated interactions can benefit models by exposing them to novel concepts perhaps missed in original training data, but also can homogenize their performance on shared tasks. Read More
Interactive Learning for LLM Reasoningcs.AI updates on arXiv.org arXiv:2509.26306v3 Announce Type: replace
Abstract: Existing multi-agent learning approaches have developed interactive training environments to explicitly promote collaboration among multiple Large Language Models (LLMs), thereby constructing stronger multi-agent systems (MAS). However, during inference, they require re-executing the MAS to obtain final solutions, which diverges from human cognition that individuals can enhance their reasoning capabilities through interactions with others and resolve questions independently in the future. To investigate whether multi-agent interaction can enhance LLMs’ independent problem-solving ability, we introduce ILR, a novel co-learning framework for MAS that integrates two key components: Dynamic Interaction and Perception Calibration. Specifically, Dynamic Interaction first adaptively selects either cooperative or competitive strategies depending on question difficulty and model ability. LLMs then exchange information through Idea3 (Idea Sharing, Idea Analysis, and Idea Fusion), an innovative interaction paradigm designed to mimic human discussion, before deriving their respective final answers. In Perception Calibration, ILR employs Group Relative Policy Optimization (GRPO) to train LLMs while integrating one LLM’s reward distribution characteristics into another’s reward function, thereby enhancing the cohesion of multi-agent interactions. We validate ILR on three LLMs across two model families of varying scales, evaluating performance on five mathematical benchmarks and one coding benchmark. Experimental results show that ILR consistently outperforms single-agent learning, yielding an improvement of up to 5% over the strongest baseline. We further discover that Idea3 can enhance the robustness of stronger LLMs during multi-agent inference, and dynamic interaction types can boost multi-agent learning compared to pure cooperative or competitive strategies.
arXiv:2509.26306v3 Announce Type: replace
Abstract: Existing multi-agent learning approaches have developed interactive training environments to explicitly promote collaboration among multiple Large Language Models (LLMs), thereby constructing stronger multi-agent systems (MAS). However, during inference, they require re-executing the MAS to obtain final solutions, which diverges from human cognition that individuals can enhance their reasoning capabilities through interactions with others and resolve questions independently in the future. To investigate whether multi-agent interaction can enhance LLMs’ independent problem-solving ability, we introduce ILR, a novel co-learning framework for MAS that integrates two key components: Dynamic Interaction and Perception Calibration. Specifically, Dynamic Interaction first adaptively selects either cooperative or competitive strategies depending on question difficulty and model ability. LLMs then exchange information through Idea3 (Idea Sharing, Idea Analysis, and Idea Fusion), an innovative interaction paradigm designed to mimic human discussion, before deriving their respective final answers. In Perception Calibration, ILR employs Group Relative Policy Optimization (GRPO) to train LLMs while integrating one LLM’s reward distribution characteristics into another’s reward function, thereby enhancing the cohesion of multi-agent interactions. We validate ILR on three LLMs across two model families of varying scales, evaluating performance on five mathematical benchmarks and one coding benchmark. Experimental results show that ILR consistently outperforms single-agent learning, yielding an improvement of up to 5% over the strongest baseline. We further discover that Idea3 can enhance the robustness of stronger LLMs during multi-agent inference, and dynamic interaction types can boost multi-agent learning compared to pure cooperative or competitive strategies. Read More
Thinking Machines Launches Tinker: A Low-Level Training API that Abstracts Distributed LLM Fine-Tuning without Hiding the KnobsMarkTechPost Thinking Machines has released Tinker, a Python API that lets researchers and engineers write training loops locally while the platform executes them on managed distributed GPU clusters. The pitch is narrow and technical: keep full control of data, objectives, and optimization steps; hand off scheduling, fault tolerance, and multi-node orchestration. The service is in private
The post Thinking Machines Launches Tinker: A Low-Level Training API that Abstracts Distributed LLM Fine-Tuning without Hiding the Knobs appeared first on MarkTechPost.
Thinking Machines has released Tinker, a Python API that lets researchers and engineers write training loops locally while the platform executes them on managed distributed GPU clusters. The pitch is narrow and technical: keep full control of data, objectives, and optimization steps; hand off scheduling, fault tolerance, and multi-node orchestration. The service is in private
The post Thinking Machines Launches Tinker: A Low-Level Training API that Abstracts Distributed LLM Fine-Tuning without Hiding the Knobs appeared first on MarkTechPost. Read More

5 Fun AI Agent Projects for Absolute BeginnersKDnuggets Build these AI agents that actually do useful work (and teach you a bunch).
Build these AI agents that actually do useful work (and teach you a bunch). Read More

A Gentle Introduction to MCP Servers and ClientsKDnuggets Get a gentle introduction to the standard that defines how artificial intelligence systems connect with the outside world.
Get a gentle introduction to the standard that defines how artificial intelligence systems connect with the outside world. Read More
ViLBias: Detecting and Reasoning about Bias in Multimodal Contentcs.AI updates on arXiv.org arXiv:2412.17052v4 Announce Type: replace
Abstract: Detecting bias in multimodal news requires models that reason over text–image pairs, not just classify text. In response, we present ViLBias, a VQA-style benchmark and framework for detecting and reasoning about bias in multimodal news. The dataset comprises 40,945 text–image pairs from diverse outlets, each annotated with a bias label and concise rationale using a two-stage LLM-as-annotator pipeline with hierarchical majority voting and human-in-the-loop validation. We evaluate Small Language Models (SLMs), Large Language Models (LLMs), and Vision–Language Models (VLMs) across closed-ended classification and open-ended reasoning (oVQA), and compare parameter-efficient tuning strategies. Results show that incorporating images alongside text improves detection accuracy by 3–5%, and that LLMs/VLMs better capture subtle framing and text–image inconsistencies than SLMs. Parameter-efficient methods (LoRA/QLoRA/Adapters) recover 97–99% of full fine-tuning performance with $<5%$ trainable parameters. For oVQA, reasoning accuracy spans 52–79% and faithfulness 68–89%, both improved by instruction tuning; closed accuracy correlates strongly with reasoning ($r = 0.91$). ViLBias offers a scalable benchmark and strong baselines for multimodal bias detection and rationale quality.
arXiv:2412.17052v4 Announce Type: replace
Abstract: Detecting bias in multimodal news requires models that reason over text–image pairs, not just classify text. In response, we present ViLBias, a VQA-style benchmark and framework for detecting and reasoning about bias in multimodal news. The dataset comprises 40,945 text–image pairs from diverse outlets, each annotated with a bias label and concise rationale using a two-stage LLM-as-annotator pipeline with hierarchical majority voting and human-in-the-loop validation. We evaluate Small Language Models (SLMs), Large Language Models (LLMs), and Vision–Language Models (VLMs) across closed-ended classification and open-ended reasoning (oVQA), and compare parameter-efficient tuning strategies. Results show that incorporating images alongside text improves detection accuracy by 3–5%, and that LLMs/VLMs better capture subtle framing and text–image inconsistencies than SLMs. Parameter-efficient methods (LoRA/QLoRA/Adapters) recover 97–99% of full fine-tuning performance with $<5%$ trainable parameters. For oVQA, reasoning accuracy spans 52–79% and faithfulness 68–89%, both improved by instruction tuning; closed accuracy correlates strongly with reasoning ($r = 0.91$). ViLBias offers a scalable benchmark and strong baselines for multimodal bias detection and rationale quality. Read More
What Makes a Language Look Like Itself?Towards Data Science How simple statistics reveal the visual fingerprints of 20 languages
The post What Makes a Language Look Like Itself? appeared first on Towards Data Science.
How simple statistics reveal the visual fingerprints of 20 languages
The post What Makes a Language Look Like Itself? appeared first on Towards Data Science. Read More
Uncovering Vulnerabilities of LLM-Assisted Cyber Threat Intelligencecs.AI updates on arXiv.org arXiv:2509.23573v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research.
arXiv:2509.23573v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research. Read More