The Beginner’s Guide to Tracking Token Usage in LLM AppsKDnuggets If you’re not tracking tokens, you’re basically burning cash every time your app talks to an LLM.
If you’re not tracking tokens, you’re basically burning cash every time your app talks to an LLM. Read More

How Huawei is building agentic AI systems that make decisions independentlyAI News In a cement plant operated by Conch Group, an agentic AI system built on Huawei infrastructure now predicts the strength of clinker with over 90% accuracy and autonomously adjusts calcination parameters to cut coal consumption by 1%—decisions that previously required human expertise accumulated over decades This exemplifies how Huawei is developing agentic AI systems that
The post How Huawei is building agentic AI systems that make decisions independently appeared first on AI News.
In a cement plant operated by Conch Group, an agentic AI system built on Huawei infrastructure now predicts the strength of clinker with over 90% accuracy and autonomously adjusts calcination parameters to cut coal consumption by 1%—decisions that previously required human expertise accumulated over decades This exemplifies how Huawei is developing agentic AI systems that
The post How Huawei is building agentic AI systems that make decisions independently appeared first on AI News. Read More

5 Signs Your Business Is Ready For AI (Sponsored)KDnuggets How do you know if you’re ready to take the AI plunge? Here are five dead giveaways that AI could transform how you work.
How do you know if you’re ready to take the AI plunge? Here are five dead giveaways that AI could transform how you work. Read More

90% of science is lost. This new AI just found itArtificial Intelligence News — ScienceDaily Vast amounts of valuable research data remain unused, trapped in labs or lost to time. Frontiers aims to change that with FAIR² Data Management, a groundbreaking AI-driven system that makes datasets reusable, verifiable, and citable. By uniting curation, compliance, peer review, and interactive visualization in one platform, FAIR² empowers scientists to share their work responsibly and gain recognition.
Vast amounts of valuable research data remain unused, trapped in labs or lost to time. Frontiers aims to change that with FAIR² Data Management, a groundbreaking AI-driven system that makes datasets reusable, verifiable, and citable. By uniting curation, compliance, peer review, and interactive visualization in one platform, FAIR² empowers scientists to share their work responsibly and gain recognition. Read More

Here’s When You Would Choose Spreadsheets Over SQLKDnuggets Spreadsheets might seem obsolete in the world of relational databases. They’re not! Here are situations when spreadsheets easily topple SQL.
Spreadsheets might seem obsolete in the world of relational databases. They’re not! Here are situations when spreadsheets easily topple SQL. Read More
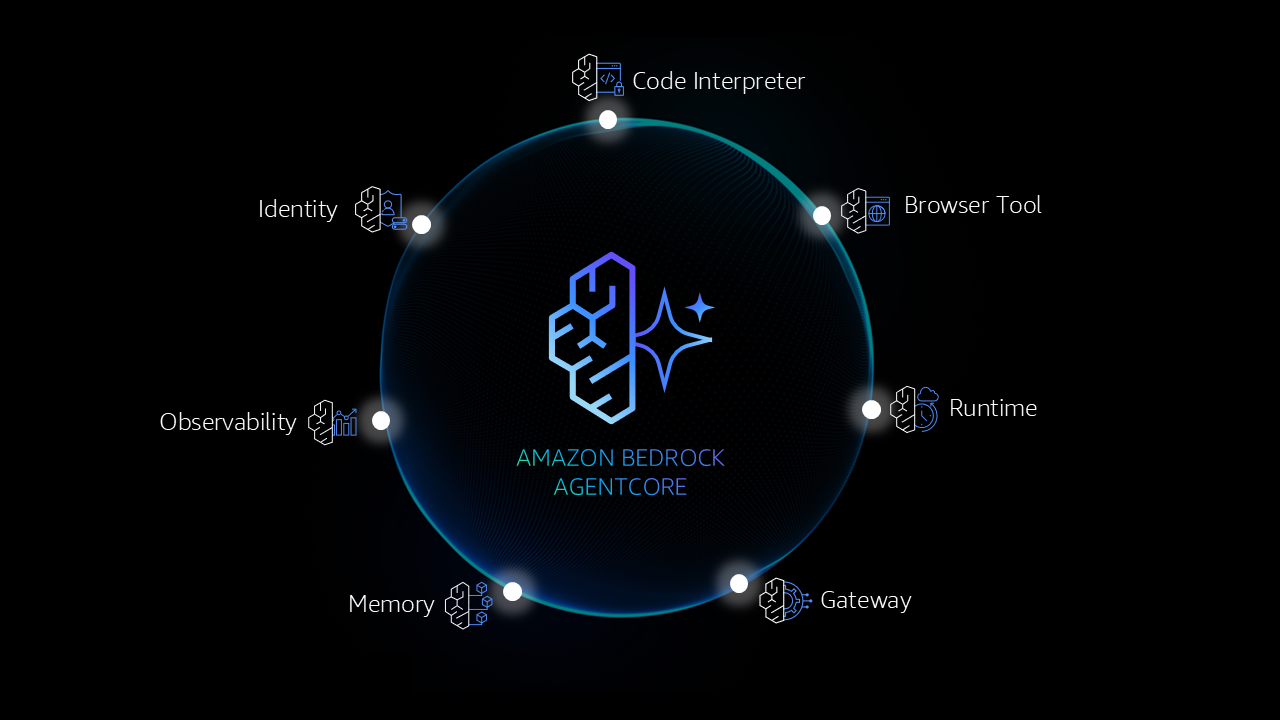
Make agents a reality with Amazon Bedrock AgentCore: Now generally availableArtificial Intelligence Learn why customers choose AgentCore to build secure, reliable AI solutions using their choice of frameworks and models for production workloads.
Learn why customers choose AgentCore to build secure, reliable AI solutions using their choice of frameworks and models for production workloads. Read More
OpenAI and Broadcom announce strategic collaboration to deploy 10 gigawatts of OpenAI-designed AI acceleratorsOpenAI News OpenAI and Broadcom announce a multi-year partnership to deploy 10 gigawatts of OpenAI-designed AI accelerators, co-developing next-generation systems and Ethernet solutions to power scalable, energy-efficient AI infrastructure by 2029.
OpenAI and Broadcom announce a multi-year partnership to deploy 10 gigawatts of OpenAI-designed AI accelerators, co-developing next-generation systems and Ethernet solutions to power scalable, energy-efficient AI infrastructure by 2029. Read More
What Is Your Agent’s GPA? A Framework for Evaluating Agent Goal-Plan-Action Alignmentcs.AI updates on arXiv.org arXiv:2510.08847v1 Announce Type: new
Abstract: We introduce the Agent GPA (Goal-Plan-Action) framework: an evaluation paradigm based on an agent’s operational loop of setting goals, devising plans, and executing actions. The framework includes five evaluation metrics: Goal Fulfillment, Logical Consistency, Execution Efficiency, Plan Quality, and Plan Adherence. Logical Consistency checks that an agent’s actions are consistent with its prior actions. Execution Efficiency checks whether the agent executes in the most efficient way to achieve its goal. Plan Quality checks whether an agent’s plans are aligned with its goals; Plan Adherence checks if an agent’s actions are aligned with its plan; and Goal Fulfillment checks that agent’s final outcomes match the stated goals. Our experimental results on two benchmark datasets – the public TRAIL/GAIA dataset and an internal dataset for a production-grade data agent – show that this framework (a) provides a systematic way to cover a broad range of agent failures, including all agent errors on the TRAIL/GAIA benchmark dataset; (b) supports LLM-judges that exhibit strong agreement with human annotation, covering 80% to over 95% errors; and (c) localizes errors with 86% agreement to enable targeted improvement of agent performance.
arXiv:2510.08847v1 Announce Type: new
Abstract: We introduce the Agent GPA (Goal-Plan-Action) framework: an evaluation paradigm based on an agent’s operational loop of setting goals, devising plans, and executing actions. The framework includes five evaluation metrics: Goal Fulfillment, Logical Consistency, Execution Efficiency, Plan Quality, and Plan Adherence. Logical Consistency checks that an agent’s actions are consistent with its prior actions. Execution Efficiency checks whether the agent executes in the most efficient way to achieve its goal. Plan Quality checks whether an agent’s plans are aligned with its goals; Plan Adherence checks if an agent’s actions are aligned with its plan; and Goal Fulfillment checks that agent’s final outcomes match the stated goals. Our experimental results on two benchmark datasets – the public TRAIL/GAIA dataset and an internal dataset for a production-grade data agent – show that this framework (a) provides a systematic way to cover a broad range of agent failures, including all agent errors on the TRAIL/GAIA benchmark dataset; (b) supports LLM-judges that exhibit strong agreement with human annotation, covering 80% to over 95% errors; and (c) localizes errors with 86% agreement to enable targeted improvement of agent performance. Read More
Barbarians at the Gate: How AI is Upending Systems Researchcs.AI updates on arXiv.org arXiv:2510.06189v3 Announce Type: replace
Abstract: Artificial Intelligence (AI) is starting to transform the research process as we know it by automating the discovery of new solutions. Given a task, the typical AI-driven approach is (i) to generate a set of diverse solutions, and then (ii) to verify these solutions and select one that solves the problem. Crucially, this approach assumes the existence of a reliable verifier, i.e., one that can accurately determine whether a solution solves the given problem. We argue that systems research, long focused on designing and evaluating new performance-oriented algorithms, is particularly well-suited for AI-driven solution discovery. This is because system performance problems naturally admit reliable verifiers: solutions are typically implemented in real systems or simulators, and verification reduces to running these software artifacts against predefined workloads and measuring performance. We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions. Using penEvolve, an existing open-source ADRS instance, we present case studies across diverse domains, including load balancing for multi-region cloud scheduling, Mixture-of-Experts inference, LLM-based SQL queries, and transaction scheduling. In multiple instances, ADRS discovers algorithms that outperform state-of-the-art human designs (e.g., achieving up to 5.0x runtime improvements or 50% cost reductions). We distill best practices for guiding algorithm evolution, from prompt design to evaluator construction, for existing frameworks. We then discuss the broader implications for the systems community: as AI assumes a central role in algorithm design, we argue that human researchers will increasingly focus on problem formulation and strategic guidance. Our results highlight both the disruptive potential and the urgent need to adapt systems research practices in the age of AI.
arXiv:2510.06189v3 Announce Type: replace
Abstract: Artificial Intelligence (AI) is starting to transform the research process as we know it by automating the discovery of new solutions. Given a task, the typical AI-driven approach is (i) to generate a set of diverse solutions, and then (ii) to verify these solutions and select one that solves the problem. Crucially, this approach assumes the existence of a reliable verifier, i.e., one that can accurately determine whether a solution solves the given problem. We argue that systems research, long focused on designing and evaluating new performance-oriented algorithms, is particularly well-suited for AI-driven solution discovery. This is because system performance problems naturally admit reliable verifiers: solutions are typically implemented in real systems or simulators, and verification reduces to running these software artifacts against predefined workloads and measuring performance. We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions. Using penEvolve, an existing open-source ADRS instance, we present case studies across diverse domains, including load balancing for multi-region cloud scheduling, Mixture-of-Experts inference, LLM-based SQL queries, and transaction scheduling. In multiple instances, ADRS discovers algorithms that outperform state-of-the-art human designs (e.g., achieving up to 5.0x runtime improvements or 50% cost reductions). We distill best practices for guiding algorithm evolution, from prompt design to evaluator construction, for existing frameworks. We then discuss the broader implications for the systems community: as AI assumes a central role in algorithm design, we argue that human researchers will increasingly focus on problem formulation and strategic guidance. Our results highlight both the disruptive potential and the urgent need to adapt systems research practices in the age of AI. Read More
Beyond Single-Granularity Prompts: A Multi-Scale Chain-of-Thought Prompt Learning for Graphcs.AI updates on arXiv.org arXiv:2510.09394v1 Announce Type: cross
Abstract: The “pre-train, prompt” paradigm, designed to bridge the gap between pre-training tasks and downstream objectives, has been extended from the NLP domain to the graph domain and has achieved remarkable progress. Current mainstream graph prompt-tuning methods modify input or output features using learnable prompt vectors. However, existing approaches are confined to single-granularity (e.g., node-level or subgraph-level) during prompt generation, overlooking the inherently multi-scale structural information in graph data, which limits the diversity of prompt semantics. To address this issue, we pioneer the integration of multi-scale information into graph prompt and propose a Multi-Scale Graph Chain-of-Thought (MSGCOT) prompting framework. Specifically, we design a lightweight, low-rank coarsening network to efficiently capture multi-scale structural features as hierarchical basis vectors for prompt generation. Subsequently, mimicking human cognition from coarse-to-fine granularity, we dynamically integrate multi-scale information at each reasoning step, forming a progressive coarse-to-fine prompt chain. Extensive experiments on eight benchmark datasets demonstrate that MSGCOT outperforms the state-of-the-art single-granularity graph prompt-tuning method, particularly in few-shot scenarios, showcasing superior performance.
arXiv:2510.09394v1 Announce Type: cross
Abstract: The “pre-train, prompt” paradigm, designed to bridge the gap between pre-training tasks and downstream objectives, has been extended from the NLP domain to the graph domain and has achieved remarkable progress. Current mainstream graph prompt-tuning methods modify input or output features using learnable prompt vectors. However, existing approaches are confined to single-granularity (e.g., node-level or subgraph-level) during prompt generation, overlooking the inherently multi-scale structural information in graph data, which limits the diversity of prompt semantics. To address this issue, we pioneer the integration of multi-scale information into graph prompt and propose a Multi-Scale Graph Chain-of-Thought (MSGCOT) prompting framework. Specifically, we design a lightweight, low-rank coarsening network to efficiently capture multi-scale structural features as hierarchical basis vectors for prompt generation. Subsequently, mimicking human cognition from coarse-to-fine granularity, we dynamically integrate multi-scale information at each reasoning step, forming a progressive coarse-to-fine prompt chain. Extensive experiments on eight benchmark datasets demonstrate that MSGCOT outperforms the state-of-the-art single-granularity graph prompt-tuning method, particularly in few-shot scenarios, showcasing superior performance. Read More